李宏毅2020深度学习课程作业
Homework 1: Linear Regression
李宏毅老师个人网站链接:http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML20.html
课程b站链接:https://www.bilibili.com/video/av94519857
作业说明YouTube链接:https://www.youtube.com/watch?v=QfU-qXINCvs&feature=youtu.be
作业说明b站链接:https://www.bilibili.com/video/av96698631
作业示范链接:https://colab.research.google.com/drive/131sSqmrmWXfjFZ3jWSELl8cm0Ox5ah3C(谷歌网盘)
Data:https://download.csdn.net/download/qq_39715243/12289501
作业目标:由前9小时的18个feature(包含PM2.5)预测第10个小时的PM2.5
代码运行环境:Google的Colaboratory
Load 'train.csv'
读数据,train.csv的资料为12个月,每个月取20天,每天24小时的资料(每小时资料有18个feature)
如果不能登上Google的网盘的话,可以下载上面的Data,代码需要自己调整!代码是在ipynb上运行的!
import sys
import pandas as pd
import numpy as np
from google.colab import drive
!gdown --id '1wNKAxQ29G15kgpBy_asjTcZRRgmsCZRm' --output data.zip
!unzip data.zip
# data = pd.read_csv('gdrive/My Drive/hw1-regression/train.csv', header = None, encoding = 'big5')
data = pd.read_csv('./train.csv', encoding = 'big5')Preprocessing
取需要的数值部分,将'RAINFALL'栏全部填0,。另外,如果要在colab重复运行这段代码,请从头开始执行,以免跑出不是自己要的结果。这部分是从数据的第三列开始取数据,如果要重新执行程序,要从开头开始,重新赋值data。
data = data.iloc[:, 3:]
data[data == 'NR'] = 0
raw_data = data.to_numpy()Extract Features(1)
数据预处理大概像以下图示:
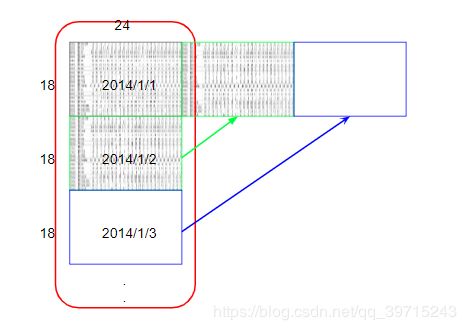
处理后的数据:

将原始4320*18的data依照每个月重组为12个18(feature)*480(hours)的data
month_data = {}
for month in range(12):
sample = np.empty([18,480]) #十八项测试数据,20天每天24小时,480小时
for day in range(20):
sample[:, day*24:(day+1)*24] = raw_data[18*(20*month+day):18*(20*month+day+1), :]
month_data[month] = sample Extract Features(2)
将上面处理好的数据,按以下图示每10小时为一组data:

每10个小时为一组数据,依次往后移一个单位,直至1个月完,每个月就有471组数据,所以总数据数为471*12组。每组数据前9个小时作为train_x,就有9*18个feature(一个小时18个feature)。每组数据第10个小时的pm2.5作为train_y。对应的目标(target)就有471*12个。
x = np.empty([12*471, 18*9], dtype = float)
y = np.empty([12*471, 1], dtype = float)
for month in range(12):
for day in range(20):
for hour in range(24):
if day == 19 and hour > 14:
continue
#把一个月的所有行(18行),每隔9列数据放成一行
x[month * 471 + day * 24 + hour, :] = month_data[month][:,day * 24 + hour : day * 24 + hour + 9].reshape(1, -1) #vector dim:18*9 (9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9)
#pm2.5那行数据
y[month * 471 + day * 24 + hour, 0] = month_data[month][9, day * 24 + hour + 9] #value
#print(month_data[0][:,0:9])# 1月1号0-8点18项数据,有18行
#print(x[0,:])# 1月1号0-8点18项数据,全部组成一行,只有一个list
#print(month_data[0][9,9]) # 1月1号9点pm2.5的数据
print(x)
print(y)Normalize(1)
mean_x = np.mean(x, axis = 0) #每列的平均值,就是把每天的同一个时间点的同一种数据做平均值
std_x = np.std(x, axis = 0) #每列的标准差,就是把每天的同一个时间点的同一种数据做标准差
for i in range(len(x)):
for j in range(len(x[0])):
if std_x[j] != 0:
x[i][j] = (x[i][j] - mean_x[j]) / std_x[j] #x的每一个数,减去当前列的平均数(mean函数),得到的差值除以当前列的标准差
#就是将同一种类型的数据调整范围区间,做归一化
xSplit Training Data Into "train_set" and "validation_set"
这部分是针对作业中report的第二题、第三题做的简单示范,以生成比较中用来训练的train_set和不会被放入训练、只是用来验证的validation__set。
import math
x_train_set = x[: math.floor(len(x)*0.8), :] #x的前80%用于训练集
y_train_set = y[: math.floor(len(y)*0.8), :] #y的前80%用于训练集
x_validation = x[math.floor(len(x) *0.8): , :] #x的后20%用于验证集
y_validation = y[math.floor(len(y) *0.8): , :] #y的后20%用于验证集
print(x_train_set)
print(y_train_set)
print(x_validation)
print(y_validation)
print(len(x_train_set))
print(len(y_train_set))
print(len(x_validation))
print(len(y_validation))Training
Implement linear regression
1. 声明权重向量,初始化lr(learning rate),然后 迭代
2. y` = train_x和权重向量的内积
3. Loss = y` - train_y
4. gradient = 2*np.dot((train_x)`, L) #这里的train_x经过转置
5. 权重向量 -= lr * gradient

Adagrad
1. 声明权重向量,初始化lr(learning rate),和 #迭代
在每一个前一次的迭代中声明prev_gra来存储gradient
2. y` = train_x和权重向量的内积
3. Loss = y` - train_y
4. gradient = 2*np.dot((train_x)`, L) #这里的train_x经过转置
prev_gra += gra**2
ada = np.sqrt(prev_gra) #np.sqrt求开平方
5. 权重向量 -= lr * gradient/ada
公式推导:

dim = 18*9+1 #dimension维度 因为常数项的存在,所以dimension需要多加一栏
w = np.zeros([dim, 1])
x = np.concatenate((np.ones([12 * 471, 1]), x), axis = 1).astype(float) #等式右边的x是归一化后的数据,np.ones([12*471, 1])为了与x的数据
learning_rate = 100
iter_time = 1000 #学习次数
adagrad = np.zeros([dim, 1])
eps = 0.0000000001 #为了避免adagrad的分母为0而加的极小数值
for t in range(iter_time):
loss = np.sqrt(np.sum(np.power(np.dot(x, w) - y, 2))/471/12) #rmse #loss的平方和再除以471除以12(471*12是总数据量)再开根号
if(t%100==0): #每训练100次打印一次loss值
print(str(t) + ":" + str(loss))
gradient = 2*np.dot(x.transpose(), np.dot(x, w) - y) #dim*1
adagrad += gradient ** 2
w = w - learning_rate * gradient / np.sqrt(adagrad + eps)
np.save('weight.npy', w)
wTesting
读test_x.csv文件
每18行:
test_x.append([1])
test_x.append(9-hr data)
test_y = np.dot(weight vector, test_x)
# testdata = pd.read_csv('gdrive/My Drive/hw1-regression/test.csv', header = None, encoding = 'big5')
testdata = pd.read_csv('./test.csv', header = None, encoding = 'big5')
test_data = testdata.iloc[:, 2:] #除去文件中第一列的‘id_'和名称,仅留数据
test_data[test_data == 'NR'] = 0 #将"NR"的数据改为0
test_data = test_data.to_numpy()
test_x = np.empty([240, 18*9], dtype = float) #18*9是feature的数据量, 240组数据,每组18*9个feature
for i in range(240):
test_x[i, :] = test_data[18*i : 18*(i+1), :].reshape(1, -1) #每隔18个数据为一行
for i in range(len(test_x)): #行
for j in range(len(test_x[0])): #列
if std_x[j] != 0:
test_x[i][j] = (test_x[i][j] - mean_x[j]) / std_x[j]
test_x = np.concatenate((np.ones([240, 1]), test_x), axis = 1).astype(float)
test_xPrediction
有了weight和测试资料即可预测target
w = np.load('weight.npy')
ans_y = np.dot(test_x, w)
ans_ySave Prediction to CSV File
import csv
with open('submit.csv', mode='w', newline='') as submit_file:
csv_writer = csv.writer(submit_file)
header = ['id', 'value']
print(header)
csv_writer.writerow(header)
for i in range(240):
row = ['id_' + str(i), ans_y[i][0]]
csv_writer.writerow(row)
print(row)