强化学习(RL)原理以及数学模型
- 强化学习简介
- 1强化学习与机器学习的关系
- 2强化学习的一些小案例
- 强化学习的原理
- 强化学习的数学原理
- 1建模的思路
- 2 马尔可夫过程
- 3 马尔可夫决策过程MDP
1.强化学习简介
1.1强化学习与机器学习的关系
强化学习是机器学习的一个分支,强调如何基于环境行动,以取得最大化的预期利益,其灵感来源于心理学中的行为主义理论,即有机体如何在环境的奖励或惩罚刺激下,逐步形成对刺激的预期,产生能最大化利益的习惯性行为。
如图所示,Agent表示机器人,Enviroment表示环境,强化学习其实是在环境和机器人之间的互动,环境通过对机器人产生奖励,刺激机器人产生下一个action,如此不断进行下去。这与条件反射非常像。 
强化学习是一个非常老的学科了,但它也处于一个大的AI框架下,涉及的内容主要可以归为如下
- 人工智能
- 运筹学
- 控制论
- 认知科学和心理学
如图所示 
在机器学习里,强化学习与有监督学习和无监督学习不同,它的互动主要基于环境和机器人之间的互动,环境没有给机器人提供什么标签数据之类的,而是给它一定的刺激,让它的行为发生一定的改变。我们稍微总结一下这三类学习的特点:
- 监督学习:有标签的数据,通过学习出来一组好的参数来预测标签
- 无监督学习:无标签数据,没有直接的反馈,更多的是挖掘数据中的隐含规律,与数据挖掘类似
- 强化学习:
无特定的数据,只有奖励信号;
奖励信号不一定实时,大部分情况滞后;
研究的不是独立同分布的数据,更多的是时间序列的数据;
当前的行为影响后续的分布;
总结一下,我们发现监督学习和无监督学习像是大学生考试前的死记硬背,硬是数据的分布和结构通过学习得到的参数背下来;而强化学习更多的像是人在做数学题时的逻辑推理,它当前的信号和刺激影响后来的信号和刺激。
强化学习的主要发展历程如下:
Bellman: Dynamic Programming (1956).
Sutton: TD Algorithm (1988).
Watkins: Q-Learning (1992).
Rummery: SARAS Algorithm (1994).
…..
Kocsis: Upper Confidence Bound Monte Carlo Tree Search (2006).
Silver: Deterministic Policy Gradient (2014).
….. Deep Reinforcement Learning.
Maybe Artificial General Intelligence (2030), by Richard Sutton
可以看出这是一个很早就开始研究的领域了,并不是近两年才开始兴起的。
1.2强化学习的一些小案例
用强化学习训练的跑酷
width="560" height="315" src="https://www.youtube.com/embed/g59nSURxYgk" allowfullscreen="">打乒乓球
width="560" height="315" src="https://www.youtube.com/embed/PSQt5KGv7Vk" allowfullscreen="">flop bird
width="560" height="315" src="https://www.youtube.com/embed/xM62SpKAZHU" allowfullscreen="">更加聪明的,最后能像人一样偷懒的,
width="560" height="315" src="https://www.youtube.com/embed/V1eYniJ0Rnk" allowfullscreen="">2.强化学习的原理
强化学习不像监督学习那样有自己明确的目标,强化学习可以看成是一个记分的系统,记住及其获得低分和高分的行为,然后不断要求机器能取得高分的同时避免低分。你也可以把它当成分数导向的系统,跟监督学习的标签一样。
model-free 和model-base
我们根据环境将机器分为两种:不理解环境(model-free RL) 和理解环境的(model-base RL).
不理解环境
1.机器人不懂得环境是什么样子,它会通过自己在环境中不断试错,以获得行为上的改变。
2.这类模型常用的有Q learning,Sarsa,Policy Gradients.理解环境的
1.机器人会通过先验的只是来先理解这个真实世界是怎么样子的,然后用一个模型来模拟现实世界的反馈,这样它就可以在它自己虚拟的世界中玩耍了。
2.与modle-free中的玩耍方式一样,但model-base有两个世界,不仅能在现实世界中玩耍,也能在自己虚拟的世界中玩耍。最大的特色—想象力:
model-free只能在一次行动之后静静得等待现实世界给的反馈然后再取材行动,而model-base可以采用想象力预判接下来发生的所有情况,然后根据这些想象的情况选择最好的那种,并根据这种情况来采取下一步的策略。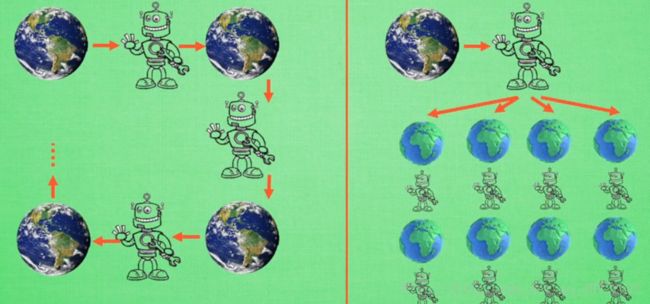
基于概率和基于价值
顾名思义就是根据每一个动作出现的概率来采取行动,而基于价值的是根据众多的动作中选择。基于价值的是选择下一步行动中价值最高的,而基于概率的则不一定会选择概率最大的。 
上面说的是不连续的动作,如果是连续的动作,基于价值的是无能威力的,只能通过基于概率的,通过这一连续的动作选出合理的概率分布来选择。
基于概率的一般有policy Gradient,基于价值的有Q learning和Sarsa.
3.强化学习的数学原理
3.1建模的思路
接下来说一下建模部分,假设我们要建立数学模型,我们需要满足什么条件嗯?
不确定性:
对于序列模型,连续动作的模型,如果要预测下一步应该采取什么策略,必须要在众多选择中选择一个,作为下一步应该采取的行动,因此,各个行动被采取应该都有一定的可能性。决策能力
机器人在知道各种行动被采取的可能性后应该知道如何作出决策,强化学习里并不是说概率最大的就一定会被选择基于长远考虑
我们选择下一步的行动不能为了当前奖励,而损失长远的奖励,就像人吸烟一样,不要为了当前的一时舒爽,而放弃更加长远的健康。
那么基于这样的考虑,我们应该怎建立相应的数学模型呢?
我们回头看一下强化学习的一般框架: 
建立如下变量描述:
- 奖励Rt:应该是一个标量函数,在玩游戏中,可以当成是分数的累积,所有问题的解决都是围绕最大化累积奖励的。
- 历史History,Ht:应该能记录过去行为的所有动作和奖励情况,即包含观测,奖励,行为三方面的信息的序列,满足:
HT=O1,R1,a1,⋯,Ot,Rt,at
- state状态St:是决定将来的,已有的信息,关于历史的函数St=f(Ht)
- Action动作at:记录当前时刻的动作是什么
对应到我们前面给的几个小案例,这些变量对应如下:
案例1: 
- Objective:robot直立行走
- State: 关节的角度与位置
- Action: 作用在关节上的力矩
- Reward: +1如果水平向前移动
案例2: 
- Objective:游戏得到高分
- State: 游戏每时刻的输入画面
- Action: 游戏控制键:上下左右
- Reward: 实时的游戏得分
案例3:
- Objective:战胜对手,赢得棋局
- State: 每颗棋子的位置
- Action: 下一个棋子的位置
- Reward: +1最终赢棋,0输棋
所以,如果我们要设立一个强化学习,我们必须知道目标是什么,当前状态又是什么,下一步应该怎么走,同时还要设立奖励的函数。
3.2 马尔可夫过程
状态St可以看作是一个马尔可夫过程,

这个概率矩阵是固定的,知道了这个概率转移矩阵,如果知道第一天这三种状态出现的概率,就可以算出第二天出现这三种状态的概率.
放在强化学习中,状态转移矩阵的概率表示为:
那我们知道了马尔可夫过程了,我们该怎么确定状态呢?一个机器人的状态,比如说一架直升机应该用什么来确定它当前的状态呢?我们能想到的一般会有这架飞机所在位置,速度和它的角速度等,那如何用数学的语言描述出来呢?
结合前面说的,我们把这个马尔可夫过程描述为<S,P>,S表示一个有限的状态集合,P表示状态转移矩阵,计算的公式为:Pss′=P(St+1=s′|St=s)
3.3 马尔可夫决策过程(MDP)
前面讲的都是一些铺垫,这才是强化学习的正菜,称为马尔可夫决策过程,用数学符号表示为:
- S是一个有限的状态集合
- A是一个有限的动作集合
- P是一个状态转移的概率矩阵,它表示出现某个动作之后,下一个出现的动作是什么\ \ 的概率大小,计算公式为:
Pass′=P(St+1=s′|St=s,At=a)a表示某一动作。
- R表示奖励函数:
Ras=E(Rt+1|St=s,At=a)表示的是一个期望
- γ表示一个折中因子,γ∈[0,1]
这是绝大多数TL问题的数学表示,每个时刻机器人都会采用一个动作,然后会得到一个奖励,奖励函数和状态转移矩阵就构成了我们的环境,P,R就决定了我们的模型。马尔可夫决策过程如下:
- 在t=0时刻,随机初始化状态s0~P(s0)
- 机器人根据st选择行动方案at
- 环境给出奖励rt~R(·|st,at)
- 环境给出下一时刻的状态st+1=P(·|st,at)
- 机器人接收rt,st+1
- 循环下去
未完