零基础用TensorFlow玩转Kaggle的“手写识别”
这是一个TensorFlow的系列文章,本文是第二篇,在这个系列中,你讲了解到机器学习的一些基本概念、TensorFlow的使用,并能实际完成手写数字识别、图像分类、风格迁移等实战项目。
文章将尽量用平实的语言描述、少用公式、多用代码截图,总之这将是一份很赞的入门指南。
今天将用TensorFlow实现一个手写数字识别功能,来展示TensorFlow如何用神经网络实现对图片的识别。google也为入门者提供了一个这样的例子,也就是TensorFlow里的“hello world”,这个例子的名字叫“MNIST”。
官方已经有了相应的文档,这里不是简单的翻译,而是以更通俗的语言来解释,为了让没有基础的同学也能看得懂,特别用简单的表述解释了一些专业名词,希望能有更多的人能接触到深度学习这个领域。
如果想看中文版本:MNIST机器学习入门,可以点下面的链接进行查看
http://wiki.jikexueyuan.com/project/tensorflow-zh/tutorials/mnist_beginners.html
如果是简单重复这个例子,就没什么意思了。正好“手写识别”在Kaggle上也有竞赛,我们使用Kaggle的数据进行识别和测试,这样和Google官方的例子虽然差不多,但又有不同。
手写图片识别的实现,分为三步:
一、数据的准备
二、模型的设计
三、代码实现
一、数据的准备
Kaggle里包含了42000份训练数据和28000份测试数据(和谷歌准备的MNIST数据,在数量上有所不同)。训练和测试数据的下载地址可以百度也可以点这里。下载下来是两个CVS文件。
![]()
Kaggle的数据都是表格形式的,和MNIST给的图片不一样。但实际上只是对图片的信息进行了处理,把一个28*28的图片信息,变成了28*28=784的一行数据。
为了便于理解,我们先来看MNIST的图片信息:
它每份的图片都是被规范处理过的,是一张被放在中间部位的灰度图。
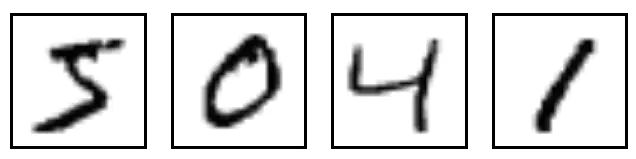
MNIST的图片集
类似这样的,每一个图片均为28×28像素,我们可以将其理解为一个二维数组的结构:
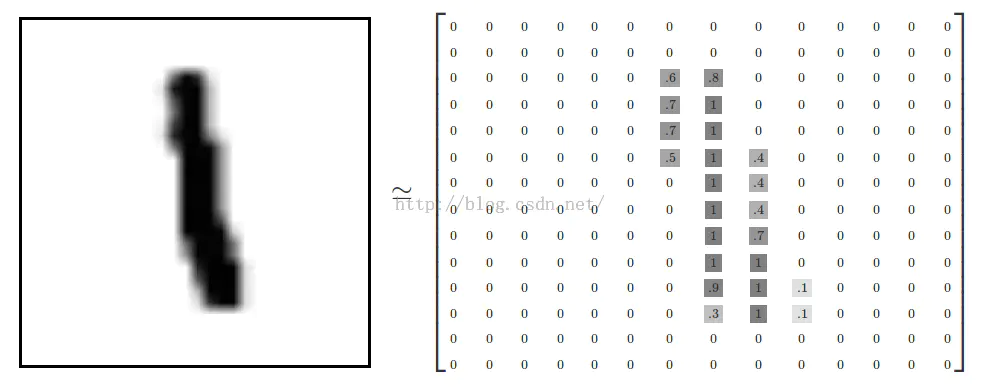
MNIST的图片解释
28*28 = 784,也就是说,这个二维数组可以转为一个784个数字组成的一维数组。
扁平化会丢失图片的二维结构信息,好的图形结构算法都会利用二维结构信息,但是为了简化过程便于理解,这里先使用这种一维结构来进行分析。
这样,上面的训练数据和测试数据,都可以分别转化为[42000,769]和[28000,768]的数组。
为什么训练数据会多一列呢?因为有一列存的是这个图片的结果。好我们继续来看图片:

Kaggle训练集的截图
这个图片上我们可以看出来,第一列是存的结果,后面784列存的是图片的像素信息,到这里,数据就准备好了。
下面我们进行模型的设计。
二、模型的设计
不想看理论的可以跳过这一步,直接进入代码环节
这个模型,组成是这样的:
1)使用一个最简单的单层的神经网络进行学习
2)用SoftMax来做为激活函数
3)用交叉熵来做损失函数
4)用梯度下降来做优化方式
这里有几个新的名词,神经网络、激活函数、SoftMax、损失函数、交叉熵、梯度下降,我们挨个解释一下。
神经网络:由很多个神经元组成,每个神经元接收很多个输入:[X1,X2....Xn],加权相加然后加上偏移量后,看是不是超过了某个阀值,超过了发出1,没超过发出0。
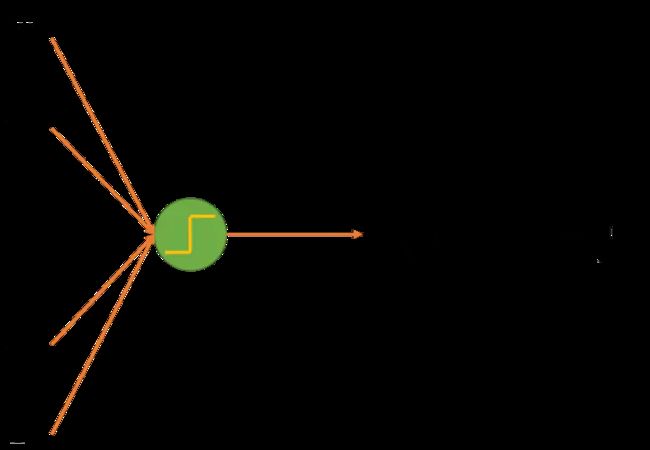
单个神经元
由很多个神经元互相连接,形成了神经网络。

神经网络
更详细的描述,可以查看知乎文章:
如何简单形象又有趣地讲解神经网络是什么?
激活函数:每个神经元,在通过一系列计算后,得到了一个数值,怎么来判断应该输出什么呢?激活函数就是解决这个问题,你把值给我,我来判断怎么输出。所以一个神经网络,激活函数是非常重要的。
想要成为激活函数,你得有两把刷子啊。这两把刷子是:一是你得处处可微,可微分才能求导,求极值。二是要非线性的,因为线性模型的表达能力不够。
线性的模型是这样的:
非线性的模型是这样的:
目前主流的几个激活函数是:sigmoid,tanh,ReLU。
sigmoid:采用S形函数,取值范围[0,1]
tanh:双切正切函数,取值范围[-1,1]
ReLU:简单而粗暴,大于0的留下,否则一律为0。
SoftMax:我们知道max(A,B)是指A和B里哪个大就取哪个值,但我们有时候希望比较小的那个也有一定概率取到,怎么办呢?我们就按照两个值的大小,计算出概率,按照这个概率来取A或者B。比如A=9,B=1,那取A的概率是90%,取B的概率是10%。
这个看起来比max(A,B)这样粗暴的方式柔和一些,所以叫SoftMax(名字解释纯属个人瞎掰?大家能理解概念就好)
损失函数:损失函数是模型对数据拟合程度的反映,拟合得越好损失应该越小,拟合越差损失应该越大,然后我们根据损失函数的结果对模型进行调整。
交叉熵:这个概念要解释的简单,那就不准确,如果要准确,那可能一千字都打不住。这里说一个简单但不一定准确的解释吧。
比如,你想把乾坤大挪移练到第七层大圆满,你现在是第五层,那你还差两层,这个两层就是你和大圆满之间的距离。交叉熵通俗的讲就是现在的训练程度和圆满之间的距离,我们希望距离越小越好,所以交叉熵可以作为一个损失函数,来衡量和目标之间的距离。
梯度下降:这个概念可以这样理解,我们要解决的问题是一座山,答案在山底,我们从山顶到山底的过程就是解决问题的过程。
在山顶,想找到最快的下山的路。这个时候,我们的做法是什么呢?在每次选择道路的时候,选最陡的那条路。梯度是改变率或者斜度的另一个称呼,用数学的语言解释是导数。对于求损失函数最小值这样的问题,朝着梯度下降的方向走,就能找到最优值了。
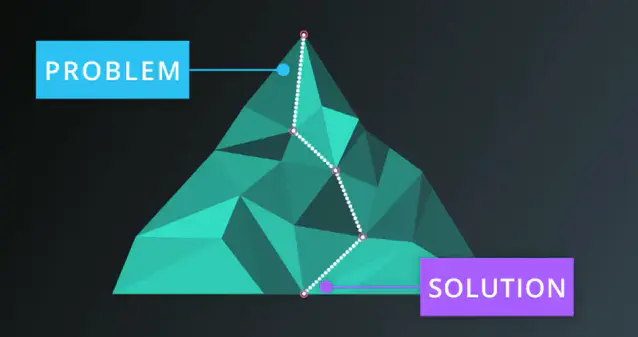
梯度下降
生僻的名词解释完了,咱们进入编程环节。
三、代码实现
1 载入数据,并对数据进行处理
在写代码的过程中,数据的预处理是最大的一块工作,做一个项目,60%以上的代码在做数据预处理。
这个项目的预处理,分为5步:
1)把输入和结果分开
2)对输入进行处理:把一维的输入变成28*28的矩阵
3)对结果进行处理:把结果进行One-Hot编码
4)把训练数据划分训练集和验证集
5)对训练集进行分批

查看tensorflow里面one_hot编码的实现,源码内容如下:
def dense_to_one_hot(labels_dense, num_classes):
"""Convert class labels from scalars to one-hot vectors."""
num_labels = labels_dense.shape[0]
index_offset = numpy.arange(num_labels) * num_classes
labels_one_hot = numpy.zeros((num_labels, num_classes))
labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1
return labels_one_hot
对函数进行理解:
1. 首先,labels_dense 必须是一个numpy里面的array类型的数据,因为要使用它的shape属性。
2. 一开始获取labels标签的数量,用于创建遍历时候的下标
3. 建立下标:idnex_offset该下标表表示的是一维时候每个labels的对应下标,如果把独热编码看作是一个散列链表(每个链表就是挂着10个元素的数组)的话,此时的index_offset就是一个桶的编号。
4. 创建one_hot矩阵。
5. 对one_hot矩阵的指定的位置进行赋值1的操作。
6. index_offset+labels_dense.ravel() 得到的是一个下标。
6. flat属性返回的是一个array的遍历对象,此时它是一维形式的。
7. ravel()返回的是一个副本,但是这个副本是原来数据的引用,有点类似于c++的引用。主要是减少存储空间的使用。返回的也是一个一维形式的数据。

处理完毕后,打印的结果是:

数据预处理的结果
数据预处理好了,如果不需要显示结果,可以把Print语句都去掉,不影响建模。
2 建立神经网络,设置损失函数,设置梯度下降的优化参数
这里只是最简单的一个实现,下篇文章我们会继续对网络进行优化

3 初始化变量,设置好准确度的计算方法,在Session中运行

训练模型
最后我们得到运行完50轮后的结果:

运行结果
我们这个网络识别的准确度是92%左右,这个成绩比较差,然而这只是我们最简单的模型而已,后面我会和大家对模型持续进行优化。