利用pandas进行数据预处理
目录: 1.安装pandas
2.pandas的引入
3.数据清洗
①处理缺失数据
②检测和过滤异常值
③移除重复数据
4.数据集成
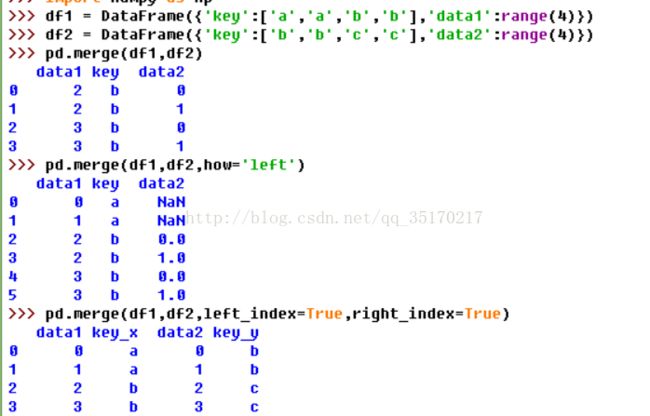
A.使用键参数的DataFrame合并
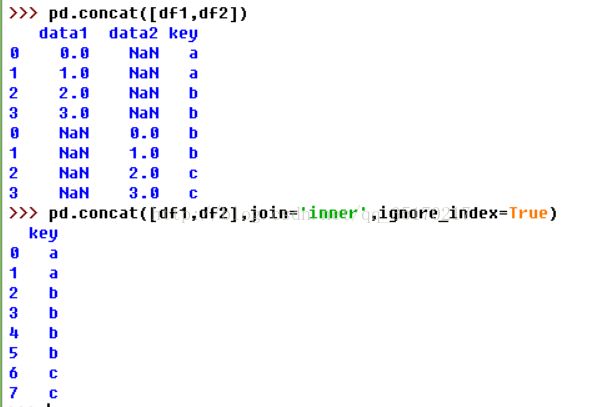
B.轴向连接
5.数据变换
A.利用函数或映射进行数据转换
B.替换值
C.重命名轴索引
D.离散化和面元
1.安装pandas
直接使用命令 pip install pandas 安装即可(我使用的是python3)。
2.pandas的引入
from pandas import Series,DataFrame
import pandas as pd
import numpy as np##DataFrame:二维的表格型数组结构。可将DataFrame理解为Series的容器
##########下面来看一下Series的应用:
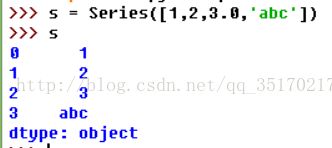
可以看出,Series包含一个数组的数据和一个与数组关联的数据标签,被叫做索引。Series是一个类似一维数组的对象。Series对象包含两个重要的属性:index和values。分别为上面的左右两列。

上面是在初始化的时候以关键字参数显示的指定一个index对象,Series对象的元素会严格依照给出的index构建。也就是说,如果data参数是有键值对的,那么只有index中含有的键会被使用;以及如果data中缺失相应的键,即使给出NaN(浮点值,表示浮点和非浮点数组中的缺失数据)值,这个键也会被添加。还有就是data与index要对应。
另外,Series对象和他的index都含有一个name属性:

########接下来看一下DataFrame
废话不多讲,直接上代码:
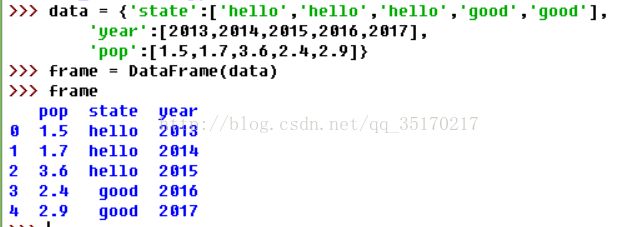
#如果你设定了一个列的顺序,DataFrame的列将会精确的按照你所传递的顺序排列:
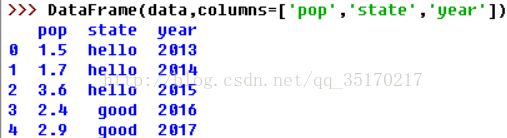
#如果你传递了一个行,但不包括在data中,在结果中他会表示为NA值:

#在DataFrame中的一列可以通过字典记法或属性来检索:

#也可以使用一些方法通过位置或名字来检索,这里我们使用ix索引:
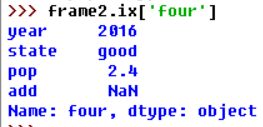
#对于列我们可以通过赋值来修改:
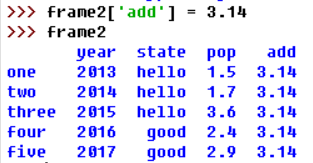
3.数据清洗
建议看这部内容时,把数据清洗搞清楚再返回来看。
①处理缺失数据

#python内置的None值也会被当做NA处理:
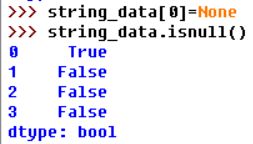
处理NA的方法有四种:
is(not)null:这一对方法对对象做元素级应用,然后返回一个bool型数组,一般可用于bool型索引。
dropna:对于一个Series.dropna返回一个仅含非空数据和索引值的Series。
fillna:fillna(value=None,method=None,axis=0)中的参数value除了基本类型外,还可以使用字典,这样可以实现对不同的列填充不同的值。
过滤掉缺失数据的办法有很多种。纯手工操作永远是一个办法,但dropna可能会更实用。对于一个Series,dropna返回一个仅含非空数据和索引值的Series。

而对于DataFrame对象,事情有点复杂。你可能希望丢弃全为NA或含有NA的行货列。dropna默认丢弃任何含有缺失值的行:
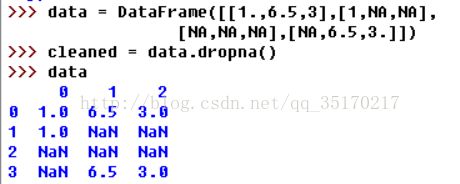

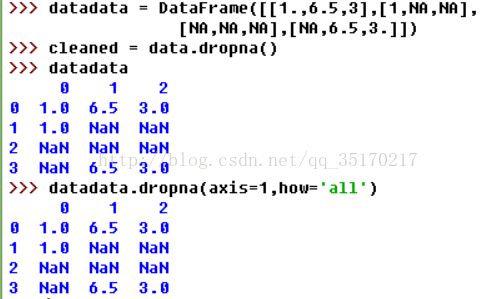
传入how将只会丢弃全为NA的那些行:

如果需要用这种方法丢弃列时,只需传入axis=1即可:
另一种去掉DataFrame行的问题设计时间序列数据。假设你只想留下一部分观测数据,可以用thresh参数实现此目的:
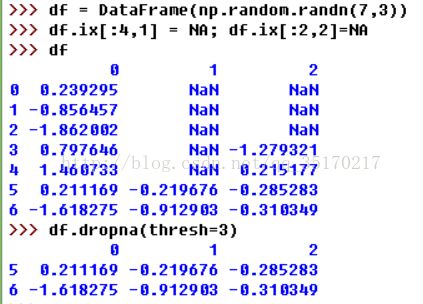
不想过滤缺失数据(有可能会丢弃跟他有关的其他数据),而是希望通过其他方式填补那些“空洞”。对于大多数情况而言,fillna方法是最主要的函数。通过一个常数调用fillna就会将缺失值替换为那个常数值:

若是通过一个字典调用fillna,就可以实现对不同的列填充不同的值:

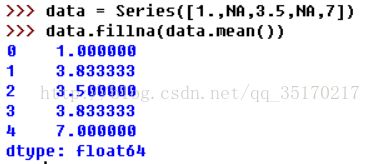
可以利用fillna实现许多别的功能。比如说,你可以传入Series的平均值或中位数:
②检测和过滤异常值
异常值的过滤或变换运算在很大程度上就是数组运算。如下一个(1000,4)的标准正态分布数组:

假设要找出某一列中绝对值大小超过3的项:
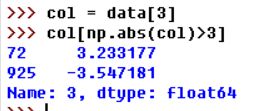
要选出全部含有“绝对值超过3的值”的行,可以利用布尔型索引和any方法:

③移除重复数据
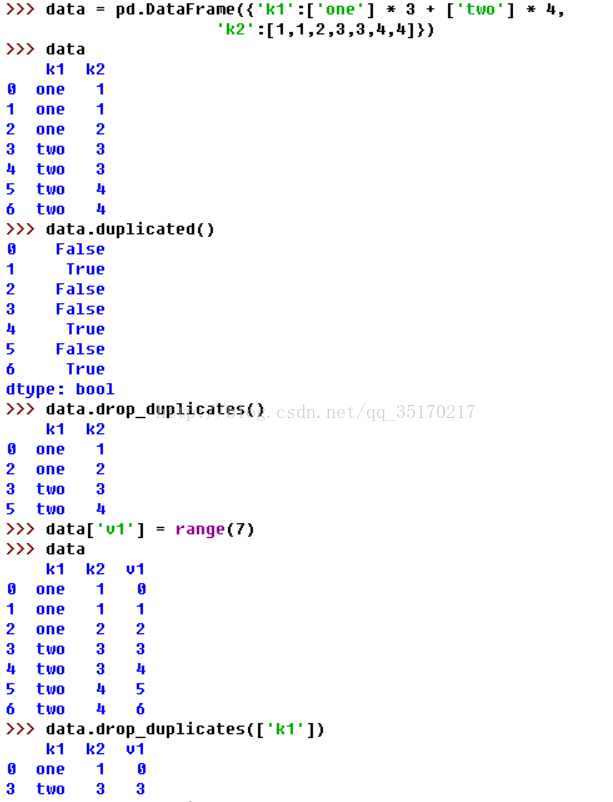
在DataFrame中往往会出现重复行,在DataFrame中的duplicated方法返回一个bool型Series,表示各行是否是重复行,还有一个与此相关的drop_duplicates方法,它用于返回一个移除了重复行的DataFrame。这两个方法默认会判断全部列,我们也可以指定部分列进行重复项判断。假设你还有一列值,且只希望根据k1列过滤重复项。duplicated和drop_duplicates默认保留的是第一个出现的值组合。传入take_last=True则保留最后一个,在python3中使用keep=‘last’。

4.数据集成
在python中,pandas,merge可以根据一个或多个键将不同DataFrame中的行连接起来;pandas.concat可以沿着一条轴将多个对象堆叠到一起;实例方法combine_first可以用一个对象中的值填充另一个对象中对应位置的缺失值。
A.使用键参数的DataFrame合并

让我们来看一下这些参数是什么意思。on=None用于显示指定列名(键名),如果该列在两个对象上的列名不同,则可以通过left_on=None,right_on=None来分别指定。或者想直接使用列索引作为连接键的话,就将left_index=False,right_index=False设为True。how=’inner’参数指的是当左右两个对象中存在不重合的键时,取结果的方式:inner代表交集,outer代表并集,left和right分别为取一边。suffixes=(‘_x’,’_y’)指的是当左右对象中存在除连接键外的同名列时,结果集中的区分方式,可以各加一个小尾巴。
B.轴向连接
merge算法是一种整合的话,轴向连接pd.concat()就是单纯的把两个表拼在一起,这个过程也被称为连接,绑定或堆叠。参数axis用于指定连接的轴向。本函数的全部参数为:
![]()
其中,objs就是需要连接的对象集合,一般是列表或字典;axis=0是连接轴向;join=‘outer’参数作用于当另一条轴的index不重叠的时候,只有‘inner’和‘outer’可选。
5.数据变换
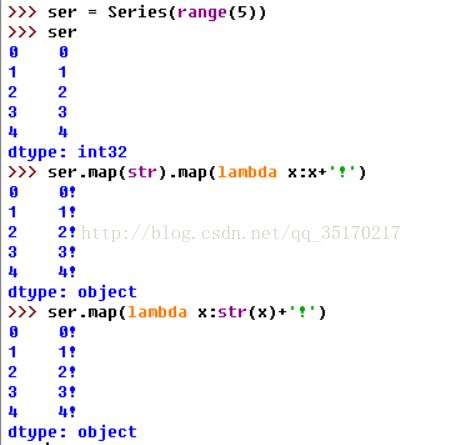
A.利用函数或映射进行数据转换
Series或DataFrame的列都可以调用有个.map()方法。该方法接受一个函数或字典作为参数,并将之应用于对象的每一个元素,最后返回一个包含所有结果的Series。
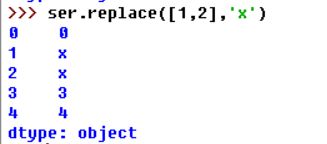
B.替换值
fillna方法填充缺失值可以看做值替换的一种特殊情况,map也可以用来修改对象的数据子集,而.replace(to_replace=None,value=None,inplace=False,limit=None,regex=False,method=’pad’,axis=None)方法则提供了实现该功能的一种更简单,更灵活的方式。
C.重命名轴索引
Pandas对象的index参数是不可变的,即不可以直接对其元素进行赋值操作。但你却可以对其使用obj.index.map()方法。
也可以直接对数组对象调用obj.rename(index=None,columns=None)方法。

跟Series一样,轴标签也有一个map方法:
![]()
可以将其赋值给index,这样就可以对DataFrame进行就地修改了:
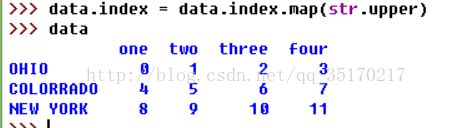
如果想要创建数据集的转换版(而不是修改原始数据),比较多使用的方式是rename:

D.离散化和面元
为了便于分析,连续数据常常被离散化或拆分为“面元”,假设有一组人员数据,而你希望将他们划分为不同的年龄组:
![]()
接下来将这些数据划分为‘18到25‘,‘26到35’,‘35到60’以及‘60以上’几个面元。要实现该功能,你需要使用Pandas的cut函数:

Pandas返回的是一个特殊的Categorical对象。你可以将其看作一组表示面元名称的字符串。实际上,它含有一个表示不同分类名称的levels数组以及一个为年龄数据进行标号的labels属性:

跟“区间”的数学符号一样,圆括号表示开端,而方括号则表示闭端。哪边是闭端可以通过right=False进行修改:

参考资料: 《python与数据科学》王仁武编著
《python核心编程》