K-d tree
在计算机科学中,k-d树(k-dimensional的缩写)是一种空间划分数据结构,用于组织k维空间中的点。主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索)。k-d树是空间二分树(Binary space partitioning )的一种特殊情况。
索引结构中相似性查询有两种基本的方式:
- 一种是范围查询(range searches):范围查询就是给定查询点和查询距离的阈值,从数据集中找出所有与查询点距离小于阈值的数据;
- 另一种是K近邻查询(K-neighbor searches):K近邻查询是给定查询点及正整数K,从数据集中找到距离查询点最近的K个数据,当K=1时,就是最近邻查询(nearest neighbor searches)。
特征匹配算子大致可以分为两类:
- 一类是线性扫描法,即将数据集中的点与查询点逐一进行距离比较,也就是穷举,缺点很明显,就是没有利用数据集本身蕴含的任何结构信息,搜索效率较低。
- 第二类是建立数据索引,然后再进行快速匹配。因为实际数据一般都会呈现出簇状的聚类形态,通过设计有效的索引结构可以大大加快检索的速度。索引树属于第二类,其基本思想就是对搜索空间进行层次划分。根据划分的空间是否有混叠可以分为Clipping和Overlapping两种。前者划分空间没有重叠,其代表就是k-d树;后者划分空间相互有交叠,其代表为R树。
高维数据
维数灾难让大部分的搜索算法在高维情况下都显得花哨且不实用。 同样的,在高维空间中,k-d树叶并不能做很高效的最邻近搜索。一般的准则是:在k维情况下,数据点数目N应当远远大于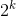 时,k-d树的最邻近搜索才可以很好的发挥其作用。
时,k-d树的最邻近搜索才可以很好的发挥其作用。
k-d树是每个节点都为k维点的二叉树。所有非叶子节点可以视作用一个超平面把空间分割成两个半空间。节点左边的子树代表在超平面左边的点,节点右边的子树代表在超平面右边的点。选择超平面的方法如下:每个节点都与k维中垂直于超平面的那一维有关。因此,如果选择按照x轴划分,所有x值小于指定值的节点都会出现在左子树,所有x值大于指定值的节点都会出现在右子树。这样,超平面可以用该x值来确定,其法线为x轴的单位向量。
创建k-d树
构建k-d树是一个逐级展开的递归过程。
有很多种方法可以选择轴垂直分割面( axis-aligned splitting planes ),所以有很多种创建k-d树的方法。 最典型的方法如下:
-
随着树的深度轮流选择轴当作分割面。(例如:在三维空间中根节点是 x 轴垂直分割面,其子节点皆为 y 轴垂直分割面,其孙节点皆为 z 轴垂直分割面,其曾孙节点则皆为 x 轴垂直分割面,依此类推。)
-
点由垂直分割面之轴座标的中位数区分并放入子树
选择轴垂直分割面,对于所有描述子数据(特征矢量),统计它们在每个维上的数据方差:数据方差大表明沿该坐标轴方向上的数据分散得比较开,在这个方向上进行数据分割有较好的分辨率。
这个方法产生一个平衡的k-d树。每个叶节点的高度都十分接近。然而,平衡的树不一定对每个应用都是最佳的。 [2]
查找:最邻近搜索
最邻近搜索用来找出在树中与输入点最接近的点。
k-d树最邻近搜索的过程如下:
-
从根节点开始,递归的往下移。往左还是往右的决定方法与插入元素的方法一样(如果输入点在分区面的左边则进入左子节点,在右边则进入右子节点)。
-
一旦移动到叶节点,将该节点当作"当前最佳点"。
-
解开递归,并对每个经过的节点运行下列步骤:
-
如果当前所在点比当前最佳点更靠近输入点,则将其变为当前最佳点。
-
检查另一边子树有没有更近的点,如果有则从该节点往下找。
-
-
当根节点搜索完毕后完成最邻近搜索。
实例:搜索过程
在k-d树中进行数据的查找也是特征匹配的重要环节,其目的是检索在k-d树中与查询点距离最近的数据点。这里先以一个简单的实例来描述最邻近查找的基本思路。
1. 例1:简单
星号表示要查询的点(2.1,3.1)。通过二叉搜索,顺着搜索路径很快就能找到最邻近的近似点,也就是叶子节点(2,3)。而找到的叶子节点并不一定就是最邻近的,最邻近肯定距离查询点更近,应该位于以查询点为圆心且通过叶子节点的圆域内。
为了找到真正的最近邻,还需要进行'回溯'操作:算法沿搜索路径反向查找是否有距离查询点更近的数据点。
第一步,二叉查找:自上而下,与超平面进行比较,判断进入左子树还是右子树,形成搜索路径。
此例中先从(7, 2)点开始进行二叉查找,超平面为x=7,2.1< 7,所以进入左子树到达(5,4);此时超平面为y=4,3.1<4,所以到达(2,3),此时搜索路径中的节点为<(7, 2),(5, 4),(2, 3)>;
第二步,找到最近邻点:首先以(2, 3)作为当前最近邻点;
第三步,回溯:自下而上,检查以查询点为中心、最近邻点距离为半径的圆是否与父节点的超平面相交
以(2, 3)点开始,计算其到查询点(2.1,3.1)的距离为0.1414,然后回溯到其父节点(5, 4),判断在该父节点的其他子节点空间中是否有距离查询点更近的数据点。即,以(2.1,3.1)为圆心,以0.1414为半径画圆,如图4所示,发现该圆并不和超平面y = 4交割,因此不用进入(5,4)节点右子空间中去搜索。
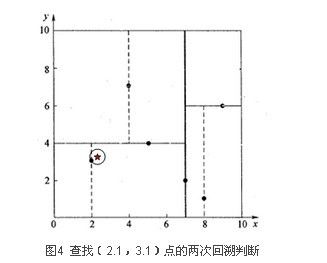
再回溯到(7, 2),以(2.1, 3.1)为圆心,以0.1414为半径的圆更不会与x = 7超平面交割,因此不用进入(7, 2)右子空间进行查找。至此,搜索路径中的节点已经全部回溯完,结束整个搜索,返回最近邻点(2, 3),最近距离为0.1414。
2. 例2:一个复杂点的例子如查找点为(2, 4.5)
第一步,同样先进行二叉查找,先从(7, 2)查找到(5, 4)节点,在进行查找时是由y = 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4, 7),形成搜索路径<(7, 2),(5, 4),(4, 7)>;
第二步,取(4, 7)为当前最近邻点,计算其与目标查找点的距离为3.202。
第三步,回溯,以(4, 7)点开始,计算其与查找点之间的距离为3.202。回溯到父节点(5, 4),以(2, 4.5)为圆心,以3.202为半径作圆,如图5所示(图中有误),可见该圆和y = 4超平面交割,所以需要进入(5, 4)左子空间进行查找。此时需将(2, 3)节点加入搜索路径中得<(7, 2),(2, 3)>。回溯至(2, 3)叶子节点,(2, 3)距离(2, 4.5)比(5, 4)要近,所以最近邻点更新为(2, 3),最近距离更新为1.5。回溯至(7, 2),以(2, 4.5)为圆心1.5为半径作圆,并不和x = 7分割超平面交割,如图6所示。至此,搜索路径回溯完。返回最近邻点(2, 3),最近距离1.5。k-d树查询算法的伪代码如下所示。

步骤总结:
-
从root节点开始,DFS搜索直到叶子节点,同时在stack中顺序存储已经访问的节点。
-
如果搜索到叶子节点,当前的叶子节点被设为最近邻节点。
-
然后通过stack回溯:
如果当前点的距离比最近邻点距离近,更新最近邻节点.
然后检查以最近距离为半径的圆是否和父节点的超平面相交.
如果相交,则必须到父节点的另外一侧,用同样的DFS搜索法,开始检查最近邻节点。
如果不相交,则继续往上回溯,而父节点的另一侧子节点都被淘汰,不再考虑的范围中.
-
当搜索回到root节点时,搜索完成,得到最近邻节点。
参考:
- https://encyclopedia.thefreedictionary.com/Kd-tree
- https://baike.baidu.com/item/kd-tree/2302515