《利用python进行数据分析》读书笔记之时间序列(二)
时间序列(二)
- 时间区间和时间算数
- 区间频率转换
- 季度区间频率
- 时间戳与时间区间的相互转换
- 从数组生成PeriodIndex
- 重新采样与频率转换:
- 向下采样
- 开端-峰值-谷值-结束(OHLC)重新采样
- 向上插值和采样
- 使用区间进行重新采样
- 移动窗口函数
- 指数加权函数
- 二元移动窗口函数
- 用户自定义的移动窗口函数
本文中可能使用的数据集来自: 《利用python进行数据分析》数据集
时间区间和时间算数
时间区间表示的是一个时间范围,如从2007年1月1日到2007年12月31日就是一个时间区间。pandas中包含一个Period类,用于表示时间区间。
可以使用以下语句来创建一个Period对象:
p1 = pd.Period("2007",'A-DEC')
#表示2007年1月1日到2007年12月31日,A-DEC表示12月份的最后一个工作日
p2 = pd.Period("2020","A-JUN")
#表示2019年7月1日到2020年6月30日,A-JUN表示6月份的最后一个工作日
对Period对象进行加减可以轻松的对时间区间进行移位,如果是两个相同单位的时间区间相减,则会得到它们之间差的单位数。
使用pd.period_range函数则可以构造一个时间区间的序列:
rng = pd.period_range("2001-01-01","2001-6-30",freq="M")
print(rng)
# PeriodIndex(['2001-01', '2001-02', '2001-03', '2001-04', '2001-05', '2001-06'], dtype='period[M]', freq='M')
区间频率转换
对于一个年度区间,我们可以使用asfreq方法转换为月度区间:
p = pd.Period("2020","A-JUN")
#表示2019年7月1日到2020年6月30日,A-JUN表示6月份的最后一个工作日
p1 = p.asfreq("M","start")
#代表p第一个月,即2019年6月这个时间范围
print(p1)
# 2019-07
p2 = p.asfreq("M","end")
#代表p最后一个月,即2020年6月这个时间范围
print(p2)
# 2020-06
我们也可以将月度区间转换为年度区间:
p = pd.Period("2007-08","M")
#代表2007年8月这个时间段
p1 = p.asfreq("A-JUN")
#会自动根据子区间所属的范围来确定年度区间
print(p1)
# 2008 表示2007年7月到2008年6月
对一一个以一系列PeriodIndex作为索引的DataFrame或者Series对象来说,其也包含着asfreq方法,来方便的对索引进行转换:
rng = pd.period_range("2006","2009",freq="A-DEC")
print(rng)
# PeriodIndex(['2006', '2007', '2008', '2009'], dtype='period[A-DEC]', freq='A-DEC')
ts = pd.Series(np.random.rand(len(rng)),index=rng)
print(ts)
# PeriodIndex(['2006', '2007', '2008', '2009'], dtype='period[A-DEC]', freq='A-DEC')
# 2006 0.984073
# 2007 0.075052
# 2008 0.207786
# 2009 0.297224
# Freq: A-DEC, dtype: float64
print(ts.asfreq("M",how="start"))
# 2006-01 0.984073
# 2007-01 0.075052
# 2008-01 0.207786
# 2009-01 0.297224
# Freq: M, dtype: float64
季度区间频率
在金融领域中,时间区间往往使用的的是季度(3个月),在pandas中我们可以方便的创建以季度为单位的时间区间:
p = pd.Period("2012Q2",freq="Q-JAN")
#表示2011年11月到2012年1月(3个月,即一个季度),"Q-JAN表示一个边界,即1月
#2012Q4表示以2011年1月为边界的第4个季度,即2012Q3贼代表2011-7到2011-10,2012Q2代表2011-4到2011-6,
#2012Q1代表2011-1到2011-3
当然我们可以对其进行频率的转换:
print(p.asfreq("D","start"))
# 2011-11-01
我们也可生成一个指定的季度序列:
rng = pd.period_range("2011Q3","2012Q4",freq="Q-JAN")
#表示以1月为起点,2011年的第三个季度到2012年第四个区间所包含的季度
ts = pd.Series(np.random.randn(len(rng)),index=rng)
print(ts)
# 2011Q3 0.471435
# 2011Q4 -1.190976
# 2012Q1 1.432707
# 2012Q2 -0.312652
# 2012Q3 -0.720589
# 2012Q4 0.887163
# Freq: Q-JAN, dtype: float64
时间戳与时间区间的相互转换
对于一个以时间戳序列为索引的Sereis或者DataFrame对象可以使用to_period方法来将其索引转换为时间区间:
rng = pd.date_range("2000-01-01",periods=3,freq="M")
ts = pd.Series(np.random.rand(len(rng)),index=rng)
print(ts)
# 2000-01-31 0.191519
# 2000-02-29 0.622109
# 2000-03-31 0.437728
# Freq: M, dtype: float64
pts = ts.to_period()
print(pts)
# 2000-01 0.191519
# 2000-02 0.622109
# 2000-03 0.437728
# Freq: M, dtype: float64
在转换时默认的使用相同的频率,对于上个例子则都是使用的月为频率。当然我们还可以自己指定时间区间的频率,此时有可能出现重复的区间:
rng2 = pd.date_range("2000-01-01",periods=3,freq="D")
ts2 = pd.Series(np.random.rand(len(rng2)),index=rng2)
print(ts2)
# 2000-01-01 0.191519
# 2000-01-02 0.622109
# 2000-01-03 0.437728
# Freq: D, dtype: float64
print(ts2.to_period("M"))
# 2000-01 0.191519
# 2000-01 0.622109
# 2000-01 0.437728
# Freq: M, dtype: float64
使用to_stamp则可以转换为时间戳:
pts = ts2.to_period()
print(pts)
# 2000-01-01 0.191519
# 2000-01-02 0.622109
# 2000-01-03 0.437728
# Freq: D, dtype: float64
print(pts.to_timestamp(how="end"))
# 2000-01-01 23:59:59.999999999 0.191519
# 2000-01-02 23:59:59.999999999 0.622109
# 2000-01-03 23:59:59.999999999 0.437728
# Freq: D, dtype: float64
从数组生成PeriodIndex
我们在处理数据时,数据集中的时间戳往往是作为DataFrame的数据而非索引,比如我们在文章开头中给出的数据集macrodata.csv为例:
data = pd.read_csv("../pydata-book-2nd-edition/examples/macrodata.csv")
print(data.head())
# year quarter realgdp realcons ... unemp pop infl realint
# 0 1959.0 1.0 2710.349 1707.4 ... 5.8 177.146 0.00 0.00
# 1 1959.0 2.0 2778.801 1733.7 ... 5.1 177.830 2.34 0.74
# 2 1959.0 3.0 2775.488 1751.8 ... 5.3 178.657 2.74 1.09
# 3 1959.0 4.0 2785.204 1753.7 ... 5.6 179.386 0.27 4.06
# 4 1960.0 1.0 2847.699 1770.5 ... 5.2 180.007 2.31 1.19
#
# [5 rows x 14 columns]
其中year为年份,quarter代表季度,那么如何将两者合并并将其作为data的索引呢?我们可以先初始化一个PeriodIndex对象,然后将其作为data的index属性,具体代码如下:
index = pd.PeriodIndex(year=data.year,quarter=data.quarter,freq="Q-DEC")
print(index)
# PeriodIndex(['1959Q1', '1959Q2', '1959Q3', '1959Q4', '1960Q1', '1960Q2',
# '1960Q3', '1960Q4', '1961Q1', '1961Q2',
# ...
# '2007Q2', '2007Q3', '2007Q4', '2008Q1', '2008Q2', '2008Q3',
# '2008Q4', '2009Q1', '2009Q2', '2009Q3'],
# dtype='period[Q-DEC]', length=203, freq='Q-DEC')
data.index = index
print(data.head())
# year quarter realgdp realcons ... unemp pop infl realint
# 1959Q1 1959.0 1.0 2710.349 1707.4 ... 5.8 177.146 0.00 0.00
# 1959Q2 1959.0 2.0 2778.801 1733.7 ... 5.1 177.830 2.34 0.74
# 1959Q3 1959.0 3.0 2775.488 1751.8 ... 5.3 178.657 2.74 1.09
# 1959Q4 1959.0 4.0 2785.204 1753.7 ... 5.6 179.386 0.27 4.06
# 1960Q1 1960.0 1.0 2847.699 1770.5 ... 5.2 180.007 2.31 1.19
#
# [5 rows x 14 columns]
重新采样与频率转换:
重新采样指的是将时间序列从一个频率转化为另一个频率的过程。将更高频率的数据集合聚合为较低频率的数据集合称为向下采样,而从低频率转换到高频率称为向上采样。
pandas对象配有resample方法,类似于group方法,可以使用对其进行分组,之后在进行聚合,比如现在我们有一个以天为频率的时间戳序列作为索引的Series对象:
rng = pd.date_range("2000-01-01",periods=100,freq="D")
ts = pd.Series(np.random.randn(len(rng)),index=rng)
print(ts.head())
# 2000-01-01 -0.804458
# 2000-01-02 0.320932
# 2000-01-03 -0.025483
# 2000-01-04 0.644324
# 2000-01-05 -0.300797
# Freq: D, dtype: float64
我们可以使用resample方法对其进行按月分组,之后求出每个月的平均值:
res1 = ts.resample("M").mean()
print(res1)
# 2000-01-31 0.042300
# 2000-02-29 0.041139
# 2000-03-31 0.007310
# 2000-04-30 0.329228
# Freq: M, dtype: float64
res2 = ts.resample("M",kind="period").mean()
#将其分组后转化为时间区间
print(res2)
# 2000-01 0.042300
# 2000-02 0.041139
# 2000-03 0.007310
# 2000-04 0.329228
# Freq: M, dtype: float64
resample方法的参数见下表:
| 参数 | 描述 |
|---|---|
| freq | 表示采样的频率或者dateOffset对象(如“M”,“5min”,“Second(1)”) |
| axis | 需要采样的轴向,默认是0 |
| fill_method | 向上采样的方式,fill或者bfill,默认是不插值的 |
| closed | 向下采样中,每段间隔是左封闭还是右封闭(包含),'right’或者’left ’ |
| label | 向下采样中,如何用’right’或’left’的箱标签标记聚合结果(一如9:30-9:35可以表示为9:30段或者9:35段) |
| loffset | 对箱标进行调校,如’-1s’/Second(-1)可以将聚合标签向前移动一秒 |
| limit | 在向前或者向后填充时,填充区间的最大值 |
| kind | 将索引转化为时间区间(period)或者时间戳(timestamp) |
| convention | 再怼区间重新采样的时候,用于将向上采样时的约定(“start”或“end”),默认为“end” |
向下采样
将更高频率的数据集合聚合为较低频率的数据集合称为向下采样,比如我们有一组数据,其索引为以天为频率的时间戳序列,我们通过向下采样可以将其按月进行分组以方便之后的处理,向下采样的时候需要考虑两个因素:
- 每段间隔哪边是闭合的
- 如何在间隔的起始或者结束位置标记每个已经聚合的箱体
假设现在我们拥有以下这个数据集:
rng = pd.date_range("2000-01-01",periods=12,freq="T")
ts = pd.Series(np.random.randn(len(rng)),index=rng)
print(ts)
# 2000-01-01 00:00:00 -0.804458
# 2000-01-01 00:01:00 0.320932
# 2000-01-01 00:02:00 -0.025483
# 2000-01-01 00:03:00 0.644324
# 2000-01-01 00:04:00 -0.300797
# 2000-01-01 00:05:00 0.389475
# 2000-01-01 00:06:00 -0.107437
# 2000-01-01 00:07:00 -0.479983
# 2000-01-01 00:08:00 0.595036
# 2000-01-01 00:09:00 -0.464668
# 2000-01-01 00:10:00 0.667281
# 2000-01-01 00:11:00 -0.806116
# Freq: T, dtype: float64
现在我们以5分钟为频率,对数据进行重新采样,并通过sum()方法进行聚合:
print(ts.resample("5min",closed="right").sum())
# 1999-12-31 23:55:00 -0.804458
# 2000-01-01 00:00:00 1.028450
# 2000-01-01 00:05:00 0.210229
# 2000-01-01 00:10:00 -0.806116
# Freq: 5T, dtype: float64
可以看出,箱体大小和我们设置的一样,为5分钟。默认情况下是包含箱体的左区间的(即左闭右开,0:00是包含在0:00-0:05内的),close=“right”则将其变为了左开右闭的区间。
另外,label参数则可以指定箱子的名称,“left”(默认)代表以左箱边作为名称,“right”则代表以右箱边作为箱子的名称:
print(ts.resample("5min",closed="right",label="right").sum())
# 2000-01-01 00:00:00 -0.804458
# 2000-01-01 00:05:00 1.028450
# 2000-01-01 00:10:00 0.210229
# 2000-01-01 00:15:00 -0.806116
# Freq: 5T, dtype: float64
之后我们在重新采样的过程中可能需要对时间索引进行一定的偏移,可以使用loffset选项来实现:
print(ts.resample("5min",closed="right",label="right",loffset="-1s").sum())
# 1999-12-31 23:59:59 -0.804458
# 2000-01-01 00:04:59 1.028450
# 2000-01-01 00:09:59 0.210229
# 2000-01-01 00:14:59 -0.806116
# Freq: 5T, dtype: float64
开端-峰值-谷值-结束(OHLC)重新采样
对重新采样的数据一种常用的方法是ohlc()方法,其可以显示第一个值,最大值、最小值和最后一个值:
print(ts.resample("5min").ohlc())
# open high low close
# 2000-01-01 00:00:00 -0.804458 0.644324 -0.804458 -0.300797
# 2000-01-01 00:05:00 0.389475 0.595036 -0.479983 -0.464668
# 2000-01-01 00:10:00 0.667281 0.667281 -0.806116 -0.806116
向上插值和采样
当进行向上采样时,并不需要进行数据的聚合。考虑下面这个DataFrame:
frame = pd.DataFrame(np.random.randn(2,4),
index=pd.date_range("2011-01-01",periods=2,freq="W-WED"),
columns=["C",'T','NY','O'])
#频率为每周三取一次
print(frame)
# C T NY O
# 2011-01-05 -0.804458 0.320932 -0.025483 0.644324
# 2011-01-12 -0.300797 0.389475 -0.107437 -0.479983
当我们对其进行向上采样的时候会产生缺失值,另外我们使用asfreq方法使其在不聚合的情况下转换到高频率:
df_daily = frame.resample("D").asfreq()
print(df_daily)
# C T NY O
# 2011-01-05 -0.804458 0.320932 -0.025483 0.644324
# 2011-01-06 NaN NaN NaN NaN
# 2011-01-07 NaN NaN NaN NaN
# 2011-01-08 NaN NaN NaN NaN
# 2011-01-09 NaN NaN NaN NaN
# 2011-01-10 NaN NaN NaN NaN
# 2011-01-11 NaN NaN NaN NaN
# 2011-01-12 -0.300797 0.389475 -0.107437 -0.479983
我们可以使用ffill方法和bfill方法来进行插值:
df_daily = frame.resample("D").ffill(limit=3)
#向后填充3行
print(df_daily)
# C T NY O
# 2011-01-05 -0.804458 0.320932 -0.025483 0.644324
# 2011-01-06 -0.804458 0.320932 -0.025483 0.644324
# 2011-01-07 -0.804458 0.320932 -0.025483 0.644324
# 2011-01-08 -0.804458 0.320932 -0.025483 0.644324
# 2011-01-09 NaN NaN NaN NaN
# 2011-01-10 NaN NaN NaN NaN
# 2011-01-11 NaN NaN NaN NaN
# 2011-01-12 -0.300797 0.389475 -0.107437 -0.479983
使用区间进行重新采样
先考虑下列DataFrame对象:
frame = pd.DataFrame(np.random.randn(24,4),
index=pd.period_range("2000-1","2001-12",freq="M"),
columns=["C",'T','NY','O'])
#频率为月
print(frame.head())
# C T NY O
# 2000-01 -0.804458 0.320932 -0.025483 0.644324
# 2000-02 -0.300797 0.389475 -0.107437 -0.479983
# 2000-03 0.595036 -0.464668 0.667281 -0.806116
# 2000-04 -1.196070 -0.405960 -0.182377 0.103193
# 2000-05 -0.138422 0.705692 1.271795 -0.986747
这个对象的以时间区间序列作为索引,在进行向下采样的时候,与时间戳向下采样类似:
annual_frame = frame.resample("A-DEC").mean()
#向下采样,频率为以一月为开始的年度
print(annual_frame)
# C T NY O
# 2000 -0.436109 0.285311 0.147154 0.196335
# 2001 -0.719742 -0.207392 0.202287 0.696853
对于向上采样,则类似于asfreq方法,需要将convention设置为“start”(默认)或者“end”:
print(annual_frame.resample("Q-DEC").ffill())
#表示12月为年末的季度。默认为start,即以数据中第一个年的第一个季度为起始
# C T NY O
# 2000Q1 -0.436109 0.285311 0.147154 0.196335
# 2000Q2 -0.436109 0.285311 0.147154 0.196335
# 2000Q3 -0.436109 0.285311 0.147154 0.196335
# 2000Q4 -0.436109 0.285311 0.147154 0.196335
# 2001Q1 -0.719742 -0.207392 0.202287 0.696853
# 2001Q2 -0.719742 -0.207392 0.202287 0.696853
# 2001Q3 -0.719742 -0.207392 0.202287 0.696853
# 2001Q4 -0.719742 -0.207392 0.202287 0.696853
print(annual_frame.resample("Q-DEC",convention="end").ffill())
# 即以数据中第一个年的第四个季度为起始
# C T NY O
# 2000Q4 -0.436109 0.285311 0.147154 0.196335
# 2001Q1 -0.436109 0.285311 0.147154 0.196335
# 2001Q2 -0.436109 0.285311 0.147154 0.196335
# 2001Q3 -0.436109 0.285311 0.147154 0.196335
# 2001Q4 -0.719742 -0.207392 0.202287 0.696853
需要注意的是相比于时间戳,时间区间的采样条件更加严格:
- 向下采样中,目标频率必须是原频率的子区间
- 向上采样中,目标频率必须是原频率的父区间
移动窗口函数
移动窗口函数可以方便的对粗糙的数据进行平滑。那么什么是移动窗口函数呢?我的理解是这样的,假设我们现在有一组数字序列,1,2,1,3,4,5,6,7……我们可以使用一个大小为3的窗口对其进行取平均值来达到平滑的目的,过程如下:
- 窗口大小为3,那么最后开始窗口内的数字就是1,2,1,,取平均值,为1.33,这是第一个结果
- 之后窗口向后滑动一格,2,1,3,平均值为2,这是第二个结果
- 依次类推,从开始一直滑动直到结束,得到的结果序列则就是平滑后的结果。
类似于上面介绍的原理的函数都可以称作移动窗口函数。为了更加直观的理解,我们以文章开头给出的数据集来进行演示:
close_px_all = pd.read_csv("../pydata-book-2nd-edition/examples/stock_px_2.csv",
parse_dates=True,
index_col=0)
close_px = close_px_all[["AAPL","MSFT","XOM"]]
close_px = close_px.resample("B").ffill()
#去掉休息日
print(close_px.head())
# AAPL MSFT XOM
# 2003-01-02 7.40 21.11 29.22
# 2003-01-03 7.45 21.14 29.24
# 2003-01-06 7.45 21.52 29.96
# 2003-01-07 7.43 21.93 28.95
# 2003-01-08 7.28 21.31 28.83
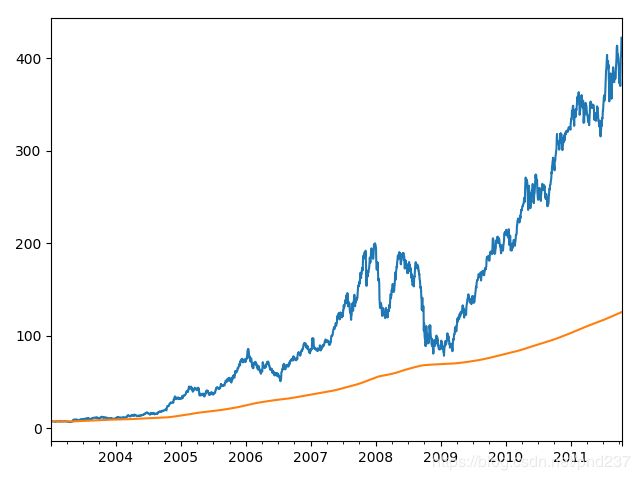
首先介绍的是rolling算子,可以理解为一个在时间上滑动的窗口,出入的参数为窗口大小,我们可以给这个窗口内的数值取平均值以达到平滑数据的效果:
close_px.AAPL.plot()
close_px.AAPL.rolling(250).mean().plot()
结果如下图,黄色为平滑后的曲线:

之后是expanding算子,该算子可以看做一个扩展的窗口,最开始窗口为1,聚合一次之后,窗口位置不懂,但是大小增加1,直到窗口的覆盖整个序列:
close_px.AAPL.plot()
close_px.AAPL.expanding().mean().plot()
结果如下:
rolling算子还可以接受表示固定时间大小的偏置字符串,如“20D”,可以来计算20天的滚动平均值。
指数加权函数
使用ewm算子可以计算指数加权平均值的计算,具体的说来,就是更近观测的数值具有更高的权重,对于ewm指定权重的方式即指定跨度(span),其具体的原理如下:

原理参考:移动窗口函数
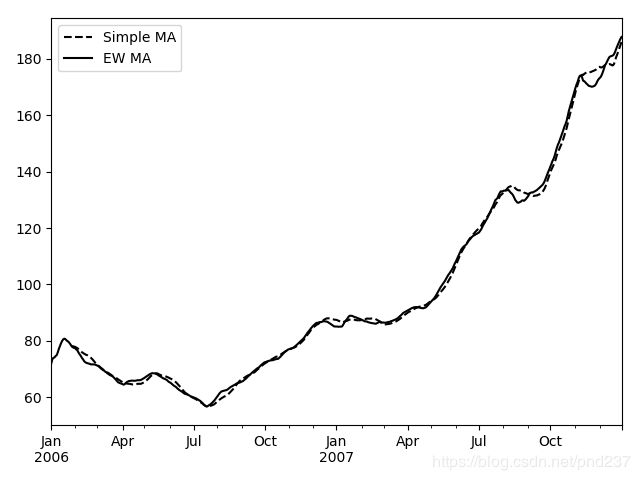
由于给近期的观测值更高的权重,与等权重相比,它对变化适应的更快,下面是一个例子:
appl_px = close_px.AAPL["2006":"2007"]
ma60 = appl_px.rolling(30,min_periods=20).mean()
#简单易懂平均
ewma60 = appl_px.ewm(span=30).mean()
#指数加权平均
ma60.plot(style="k--",label="Simple MA")
ewma60.plot(style="k-",label="EW MA")
plt.legend()
plt.show()
二元移动窗口函数
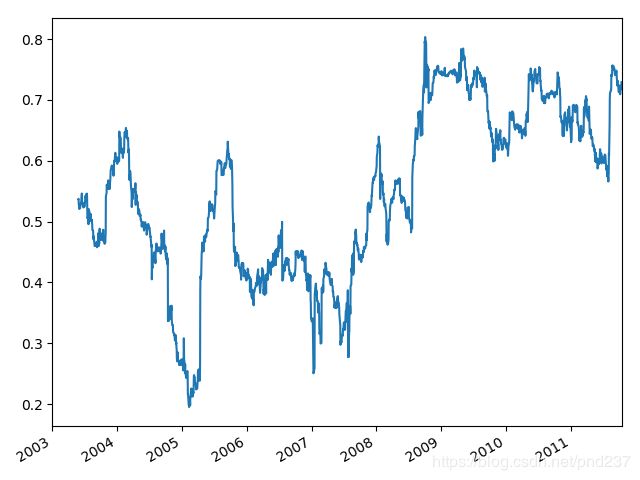
我们有时候可能会想计算随着时间的推移,两者在一定时间段内的关系,这个时候我们就需要使用二元移动窗口函数。首先考虑下面的数据:
spx_px = close_px_all.SPX
spx_rets = spx_px.pct_change()
returns = close_px_all.pct_change()
corr聚合函数可以计算传入的数据与窗口内数据的相关性:
corr = returns.AAPL.rolling(125,min_periods=100).corr(spx_rets)
corr.plot()
结果如下:
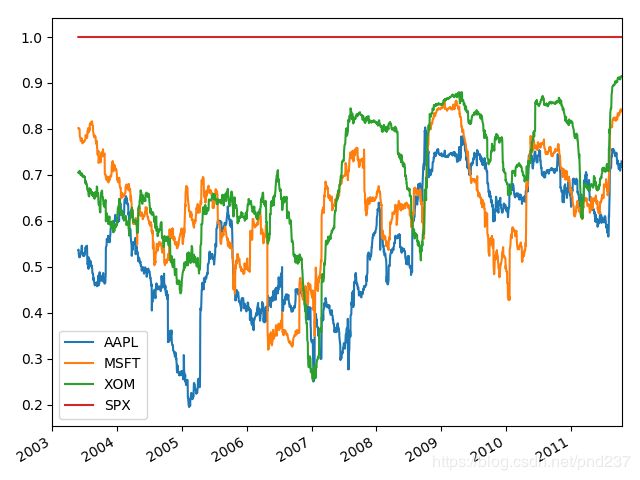
如果我们直接将一个DataFrame传入,则会计算每一列的相关性:
corr = returns.rolling(125,min_periods=100).corr(spx_rets)
corr.plot()
用户自定义的移动窗口函数
rolling以及其他方法提供了一个apply方法来应用自定义的移动窗口函数,唯一的要求是返回一个单一的值,在此不再赘述。