类vgg网络实现端到端识别验证码
项目起因
大二在做weibo爬虫抓取用于情感分析语料时遇到了模拟登陆的问题,其中关键的一环就是验证码识别。由于当时专业知识有限选择了对接打码平台来解决这个痛点,在时间不充分情况下这是效率最高的方法。但这也在我心中埋下了一个小小的种子。大二暑假在校同肖老师一同学习深度学习课程后,抱着学习的态度我把weibo验证码识别做为了我的软件工程课设题目同时也是我的第一个深度学习实战项目。
为什么采用端到端的方式
验证码的作用就是帮助网站过滤掉一部分恶意的流量,所以验证中加入了很多对字符的干扰例如粘连,空心, 加入背景,扭曲,旋转等。微博的验证码采用了空心和粘连的干扰方法,使用常规的分割算法验证码很难被有效的分割。采用端到端识别的方式避免了分割图像,经过简单的灰度处理后直接对原图像提取特征进行识别。
![]()
数据集和训练结果
由于数据集的特殊性目前网上没有找到公开的数据集,由于微博验证码字符采用大小写区分的方式而且一般的打码平台只提供大小写的不区分的打码服务(他们的后台用的是人工打码,即使提供打码服务可靠性也不高,你需要把图片上标注大小写区分工人看到了才会给你按照要求打码而且大部分工人来着网赚平台一般不会按照要求==)。 在一番苦苦搜寻无果后决定手动标验证码,这样数据集的质量也有保证。
目前的训练集大小是5000,由于数据获取困难我把绝大部分数据用来做训练集了只留了很小一部分用作验证集,模型训练结束的准确率在91%左右,但实际准确率应该比这个低,模型在新抓取的验证码上表现如下:

模型搭建
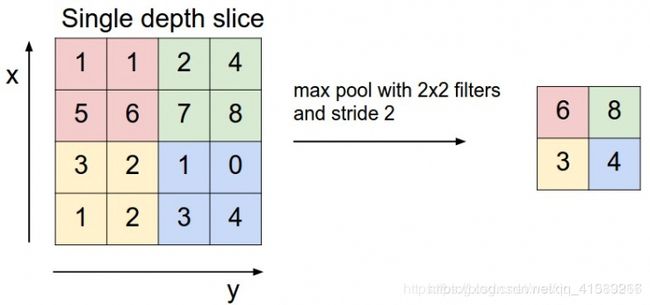
卷积与maxpooling
对卷积与maxpooling操作的个人理解:
由数据驱动的卷积神经网络在训练过程中逐层抽取到到由简单到复杂的特征。
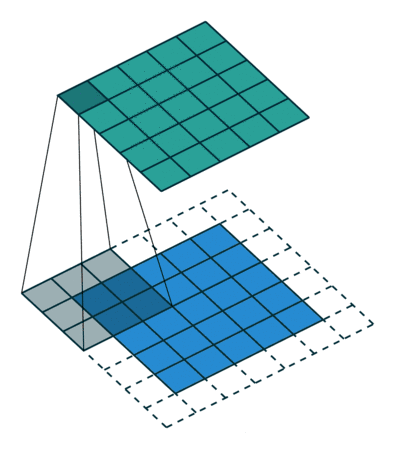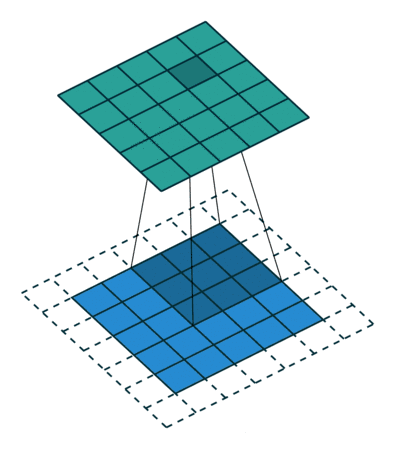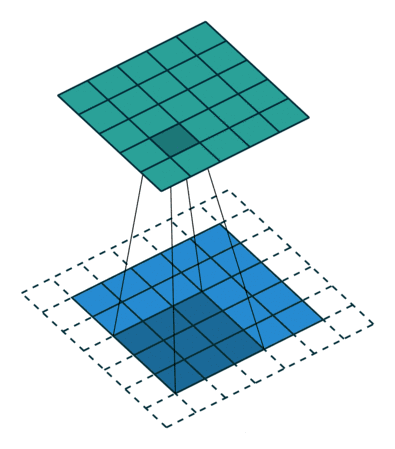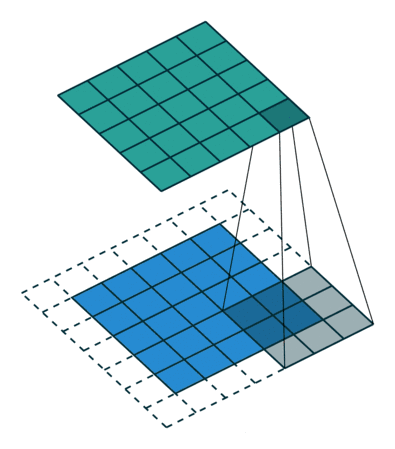
Maxpooling层与卷积的操作方式类似但作用不同,Maxpooing在每个小块内只取最大的值舍弃其他节点后,保持原有的平面结构得到输出。经过卷积后得到的数值可以理解为隐层特征,pooling的作用就是从这些特征中保留影响最大的(类似PCA),所以说pooling的一个重要作用就是降维。
Dropout
在网络结构过深时由于参数过多容易出现过拟和,dropou在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中随机丢弃由于只时暂时丢弃,故而相当于每一个mini-batch都在训练不同的网络,从而·
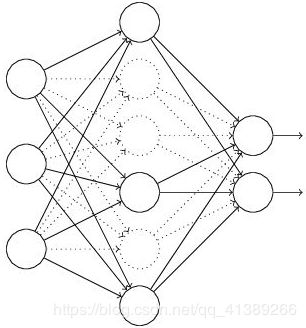
输出头
由于微博验证码采用的是五位字符,模型的输出头部采用了五个独立的Dense激活后再拼接而没有直接采用全连接,这样能大幅降低参数数量同时每个分支能学习到独立的识别特定位置的参数,这是端到端模型的关键。

由于代码过长这里只放部分模型搭建的关键代码:
class VGGNet(object):
@staticmethod
def conv_module(x, filters, cha_dim, l2_rate, name=None)
conv_name, bn_name = None, Non
if name is not None:
conv_name = name + "_conv"
bn_name = name + "_bn
x = Conv2D(filters, (3, 3), kernel_regularizer=l2(l2_rate), activation='relu', padding='same',
name=conv_name)(x)
x = BatchNormalization(axis=cha_dim, name=bn_name)(x)
return x
@staticmethod
def build(width, height, depth, conv_nums, filters, l2_rate)
input_shape = height, width, depth
chan_dim = -1
if K.image_data_format() == 'channels_first':
input_shape = depth, height, width
chan_dim = 1
input_image = Input(shape=input_shape)
layer = input_image
for block, (conv_num, filter) in enumerate(zip(conv_nums, filters)):
for stage in range(conv_num):
layer = VGGNet.conv_module(layer, filter, chan_dim, l2_rate,
name='block_{0}_stage_{1}'.format(block, stage))
if block == len(conv_nums) - 1:
layer = GlobalAveragePooling2D(K.image_data_format())(layer)
layer = Dropout(rate=0.5)(layer)
else:
layer = MaxPooling2D(pool_size=(2, 2))(layer)
layer = Dropout(rate=0.25)(layer)
# outputs
model = Model(inputs=input_image, outputs=layer)
return mode
另外我还尝试实现了ResNet用同样的数据集训练,得到的结果与vgg相差无几。个人觉得对于这种简单的图像处理问题模型的优势并不能很明显的体现应该以数据为王道,如果在现有的5000个图像的基础上加大训练集能该能得到更效果。
运行环境
操作系统:windows x64 8g内存
显卡:GTX1050
keras:2.24
tensorflow:1.12
python:3.6.9
使用gpu加速的化大概十几分钟就能train完,效率还是挺高的,感觉第二代图形验证码在防爬虫方面越来越吃力了,急需新型对抗验证码。
结语
第一次实战深度学习,经过不断努力终于做出了我想要的东西,自己已经满足了hhh
道阻且长 行则将至 行而不辍 未来可期
本文内容仅提供用于学习交流,如有侵权请联系[email protected]删除