CVPR2020(Segmentation):CPNet-论文解读《Context Prior for Scene Segmentation》
文章目录
- 原文地址
- 论文阅读方法
- 初识(Abstract & Introduction & Conclusion)
- 相知(Body)
- 2. Related Work
- 3.Context Prior
- 3.1. Affinity Loss
- 3.2. Context Prior Layer
- 3.3. Aggregation Module
- 3.4. Network Architecure
- 4. Experimental Results
- 4.1 Implementation Details
- 4.2 Evaluation on the ADE20K Dataset
- 4.3 Evaluation on the PASCAL-Context
- 4.4 Evaluation on Cityscapes
- 回顾(Review)
- 代码
原文地址
原文阅读地址
论文阅读方法
三遍阅读法
初识(Abstract & Introduction & Conclusion)
这篇文章主要讨论了上下文先验在场景分割的应用,发表于CVPR2020。
- Motivation: 最近出现很多利用上下文相关性的来改进分割的方法,但绝大多数没有考虑到不同类型的上下文相关性(different types of contextual dependencies),这往往会影响到场景理解(scene understanding)。
- Contributions:
-
a) 受到嵌入在Context Prior Layer中的Affinity Loss监督,构建的Context Prior能够捕捉类内(intra-class)和类间(inter-class)的上下文相关性;< 我的理解:类内就是同一类的意思,类间就是不同类的意思>
-
b) 为了验证提出的Context,构建了一个网络Context Prior Network(CPNet),其包含了一个Backbone和一个Context Prior Layer;
-
c) 在一些基准上成为了SOTA(ADE20K,Pascal-Context,Cityscapes)
-

这些探索上下文依赖的分割方法可以分为两类:基于金字塔的聚合方法(Pyramid-based aggregation method)和基于注意力的聚合方法(Attention-based aggregation method) 第一种方法用到金字塔模块或者全局池化层来聚合局部和全局上下文信息,虽然捕获了同类的上下文信息,但是却忽略了不同类的依赖关系,如上图b所示,当这个场景中存在一些复杂类别,这个方法导致上下文变得不可靠。第二种方法,有用来学习channel-attention,spatial attention或者point-wise attention来有选择聚合多样的上下文信息,但由于缺乏显式正则化手段,这些attention机制的关系描述不够清楚,可能会选择一些完全不需要的上下文关系,如上图e。这两种方法都在没有明确区分的情况下,融合了上下文信息,这将会导致不同上下文关系的混乱。
所以,作者在这篇文章中对类别中的上下文关系进行建模作为先验知识,从而获得更精准的结果。主要有这几个关键点:Context Prior, Context Prior Layer, Affinity Loss,Aggregation Module, Context Prior Network(CPNet)。
相知(Body)
2. Related Work
- Context Aggregation: 最近几年的用来捕获上下文依赖关系的方法可以分为两种。
- a) PSPNet采用了金字塔池化模块(pyramid pooling module)把特征图分成不同尺度区域,把每个区域的像素平均值作为这个区域中每个像素的局部上下文。DeepLab采用了空洞空间金字塔池化(Atrous Spatial Pyramid Pooling)去采样不同范围的像素值作为局部上下文。
- b) DANet,OCNet,和CCNet利用了自适应方法(self-similarity manner)去聚合长范围的空间信息。EncNet,DFN和ParseNet使用了全局平均池化去获得全局上下文。
- 尽管这些方法很成功,但由于没有区分不同的上下文关系的区别,他们可能会捕获到一些不必要的上下文依赖信息。而在我们的方法中,能够明确地规范模型去取得类内和类间的上下文依赖。
- Attention Mechanism: 对于语义分割任务中,注意力机制能够对多尺度特征进行软(softly)加权。受到SENet的鼓舞,EncoderNet,DFN和BiSeNet采用了channel attention去选择需要的特征图;接着,DANet和OCNet使用自注意力去获取长范围(long-range dependency),而PSANet学习了点(point-wise)注意力去获取长范围信息。 同样,这种方法也会聚合一些不需要的上下文信息。
3.Context Prior
为了去解决这些问题,在这篇文章中,先提出一个Context Prior去对相同类(intra-context)的像素与不同类(inter-context)的像素之间的关系进行建模。基于Context Prior,提出了Context Prior Network,它包含了受Affinity Loss监督的Context Prior Layer。
3.1. Affinity Loss
为了去明确规范这个网络去学习类别之间的关系,我们引入了Affinity Loss。对于图像上的每一个像素,Affinity Loss将会迫使网络去考虑在同一类别的像素和不同类别的像素。

只要给定输入的groundtruth,我们就可以知道每一个像素的‘Context Prior’(哪些属于同一类,哪些属于不同类),可以学习Context Prior去引导整个网络。首先根据ground truth建立Ideal Affinity Map作为监督:给定输入图像 I 和其对应的groundtruth L,将 I 送入网络中可以得到一个大小为HxW的特征图X。像上图一样,我们先将L下采样到与X大小相同,得到一个更小的groundtruth L~ 。我们使用了one-hot编码去对L~ 中的类别标签进行编码,得到一个大小为HxWxC的矩阵L^^,C为类别数。紧接着,将L~^ Reshape成NxC大小,N=HxW。最后,我们进行一个矩阵乘法:A = L~ L~T ,这个A就是我们期望的Ideal Affinity Map,大小为NxN。 我们使用Ideal Affinity Map去监督Context Prior Map的生成。
对于prior map中的每一个像素,其实是一个二分类问题。通常解决二分类问题用到的是二元交叉熵损失:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kXkZecqA-1587906892741)(C:\Users\lenovo\AppData\Roaming\Typora\typora-user-images\image-20200422153524486.png)]](http://img.e-com-net.com/image/info8/b3dd1095e66343a1ae8c88086be2da92.jpg)
其中,{pn ∈ P,n ∈ [1, N2]},P为预测得到的Prior MAP,{an ∈ A,n ∈ [1, N2]},A为期望得到的Ideal Affinity MAP。
但它只考虑了在Prior Map中的单个像素,忽略了与其他像素的语义联系,我们可以看到在P(A)中的每一行其实都对应着feature map X中的每个像素,可以它们表示为同类像素或者不同类像素(有点邻接矩阵的意思),这个关系是有助于推理语义相关性和场景结构的。因此,我们考虑把同类像素和不同类像素作为两个部分来对关系分别编码:
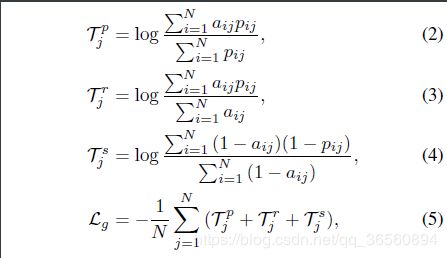
其中,(2)(3)(4)分别表示P中第j行的同类准确率(precision),同类召回率(recall),特异度(specificity)。
最后,完整的Affinity Loss定义如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Rod9IynQ-1587906892756)(C:\Users\lenovo\AppData\Roaming\Typora\typora-user-images\image-20200422154818168.png)]](http://img.e-com-net.com/image/info8/c6b5eb94fae44c82b809757f7355edea.png)
其中,λu 和 λg 用于平衡一元损失(unary loss)和全局损失(global loss),根据经验,通常都是直接设为1。
3.2. Context Prior Layer
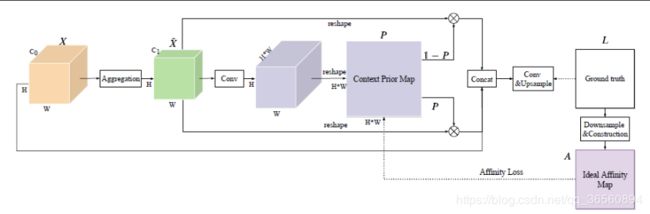
如上图,Context Prior Layer得到一个输入特征X,形状为HxWxC0。我们使用聚合模块(aggregation module)将X变为X~,形状为HxWxC1。得到 X~ 之后,进行1x1卷积+ BN + Sigmoid,形状变为HxWxN(N=HxW)去学习一个先验图 P。 在Affinity Loss的明确监督下,Context Prior Map P可以对类内(intra-class)像素和类间像素(inter-class)之间的关系进行编码。
- 类内(intra-class)为:Y=P X~,这里的X~ 的尺寸将会被reshape成NxC1,这个操作会让Prior map能够自适应地为特征图选择类内像素作为类内上下文(intra-class context)。
- 相反,反转的Prior Map可以选择性地突出类间(inter-class)像素,让其作为类间上下文(inter-class context):Y_ =(1-P) X~,其中的 1 为和P大小相同的全1矩阵。
最后,我们将原始特征和两种上下文Concat去输出最终的预测F = Concat(X, Y, Y_),有了这两种上下文,就可以推测每个像素的语义相关性和场景结构。
3.3. Aggregation Module
Context Prior Map需要一些局部空间信息去推理语义相关性,一般来说要聚合更多的空间信息就要使用更大的卷积核,但是计算代价是很大的。因此,作者用全分离卷积(fully separable convolution)设计了一个有效的Aggregation Module去聚合空间信息。
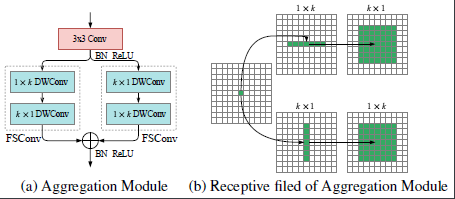
我们将一个普通卷积分解成两个在空间上不对称的卷积,比如一个kxk的卷积,我们这样来替代:先使用一个kx1卷积,接着再使用一个1xk卷积,我们称为空间可分离卷积(spatial separable convolution),并且每个空间卷积都采用深度都采用深度卷积(depth-wise convolution),这导致计算量大大减少。由于考虑了空间和深度两个维度,作者把这种方式称为Fully Separable Convolution。
3.4. Network Architecure
Context Prior Network(CPNet)是一个全卷积网络,由Backbone和一个Context Prior Layer组成。Backbone是一个用了空洞卷积(dilation strategy)的现成网络。同时,在backbone网络的阶段4(stage 4)还使用了辅助损失(auxiliary loss),也是一个交叉熵损失。最终的损失函数为:
![]()
其中Ls, La, Lp 分别代表主要分割损失(main segmentation loss),辅助损失(auxiliary loss)以及Affinity Loss,λs, λa, λp 是用来平衡loss的权重。经验性地设置为:λs=1, λa=1, λp=0.4。
4. Experimental Results
4.1 Implementation Details
- Network: ResNet作为预训练,output_stride=8, 在Backbone的阶段4使用辅助损失(auxiliary loss),在Aggregation Module中fullyseparable convolution的卷积核大小为11。
- Data Augmentation:采用均值减法,随机水平翻转、随机尺度变化({0.5, 0.75, 1.0, 1.5, 1.75, 2.0}),最后在训练时,我们随机剪裁大图像或者填充小图像到固定的尺寸。
- Optimization:SGD(momentum=0.9, weight decay=10-4, batch size=16),使用了
poly训练策略。 - Inference:在预测阶段,用多尺度和翻转输入的平均预测作为预测结果,提高性能。
4.2 Evaluation on the ADE20K Dataset

Table 1 为消融实验。

为了证明Context Prior的有效性以及泛化能力,做了Table2 和Table3中的实验。

在CPNet网络中Prior Map的可视化,证明Context Prior Layer中的Prior Map可以学习到明确的结构信息。
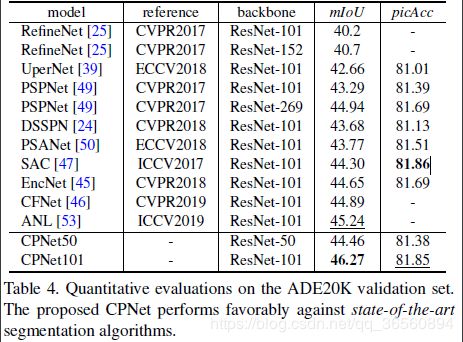
与其他的一些SOTA模型的比较。
4.3 Evaluation on the PASCAL-Context
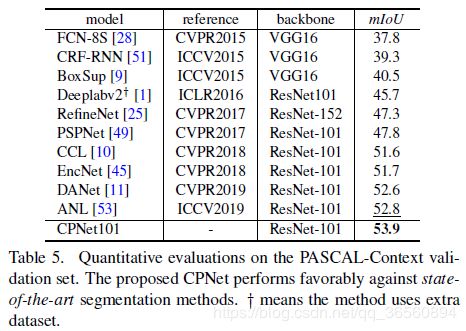
与其他的SOTA模型的比较。
4.4 Evaluation on Cityscapes

与其他的SOTA模型的比较。
回顾(Review)
这个文章想法很不错,特别是在Context Prior的设计与监督方式上的构思都比较完善。
以往人们在设计分割模型时,很多时候想着是尽可能地捕获更多、更丰富的特征信息(例如金字塔池化),这个固然能提高模型的准确率,但是往往忽略了这样组合起来的特征可能是混乱的、不考虑类别之间的上下文依赖关系的。而这篇文章,以这个角度为切入点,所以能在兵荒马乱的CVPR2020投稿中脱颖而出。
再次回顾这篇文章的亮点之处,除了Context Prior,还有Aggregation Module。从Aggregation Module可以看到,目前除了3x3的卷积之外,如果需要增大感受野,不再是扩大卷积核大小和增加卷积层数这种耗费计算资源的操作了,而是使用spatial separable convolution,并且还使用了depth-wise convolution。所以,我们在设计网络时,要尽可能地考虑计算成本。
非要说些不足的话,以我的愚见,就是Prior Map的利用还是不够,尽管作者尽可能想多利用一些Prior Map的信息,从而用到了(1-P)来得到一个reversed map,但是后面只是与原本的特征简单Concat,总是有种很奇怪的感觉。不过深度学习领域目前还是实验主导性,只要你的model提升了几个点,哪怕你的模型可解释性很差,但是只要你自圆其说,就问题不大。
代码
https://github.com/ycszen/ContextPrior
以上为个人的浅见,水平有限,如有不对,望大佬们指点。
未经本人同意,请勿转载,谢谢。