easyExcel使用过程中由异常:java.lang.NoSuchMethodException: Unknown property 'XXXXX' 引发的思考
最近项目开发过程中需要大量用到导出excel模块, 动不动都是十万级数据导出, 以前复用的POI导出模块在并发导出大量数据情况下服务器负载压力太大经常出现OOM情况, 一个几兆的文件解析要用掉上百兆的内存.排除掉查询数据速度情况下,想追寻是否有更好的组件来实现大量数据导出情况下, 内存消耗也能在合理范围内呢, 阿里开源的easyExcel完美解决了这个问题.
JAVA解析Excel工具easyexcel
Java解析、生成Excel比较有名的框架有Apache poi、jxl。但他们都存在一个严重的问题就是非常的耗内存,poi有一套SAX模式的API可以一定程度的解决一些内存溢出的问题,但POI还是有一些缺陷,比如07版Excel解压缩以及解压后存储都是在内存中完成的,内存消耗依然很大。easyexcel重写了poi对07版Excel的解析,能够原本一个3M的excel用POI sax依然需要100M左右内存降低到KB级别,并且再大的excel不会出现内存溢出,03版依赖POI的sax模式。在上层做了模型转换的封装,让使用者更加简单方便
引用自:https://github.com/alibaba/easyexcel
easyExcel的写出使用非常简单, 只需要将要设置的单元格表头设置成java模型即可:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class ErrorReportDataVo extends BaseRowModel{
@ExcelProperty(value="序号", index=0)
private String ID;
@ExcelProperty(value="错误类型", index=1)
private String ErrorCode;
@ExcelProperty(value="出口收费站", index=2)
private String StationName;
@ExcelProperty(value="出口车道编号", index=3)
private String Lane;
@ExcelProperty(value="出口操作时间", index=5)
private String ExitTime;
@ExcelProperty(value="任务编号", index=6)
private String jobNum;
@ExcelProperty(value="处理信息", index=7)
private String listNo;
@ExcelProperty(value="入口收费站", index=8)
private String fareStationName;
@ExcelProperty(value="入口操作时间", index=9)
private String entryTime;
@ExcelProperty(value="车牌", index=10)
private String plate;
@ExcelProperty(value="车型", index=11)
private String vehicleClass;
@ExcelProperty(value="车种", index=12)
private String vehicleType;
@ExcelProperty(value="支付类型", index=13)
private String paymentmethod;
@ExcelProperty(value="轴数", index=14)
private String axleCount;
@ExcelProperty(value="总轴重(吨)", index=15)
private String feeWeight;
@ExcelProperty(value="总限重", index=16)
private String limitWeight;
@ExcelProperty(value="超限比例", index=17)
private String overLoadRate;
@ExcelProperty(value="OBU编码", index=18)
private String OBUID;
}
- 映射的模型需要继承基础类BaseRowModel
- 在表头属性上添加注解@ExcelProperty value代表标题列显示文字, index代表列的索引
- 映射模型需要有Set,Get方法 这里我使用了lombok的@Data注解进行实现
然后附上我调用easyExcel的Util类EasyExcelUtil:
@Slf4j
public class EasyExcelUtil {
/***
* excel数据转换成文件
* @param request
* @param response
* @param result 准备好数据的POJO类
* @param name 文件名
* @return
*/
public static File excelWriter(HttpServletRequest request, HttpServletResponse response, List result,
String fileName) {
FileOutputStream fos = null;
File file = null;
try {
// 获取要生成的excel文件的完整路径
String fileAbsolutePath = FileUtil.getFileDownloadName(request, response, fileName, ".xlsx");
file = new File(fileAbsolutePath);
fos = new FileOutputStream(file);
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
log.error(" fileAbsolutePath UnsupportedEncodingException", e);
} catch (FileNotFoundException e1) {
// TODO Auto-generated catch block
log.error(" FileNotFoundException", e1);
}
writerExcelFile(fos, result);
return file;
}
private static void writerExcelFile(OutputStream fos, List result) {
try {
ExcelWriter writer = new ExcelWriter(fos, ExcelTypeEnum.XLSX);
Sheet sheet = new Sheet(1, 0, result.get(0).getClass());
//开始执行excel文件写入数据
writer.write(result, sheet);
writer.finish();
} catch (Exception e) {
log.error(" exception", e);
} finally {
try {
fos.close();
} catch (IOException e) {
log.error(" IOException", e);
}
}
}
}在此看起来没有任何问题, 可是在某个java模型进行导出时候出现异常:
java.lang.NoSuchMethodException: Unknown property 'ErrorCode'
at org.apache.commons.beanutils.PropertyUtilsBean.getSimpleProperty(PropertyUtilsBean.java:1122)
at org.apache.commons.beanutils.PropertyUtilsBean.getNestedProperty(PropertyUtilsBean.java:686)
先说原因: 是因为映射类型的私有属性变量必须符合驼峰命名式,以小写开头.
比如此property 改成如下问题消失
@ExcelProperty(value="错误类型", index=1)
private String errorCode;
easyExcel底层是通过调用org.apache.commons.beanutils.PropertyUtilsBean实现查找比对获取返回值再判断
Object value = BeanUtilsBean.getInstance().getPropertyUtils().getNestedProperty(oneRowData,
excelHeadProperty.getField().getName());报错地方为PropertyUtilsBean源码如下:
// Retrieve the property getter method for the specified property
PropertyDescriptor descriptor = getPropertyDescriptor(bean, name);
if (descriptor == null) {
throw new NoSuchMethodException("Unknown property '" + name + "'");
}bean是我们的List中某个实体, name是需要对应的字段名称
是因为返回的descriptor为空才抛出异常
getPropertyDescriptor(Object bean, String name) 中遍历查找的核心代码为:
PropertyDescriptor descriptors[] = getPropertyDescriptors(bean);
if (descriptors != null) {
for (int i = 0; i < descriptors.length; i++) {
if (name.equals(descriptors[i].getName()))
return (descriptors[i]);
}
}这里断点调试发现bean中原有变量为大写开头, 执行方法getPropertyDescriptors(Object bean)返回的 descriptors[] 数组某个对象内属性如下:
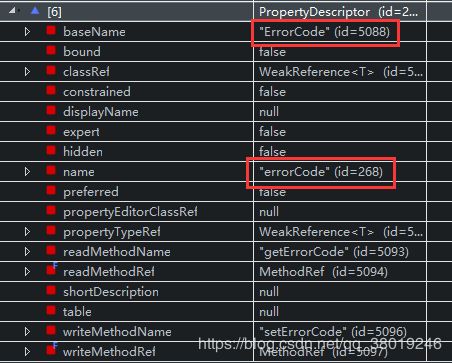
表头变量baseName被解析成小写开头的name, 然后再和name进行比对. 遍历完成后比对不上往下走执行类似遍历方法
这里引发我思考: 为什么需要用name来替换原有的baseName作为比对属性, 优劣是什么呢, 是如何实现的?
先留个坑, 明天再继续深究.一路看下来不得不说Commons BeanUtils这个项目还是牛批.