《Hierarchical Attention Network for Document Classification》—— 用于文本分类的层次注意力网络
目录
- 《Hierarchical Attention Network for Document Classification》—— 用于文本分类的层次注意力网络
- 1、文本分类
- 1.1 文本挖掘
- 1.2 数据类型
- 1.3 文本分类
- 2、层次注意力网络
- 2.1 基于GRU的词序列编码器:
- 2.2 单词序列编码器
- 2.3 单词注意力机制
- 2.4 句子编码器
- 2.5 句子注意力机制
- 2.6 文档分类
- 3、实验和结果
- 3.1 数据集
- 3.2 实验任务
- 3.3 对比模型
- 3.4 模型参数
- 3.5 论文实验结果
- 3.6 可视化分析
- 4、总结
- 4.1 论文主要创新点
- 5、推荐阅读论文
《Hierarchical Attention Network for Document Classification》—— 用于文本分类的层次注意力网络
- 作者:Zichao Yang,Diyi Yang,Chris Dyer,Xiaodong He;
- 单位:卡耐基梅隆大学,微软研究院;
- 论文来源:ACL 2016;
1、文本分类
1.1 文本挖掘
文本挖掘是一个以半结构或者无结构的自然语言文本为对象的数据挖掘,是从大规模文本数据集中发现隐藏的、重要的、新颖的、潜在的、有用的规律的过程;
文本分类是文本挖掘的一个常见任务
1.2 数据类型
非结构化数据:
没有固定结构的数据,直接整体进行存储,一般存储为二进制的数据格式;
半结构化数据:
结构化数据的一种形式,它并不符合关系型数据库等形式关联起来的数据模型结构,但包含相关标记,用来分割语义元素以及对记录和字段进行分层;
结构化数据:
能够使用数据或者统一的结构加以表示,如数字、符号。
1.3 文本分类
文本分类是自然语言处理的基本任务。目的是将非结构化文档(例如,评论,电子邮件,帖子,网站内容等)分配给一个或者多个类。
文本分类流程:
- 文本数据获取;
- 文本预处理;
- 文本的向量表示;
- 构造分类器;
- 模型评估;
2、层次注意力网络
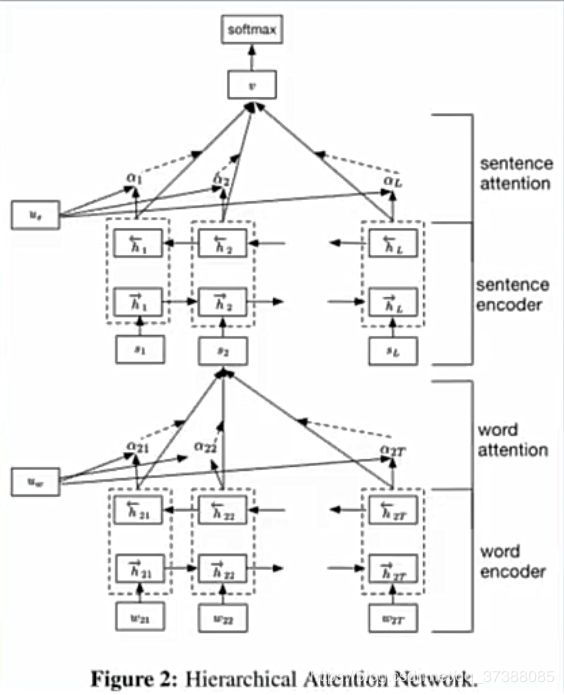
网络组成结构:
- word encoder:单词序列编码器
- word attention:单词注意力机制
- sentence encoder:句子编码器
- sentence attention:句子注意力机制
2.1 基于GRU的词序列编码器:
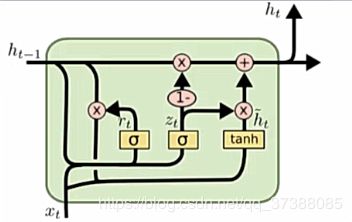
- RNN的一个变种,使用门机制来记录序列当前的状态;
- 隐藏层状态的计算公式: h t = ( 1 − z t ) ⊙ h t − 1 + z t ⊙ h t ~ h_{t}=\left(1-z_{t}\right) \odot h_{t-1}+z_{t} \odot \tilde{h_{t}} ht=(1−zt)⊙ht−1+zt⊙ht~
- 更新门: z t = σ ( W z x t + U z h t − 1 + b z ) z_{t}=\sigma\left(W_{z} x_{t}+U_{z} h_{t-1}+b_{z}\right) zt=σ(Wzxt+Uzht−1+bz)
- 候选状态: h t ~ = tanh ( W h x t + r t ⊙ ( U h h t − 1 ) + b h ) \tilde{h_{t}}=\tanh \left(W_{h} x_{t}+r_{t} \odot\left(U_{h} h_{t-1}\right)+b_{h}\right) ht~=tanh(Whxt+rt⊙(Uhht−1)+bh)
- 重置门: r t = σ ( W r x t + U r h t − 1 + b r ) r_{t}=\sigma\left(W_{r} x_{t}+U_{r} h_{t-1}+b_{r}\right) rt=σ(Wrxt+Urht−1+br)
2.2 单词序列编码器
我们假设文档有L个句子,每个句子 s i s_i si包含T个单词,单词 w i t w_{it} wit表示第i个句子中的第t个单词,对于单词 w i t w_{it} wit,使用embedding词嵌入矩阵获取单词对应的词向量: x i t = W e w i t , t ∈ [ 1 , T ] x_{it} = W_ew_{it},t\in [1,T] xit=Wewit,t∈[1,T]
获得句子中每个单词对应的词向量后,使用双向GRU或者双向LSTM将正向和反向的信息结合起来获得隐藏层的输出: h i t = [ h i t → , h i t ← ] h_{i t}=[\overrightarrow{h_{i t}}, \overleftarrow{h_{i t}}] hit=[hit,hit]
其中: h i t → = G R U → ( x i t ) \overrightarrow{h_{i t}}=\overrightarrow{G R U}\left(x_{i t}\right) hit=GRU(xit) h i t ← = G R U ← ( x i t ) \overleftarrow{h_{i t}}=\overleftarrow{G R U}\left(x_{i t}\right) hit=GRU(xit)
以上为单词序列编码器的基本原理过程。
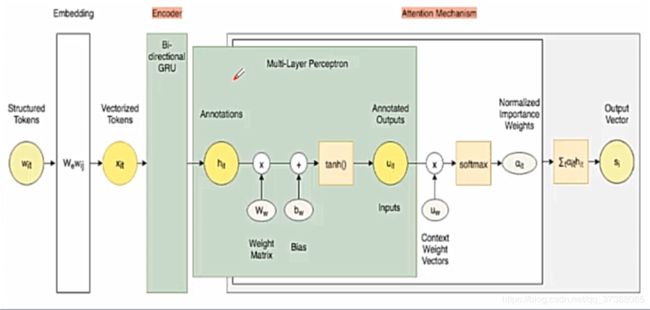
2.3 单词注意力机制
并非所有的单词都对句子的含义表示有同等的作用,因此引入了注意力机制来提取对句子含义更重要的词,并且汇总词信息来形成句子向量。
我们从单词序列编码器获得了句子中每个单词的隐层输出 h i t h_{it} hit,隐层输出 h i t h_{it} hit是构建单词注意力机制的基础,在论文中使用的注意力模型为加性模型: s ( x , q ) = v T t a n h ( W x + U q ) s(x,q) = v^Ttanh(Wx+Uq) s(x,q)=vTtanh(Wx+Uq)
公式中的W,U和v都是可学习的参数。
在论文中通过随机初始化 W w W_w Ww和偏置 b w b_w bw进行训练获得 h i t h_{it} hit的隐藏信息 u i t u_{it} uit,即: u i t = tanh ( W w h i t + b w ) u_{i t}=\tanh \left(W_{w} h_{i t}+b_{w}\right) uit=tanh(Wwhit+bw)
得到新的词表示 u i j u_{ij} uij之后,为了衡量每个单词的重要性,我们随机初始化一个上下文向量 u w u_w uw,进而计算句子中每个单词的重要性: α i t = exp ( u i t ⊤ u w ) ∑ t exp ( u i t ⊤ u w ) \alpha_{i t}=\frac{\exp \left(u_{i t}^{\top} u_{w}\right)}{\sum_{t} \exp \left(u_{i t}^{\top} u_{w}\right)} αit=∑texp(uit⊤uw)exp(uit⊤uw)
得到每个单词的重要性之后,我们可以通过加权平均得到句子的向量表示: s i = ∑ t α i t h i t s_{i}=\sum_{t} \alpha_{i t} h_{i t} si=t∑αithit
以上为单词注意力机制的基本原理。
2.4 句子编码器
在得到句子的向量表示 s i s_i si之后,用类似的方法得到文档向量。我们使用双向GRU获得前向和后向的句子向量表示 h i h_i hi: h i = [ h i → , h i ← ] h_{i}=[\overrightarrow{h_{i}}, \overleftarrow{h_{i}}] hi=[hi,hi]
公式中的前向GRU和后向GRU计算公式计算如下: h ⃗ i = GRU → ( s i ) , i ∈ [ 1 , L ] \vec{h}_{i}=\overrightarrow{\operatorname{GRU}}\left(s_{i}\right), i \in[1, L] hi=GRU(si),i∈[1,L]
h ← i = GRU ← ( s i ) , t ∈ [ L , 1 ] \overleftarrow{h}_{i}=\overleftarrow{\operatorname{GRU}}\left(s_{i}\right), t \in[L, 1] hi=GRU(si),t∈[L,1]
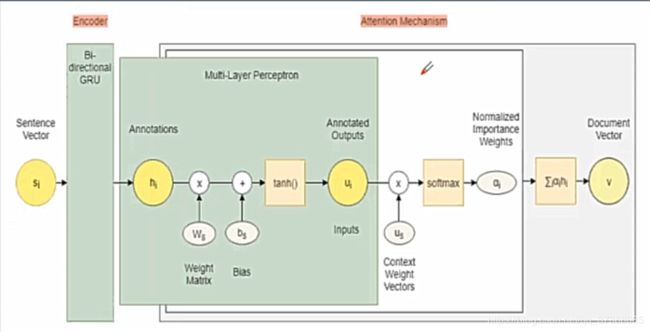
2.5 句子注意力机制
为了获得文档的向量表示,我们同样使用加性注意力机制,基于句子级别的上下文信息,我们可以得到文档的向量表示 v v v: u i = tanh ( W s h i + b s ) u_{i}=\tanh \left(W_{s} h_{i}+b_{s}\right) ui=tanh(Wshi+bs)
α i = exp ( u i ⊤ u s ) ∑ t exp ( u t ⊤ u s ) \alpha_{i}=\frac{\exp \left(u_{i}^{\top} u_{s}\right)}{\sum_{t} \exp \left(u_{t}^{\top} u_{s}\right)} αi=∑texp(ut⊤us)exp(ui⊤us)
v = ∑ i α i h i v=\sum_{i} \alpha_{i} h_{i} v=i∑αihi
2.6 文档分类
文档向量 v v v是文档的高级表示,可用做文档分类的功能,在文档向量 v v v上接一个softmax层:
p = softmax ( W c v + b c ) p=\operatorname{softmax}\left(W_{c} v+b_{c}\right) p=softmax(Wcv+bc)
其对应的损失函数为: L = − ∑ d log p d j L=-\sum_{d} \log p_{d j} L=−d∑logpdj
3、实验和结果
3.1 数据集
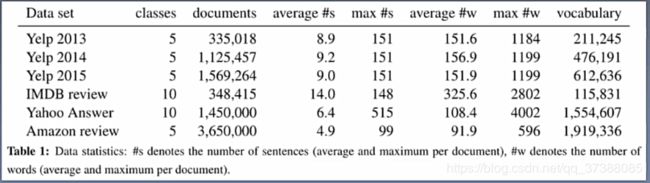
- 论文中使用了六个数据集:Yelp review 2013,2014,2015;IMDB review;Yahoo Answers;Amazon reviews;
- 每个数据集合中80%的数据用作训练集合,10%的数据用作验证集合,剩余10%的集合用作测试集合;
3.2 实验任务
在六个数据集上的文本进行分类实验;
3.3 对比模型
- 线性模型
- SVM
- word-based CN
- Character-based CNN
- Conv/LSTM-GRNN
3.4 模型参数
- 批量大小:64
- 动量值:0.9
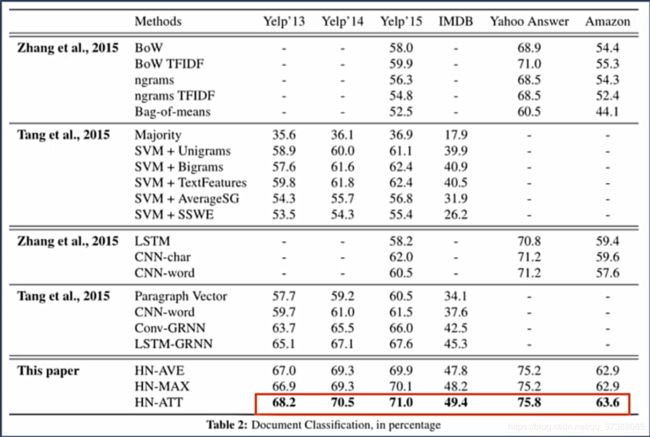
3.5 论文实验结果
3.6 可视化分析
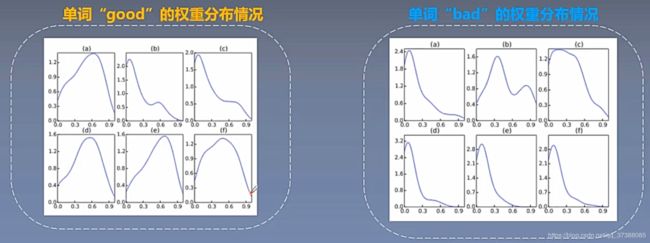

为了进一步说明注意力机制的作用,作者对attention注意力机制下的单词和句子权重进行可视化,上图中的蓝色越深表示单词在句子中的权重越大,粉色越来越深说明句子在文本中的权重越大。
4、总结
4.1 论文主要创新点
- 提出了一种用于文本分类的层次注意力网络;
- 该网络受限构建句子的表示,然后将它们聚合成文档表示;
- 该网络在单词和句子级别应用了两个级别的注意力机制;
5、推荐阅读论文
- Tianyang Zhang et al.2018. Learning Structured Representation for Text Classification via Reinforcement Learning.
- Joulin et al.2017.Bag of Tricks for Efficient Text Classification.
- Johnson et al.2017. Deep Pyramid Convolutional Neural Networks for Text Categorization.
- JacobDevlin et al.2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.