基于PyTorch的mnist数据集的分类
基于PyTorch的mnist数据集的分类
- 简介
- 代码实现
- 1.相关包的导入
- 2.数据集加载及处理
- 3.加如LeNet模型及训练模型
- 4.准确率变化可视化
- 5.测试数据集及可视化预测结果
- 6.Build_LeNet_for_mnist.py
- 7.mnist_loader.py
- 结果展示
简介
这里本人选用LeNet的卷积神经网络结构实现分类,实验训练10个epoch准确率高达99%,测试集准确率达99%。实现代码中对LeNet网络模型进行了一点改动,且模型代码定义在Build_LeNet_for_mnist.py文件中,数据加载不是从网上下载的数据集,而是加载本地下载的数据集,其加载文件代码为mnist_loader.py,该文件是从pytorch的库文件torchvision.datasets.MNIST中改动的,需改动代码中的urls列表中的数据路径,如我的数据路径如代码中的file:///E:/PyCharmWorkSpace/Image_Set/mnist_data/train-images-idx3-ubyte.gz。代码在显卡上运行,网络中参数设置如代码中所示。
代码实现
1.相关包的导入
import torch
import mnist_loader
import Build_LeNet_for_mnist
import torch.nn.functional as F
import torch.optim as optim
from torchvision import transforms
import csv
import copy
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
2.数据集加载及处理
#加载数据集
use_cuda=torch.cuda.is_available()##检测显卡是否可用
batch_size=test_batch_size=32
kwargs={'num_workers':0,'pin_memory':True}if use_cuda else {}
#训练数据加载
train_loader = torch.utils.data.DataLoader(
mnist_loader.MNIST('./mnist_data',
train=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])), # 第一个参数dataset:数据集
batch_size=batch_size,
shuffle=True, # 随机打乱数据
**kwargs) ##kwargs是上面gpu的设置
#测试数据加载
test_loader = torch.utils.data.DataLoader(
mnist_loader.MNIST('./mnist_data',
train=False, # 如果False,从test.pt创建数据集
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=test_batch_size,
shuffle=True,
**kwargs)
3.加如LeNet模型及训练模型
#加入神经网络及参数设置
learning_rate=0.01
momentum=0.9
device = torch.device("cuda" if use_cuda else "cpu")
model=Build_LeNet_for_mnist.LeNet(1, 10).to(device)#加载模型
optimizer=optim.SGD(model.parameters(),lr=learning_rate,momentum=momentum)#优化器选择
#创建csv文件
csvFile = open("log.csv", "a+")
writer = csv.writer(csvFile) #创建写的对象
last_epoch=0
if os.path.exists("cifar10_cnn.pt"):
print("load pretrain")
model.load_state_dict(torch.load("cifar10_cnn.pt"))
data = pd.read_csv('log.csv')
e = data['epoch']
last_epoch=e[len(e)-1]
else:
print("first train")
#先写入columns_name
writer.writerow(["epoch","acc","loss"])
#训练函数
def train(model, device, train_loader, optimizer, last_epoch,epochs):
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.
print("Train from Epoch: {}".format(last_epoch+1))
model.train() # 进入训练模式
for epoch in range(1+last_epoch, epochs + 1+last_epoch):
correct = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
acc=100. * correct / len(train_loader.dataset)
print("Train Epoch: {} Accuracy:{:0f}%\tLoss: {:.6f}".format(
epoch,
acc,
loss.item()
))
if acc > best_acc:
best_acc = acc
best_model_wts = copy.deepcopy(model.state_dict())
#print(model.state_dict())
writer.writerow([epoch,acc/100,loss.item()])
return(best_model_wts)
#开始训练和测试
epochs = 10
best_model_wts=train(model, device, train_loader, optimizer,last_epoch, epochs)
csvFile.close()
#保存训练模型
save_model = True
if (save_model):
torch.save(best_model_wts,"mnist_LeNet.pt")
#词典格式,model.state_dict()只保存模型参数
4.准确率变化可视化
#可视化准确率
data = pd.read_csv('log.csv')
epoch = data['epoch']
acc = data['acc']
loss = data['loss']
fig=plt.gcf()
fig.set_size_inches(10,4)
plt.title("Accuracy&Loss")
plt.xlabel("Training Epochs")
plt.ylabel("Value")
plt.plot(epoch,acc,label="Accuracy")
#plt.plot(epoch,loss,label="Loss")
plt.ylim((0,1.))
plt.xticks(np.arange(1, len(epoch+1), 1.0))
plt.yticks(np.arange(0, 1.5, 0.2))
plt.legend()
plt.show()
5.测试数据集及可视化预测结果
def test(model, device, test_loader):
model.eval() # 进入测试模式
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.argmax(dim=1, keepdim=True)
data_record=data[0:10]
pred_record=pred.view_as(target)[0:10].cpu().numpy()
target_record=target[0:10].cpu().numpy()
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
return data_record,pred_record,target_record
data_record,pred_record,target_record=test(model, device, test_loader)
#可视化测试分类结果
#unloader = transforms.ToPILImage()
label_dict={0:"0",1:"1",2:"2",3:"3",4:"4",5:"5",6:"6",7:"7",8:"8",9:"9"}
def plot_images_labels_prediction(images,labels,prediction,idx,num=10):
fig=plt.gcf()
fig.set_size_inches(12,6)
if num>10:
num=10
for i in range(0,num):
image = images[idx].cpu().clone()
image = image.squeeze(0)
#image = unloader(image)
ax=plt.subplot(2,5,1+i)
ax.imshow(image,cmap="binary")
title=label_dict[labels[idx]]
if len(prediction)>0:
title+="=>"+label_dict[prediction[idx]]
ax.set_title(title,fontsize=10)
idx+=1
plt.show()
plot_images_labels_prediction(data_record,target_record,pred_record,0,10)
6.Build_LeNet_for_mnist.py
import torch.nn as nn
import torch.nn.functional as F
#建立神经网络
class LeNet(nn.Module):
def __init__(self,channel,classes):
super(LeNet, self).__init__()
self.conv1=nn.Conv2d(channel,32,5,1)
self.conv2=nn.Conv2d(32,64,5,1)
self.fc1=nn.Linear(4*4*64,512)
self.fc2=nn.Linear(512,classes)
def forward(self,x):
x=F.relu(self.conv1(x))
x=F.max_pool2d(x,2,2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4*4*64)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
7.mnist_loader.py
from __future__ import print_function
import torch.utils.data as data
from PIL import Image
import os
import os.path
import torch
class MNIST(data.Dataset):
urls = [
'file:///E:/PyCharmWorkSpace/Image_Set/mnist_data/train-images-idx3-ubyte.gz',
'file:///E:/PyCharmWorkSpace/Image_Set/mnist_data/train-labels-idx1-ubyte.gz',
'file:///E:/PyCharmWorkSpace/Image_Set/mnist_data/t10k-images-idx3-ubyte.gz',
'file:///E:/PyCharmWorkSpace/Image_Set/mnist_data/t10k-labels-idx1-ubyte.gz',
]
raw_folder = 'raw'
processed_folder = 'processed'
training_file = 'training.pt'
test_file = 'test.pt'
def __init__(self, root, train=True, transform=None, target_transform=None):
self.root = os.path.expanduser(root)
self.transform = transform
self.target_transform = target_transform
self.train = train # training set or test set
if not self._check_exists():
raise RuntimeError('Dataset not found.' +
' You can use download=True to download it')
if self.train:
self.train_data, self.train_labels = torch.load(
os.path.join(self.root, self.processed_folder, self.training_file))
else:
self.test_data, self.test_labels = torch.load(
os.path.join(self.root, self.processed_folder, self.test_file))
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is index of the target class.
"""
if self.train:
img, target = self.train_data[index], self.train_labels[index]
else:
img, target = self.test_data[index], self.test_labels[index]
# doing this so that it is consistent with all other datasets
# to return a PIL Image
img = Image.fromarray(img.numpy(), mode='L')
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
def __len__(self):
if self.train:
return len(self.train_data)
else:
return len(self.test_data)
def _check_exists(self):
return os.path.exists(os.path.join(self.root, self.processed_folder, self.training_file)) and \
os.path.exists(os.path.join(self.root, self.processed_folder, self.test_file))
结果展示
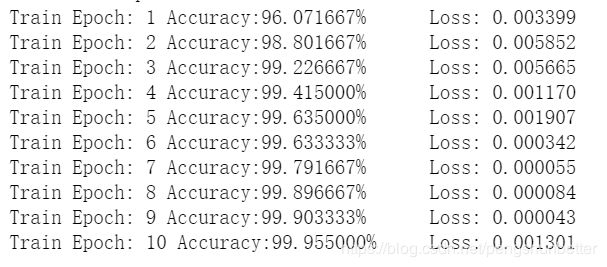
准确率变化图效果
测试数据集准确率及预测结果图
