中科院&地平线开源state-of-the-art行人重识别算法EANet:增强跨域行人重识别中的部件对齐...
点击我爱计算机视觉标星,更快获取CVML新技术
编者按:前几天就看到这篇论文EANet,非常非常棒,有幸征得原作者同意授权“我爱计算机视觉”转载,感谢各位大佬的优秀工作~
最重要的是大家一定要收藏本文,还要去Github上给大佬加星!
本文介绍我们最新的工作EANet: Enhancing Alignment for Cross-Domain Person Re-identification

代码公布在:
https://github.com/huanghoujing/EANet
简介
单域(single-domain)的行人重识别(ReID)近来已经取得了巨大的进展,但是在跨域(cross domain,或者迁移,transfer)问题上却存在很大的困难,主要体现在:
(1)直接把训好的模型到目标域(target domain)测试,性能有巨大的下降;
(2)利用无id标注的目标域图片进行领域适应(domain adaptation)具有其挑战性。
这篇文章中,我们发现部件对齐在跨域重识别中起着重要的作用。
通过强化模型的对齐,我们一方面提高模型的泛化性能(generalization),提升模型直接跨库测试的性能;另一方面,我们的部件对齐模型可以很自然地利用目标域无标签数据,实现领域自适应(adaptation),使得模型可以适配目标域。
我们在Market1501,CUHK03,DukeMTMC-reID,MSMT17四个目前最大的行人重识别数据库之间进行大量的跨域实验,证明了我们方法的有效性,并且取得了state of the art的结果。同时,出于完整性,我们还实验证明了和现有跨域方法的互补性。
整体模型框图
 图1:模型的主要特点是部件对齐池化(PAP: Part Aligned Pooling)、每个部件的id约束、部件分割(PS: Part Segmentation)约束,并且在训练阶段同时利用源域(有id标注)和目标域(无id标注)的图片
图1:模型的主要特点是部件对齐池化(PAP: Part Aligned Pooling)、每个部件的id约束、部件分割(PS: Part Segmentation)约束,并且在训练阶段同时利用源域(有id标注)和目标域(无id标注)的图片
基于区域池化的ReID模型
ECCV18 state-of-the-art的工作PCB [1]给我们的启发是,提取局部区域的特征、并且每个区域都施加id约束,这样能够训练出判别性很强的模型。因此,我们也采用这种局部特征+每个区域id约束的方式。
部件对齐池化(PAP: Part Aligned Pooling)
 图2:(a)PCB池化的区域,(b)本文池化的区域,(c)本文使用的关键点
图2:(a)PCB池化的区域,(b)本文池化的区域,(c)本文使用的关键点
PCB的做法是在特征图上把一个图片均分成P块,如图2中(a)所示。显而易见,这种方式对于检测器的定位偏差是很不鲁棒的。我们的做法是根据关键点的位置(关键点检测模型在COCO上训练),将身体划分成P个区域,具体如图2(b)所示。我们最终的模型使用的是9个区域,如图1中左下角。在和PCB的对比实验中,出于公平,我们只使用R1~R6六个区域。
部件对齐池化后,所接的嵌入层、分类器、softmax loss的做法和PCB保持一致。
部件分割约束(PS Constraint)
我们采用局部区域池化的方式提取特征,初衷是从不同区域提取到不同的特征,对行人进行细粒度的表征。但是,我们发现不同区域提取出来的特征(特别是相邻区域)具有很高的相似度。
另外,我们还发现,把遮挡掉一半(上半部或下半部)的图片送进网络,基于部件的模型(PCB、我们的PAP)Conv5的特征在被遮挡区域仍有很大的响应。
我们猜测原因
(1)Conv5的神经元感受野超级大;
(2)每个部件的id约束非常强,从每个部件区域提取出来的特征必须具备足够多的信息才能满足id分类的约束。
因此,从一个部件区域池化得到的特征很可能表示好几个部件的特征。区域划分得越小,则每个区域的id约束越是加重了这个问题。
存在这个问题的模型,虽然也能提取到多个判别性很强的特征,但是我们觉得失去了定位能力的特征
(1)对于部件对齐的性能还是有折扣,
(2)不同区域得到的特征之间冗余度较高。
为了让模型从一个区域池化得到的特征尽量以这个区域为重点,降低部件之间的冗余度,我们在尝试了各种方法无果之后,提出在Conv5的特征图上施加部件分割的约束。
直觉解释是,如果从Conv5每个空间位置的特征可以区分出来其属于哪个部件类别,那么说明这些特征是具有部件区分性的。我们很简单地在Conv5的特征上加一个部件分割的小模块(Part Segmentation Head)来达到这个目的。PS模块由一个stride=2的3x3反卷积层和一个1x1的卷积层组成。为了得到部件分割的监督信号,我们在COCO上训练了一个部件分割模型,然后在ReID数据库上进行预测,得到部件伪标签,如图3所示。
 图3:(a)COCO上的部件标注(b)训好的分割模型在ReID数据库上预测的伪标签
图3:(a)COCO上的部件标注(b)训好的分割模型在ReID数据库上预测的伪标签
部件分割约束实现领域自适应
加了部件分割模块之后,我们的模型可以看成双流的多任务模型,我们自然而然可以想到把部件分割约束施加到无id标注的目标域图片上。
这样做的好处是,一方面模型见过目标域的图片,在训练阶段就能起到一定的领域适应的作用;另一方面,保证了模型在目标域图片提取特征时的定位和对齐。
多任务、多域训练
源域的图片可以同时进行ReID、部件分割训练,目标域图片只能进行部件分割训练。
训练阶段,我们的学习率、迭代次数、优化器等优化设置保持和单独训ReID的情况一致。
源域batch和目标域batch分开前传,但是源域ReID损失、分割损失的梯度,和目标域分割损失的梯度相加后再一起更新模型。
实验:部件对齐的作用
 表格1:部件对齐对跨域的作用
表格1:部件对齐对跨域的作用
我们对比PAP-6P和PCB,其中PAP-6P的训练和测试阶段都是在图1中R1~R6区域池化得到6个特征,其它训练、测试设定和PCB一致。PAP-6P和PCB在源库上性能相当,但是对跨库有很大的提升,比如在M->D上Rank-1提高了4.7个点。说明了对齐的特征提取对模型的泛化性能(generalization)有很大的帮助。
PAP在训练和测试阶段使用了图1中R1~R9共9个区域,PAP比PAP-6P在CUHK03上Rank-1有3.9%的提升。我们后续的实验都是基于PAP。
实验:部件分割约束的作用
 图4:部件之间的特征相似度
图4:部件之间的特征相似度
在PAP的基础上,增加部件分割约束的模型记为PAP-S-PS(模型只见过源域图片),对目标域和源域都施加分割约束的模型记为PAP-ST-PS。
我们把PCB、PAP、PAP-S-PS、PAP-ST-PS几个模型的部件特征cosine相似度(测试集上的统计值)计算出来,如图4。
我们看出,部件对齐的池化、部件分割约束都明显降低了部件之间特征的相似度。我们相信这也意味着降低了特征的冗余和混淆。
 表格2:部件分割约束的作用(PAP-S-PS-SA这一项得看论文具体解释)
表格2:部件分割约束的作用(PAP-S-PS-SA这一项得看论文具体解释)
PAP、PAP-S-PS、PAP-ST-PS三个模型的分数对比见表格2。
可以看出,PAP-S-PS比PAP在源域上有稍微提升,对跨域有很大提升,比如M->D的Rank-1提升了5个点。这体现了模型泛化性能(generalization)的提升。
另外,比较PAP-S-PS和PAP-ST-PS,我们看出对目标域图片的分割约束进一步提升了跨域性能,比如M->D的Rank-1,PAP-ST-PS比PAP-S-PS提升了4.7个点。这体现了目标域图片部件分割约束作为领域适应(adaptation)的有效性。
 图5:目标域部件分割约束的直观效果
图5:目标域部件分割约束的直观效果
从图5中,我们也可以看出目标域图片部件分割约束的直观效果。PAP-S-PS模型没有见过目标域图片,因此在目标域预测的分割结果有很多噪声、残缺,而PAP-ST-PS见过目标域图片,明显改善了这个问题。
实验:在MSMT17上训练
上面提到的实验,我们在MSMT17(目前最大的Image-based ReID数据集)上也进行了训练。可以得到和上面一致的结论。分数见表格3。
 表格3:在MSMT17上训练
表格3:在MSMT17上训练
实验:COCO提供的部件分割约束
 表格4:COCO提供的部件分割约束的作用
表格4:COCO提供的部件分割约束的作用
我们甚至尝试把COCO的部件分割约束加入到模型的训练中,其中一个考虑是COCO的部件标签是准确的。具体做法是,我们在训练PAP模型的时候,同时训练COCO图片的部件分割,但是不对ReID图片训练部件分割,模型记为PAP-C-PS。
因此模型优化的是ReID图片的ReID约束,以及COCO图片的分割约束。根据表格4,比较PAP、PAP-C-PS,我们发现COCO图片的加入降低了源库的性能,但是跨库的分数有非常大的提升,比如PAP-C-PS比PAP在M->D的Rank-1提升了7.9个点。
这说明了我们在实际应用中,甚至可以把公开的通用的部件分割数据库(如COCO、Pascal Part、LIP)作为模型训练的一部分数据,提升模型部件对齐的能力,这无疑是比较可喜的一点。
另外,如果想要让模型在加了COCO图片后,在源库和目标库都保持较高的性能,我们建议把COCO图片转换成ReID图片的风格,然后把原始COCO图片、新风格的COCO图片都加到模型训练中。我们把这个方法记为PAP-StC-PS,记录在表格4中。
实验:和现有跨域方法的互补性
现有跨域方法的主流做法包括(1)风格迁移。利用GAN把源域的图片转换成目标域的风格,然后在这些生成的图片上训练ReID模型。(2)预测伪标签(CFT: Clustering-and-FineTuning)。利用源域训好的ReID模型,在目标域上通过聚类、贴伪标签的方式得到伪监督训练数据,然后微调ReID模型。
(1)风格迁移的方法。ReID模型本身性能越好(只要求源域内测试性能高,不要求跨库性能高),则在风格化后的图片上训练ReID模型,自然能够得到更好的模型。然后,由于图片是目标域风格的,所以跨域性能自然更好。
(2)预测伪标签的方法。ReID模型的跨域性能越好,那么模型在目标域的初始状态越好,聚出来的类别越加纯净,越有利于模型的微调。
因此,从理论上来说,源域、跨域都更好的ReID模型,和这两种已有跨域方法就很自然地是互补的。出于完整性,我们也实验证明了和现有跨域方法SPGAN [2](Simon4Yan/Learning-via-Translation)、DomainAdaptiveReID [3](LcDog/DomainAdaptiveReID)的互补性。
注意,出于简单、清晰对比的考虑,我们只使用DomainAdaptiveReID中聚类的方法和阈值选择的方法,不采用re-ranking距离,也不采用随机擦除数据扩增,而且在目标域微调时,我们保持本文提出的模型结构,而不采用triplet loss微调。
实验分数如表格5所示。其中PCB-SPGAN、PAP-S-PS-SPGAN指的是,我们训练PCB、PAP-S-PS的时候,采用风格后的图片,这利用的是风格化的方法使得模型在训练阶段见过目标域的分布。
PAP-ST-PS-SPGAN表示训练PAP-ST-PS的时候,源域的图片用的是风格后的图片,这综合利用了“优化目标域图片分割约束”、“风格化”两种方法使得模型在训练阶段见过目标域的分布。
PAP-ST-PS-SPGAN-CFT指的是,利用训练好的PAP-ST-PS-SPGAN模型作为初始化,在目标域执行聚类、贴伪标签、监督训练的任务。
 表格5:和现有跨域方法的互补性
表格5:和现有跨域方法的互补性
根据表格5,(1)比较PAP-S-PS-SPGAN和PAP-ST-PS,前者是利用风格迁移让模型训练阶段见过目标域分布,后者是利用对目标域图片分割约束让模型见过目标域分布,可以看出两者性能相当。另外,当我们的方法和SPGAN结合时,分数提升很多。(2)我们没有做实验对比不同模型进行Clustering-and-FineTuning(CFT)的效果,只证明了我们的方法和CFT的互补性。
State-of-the-art的性能:单域
我们和state-of-the-art的单域方法(single-domain)性能比较如表格6,可以看出,我们的分数达到了state-of-the-art。
 表格6:单域的state of the art
表格6:单域的state of the art
State-of-the-art的性能:跨域
我们和state-of-the-art的跨域方法性能比较如表格7,可以看出,我们的分数也达到了state-of-the-art。
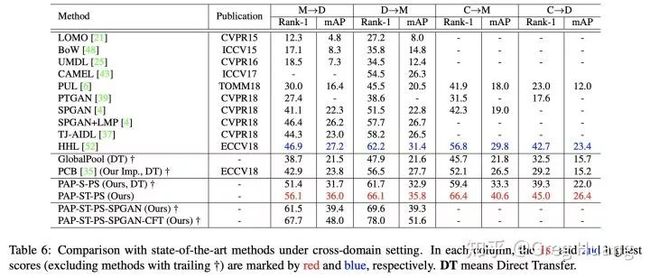 表格7:跨域的state of the art
表格7:跨域的state of the art
结论
本文主要验证了部件对齐在跨域ReID中的重要作用。我们提出的部件对齐池化、源域图片部件分割约束显著提高了模型的泛化性能(generalization),同时我们提出的目标域图片分割约束起到了有效的领域自适应作用(domain adaptation)。另外,和现有方法的互补性也得到了实验论证。
将来工作
(1)我们的实验证实了,部件分割和ReID是两个互相兼容的任务,因此下一步将考虑两个任务的共同训练,去掉对额外的分割模型的需求,提高效率。
(2)尝试利用部件分割结果来池化提取部件特征,去除关键点检测模型,提高效率。(3)我们的模型可以使得Conv5的特征保持定位能力,我们相信这对于更困难的问题:部分人ReID(Partial ReID)也具有很大的帮助,因此后续会在这个问题上进行更多的探索。
实现细节
我们所有模型的池化都是max pooling。ReID的数据扩充只有训练时的flipping。GlobalPool的embedding size是512,其它模型的embedding size是256。测试用的ReID特征是embedding输出的特征。(后续将会考虑warmup、triplet loss、cropping等)。更多细节见代码,以及文章。
代码
我们完备、规整的代码已经开源在:
https://github.com/huanghoujing/EANet
包括文章几乎所有的实验、数据、训练好的模型等。代码基于pytorch 1.0.0,同时具有较高的扩展性,欢迎读者的关注。希望阅读完此文的你能给我们一个star!
引用
[1] Y. Sun, L. Zheng, Y. Yang, Q. Tian, and S. Wang. Beyond part models: Person retrieval with refined part pooling. In ECCV, 2018.
[2] W. Deng, L. Zheng, G. Kang, Y. Yang, Q. Ye, and J. Jiao. Image-image domain adaptation with preserved selfsimilarity and domain-dissimilarity for person reidentification. In CVPR, 2018.
[3] L. Song, C. Wang, L. Zhang, B. Du, Q. Zhang, C. Huang, and X. Wang. Unsupervised domain adaptive re-identification: Theory and practice. arXiv, 2018.
开源地址
https://github.com/huanghoujing/EANet
加群交流
欢迎加入52CV-行人检测、行人重识别、步态识别等方向专业群,扫码添加52CV君拉你入群
(请务必注明:行人)

喜欢在QQ交流的童鞋,可以加52CV官方QQ群:928997753。
(不会时时在线,如果没能及时通过验证还请见谅)
更多技术干货,详见:
新年快乐!"我爱计算机视觉"干货集锦与新年展望
长按关注我爱计算机视觉

【点赞与转发】就是一种鼓励