ORM的映射机制与数据库
1、Django项目中使用MySQL数据库
1.1、在Django项目的settings.py文件中,配置数据库连接信息
DATABASES = {
"default": {
"ENGINE": "django.db.backends.mysql",
"NAME": "你的数据库名称", # 需要自己手动创建数据库
"USER": "数据库用户名",
"PASSWORD": "数据库密码",
"HOST": "数据库IP",
"POST": 3306
}
}1.2、在Django项目的__init__.py文件中写如下代码,告诉Django使用pymysql模块连接MySQL数据库
import pymysql
pymysql.install_as_MySQLdb()2、Django中的Model
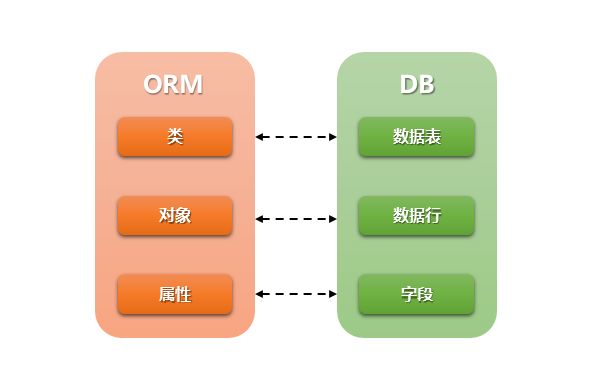
在Django中model是你数据的单一、明确的信息来源。它包含了你存储的数据的重要字段和行为。通常,一个模型(model)映射到一个数据库表,
基本情况:
- 每个模型都是一个Python类,它是django.db.models.Model的子类。
- 模型的每个属性都代表一个数据库字段。
3、Django ORM中常用字段和参数
3.1、常用字段
AutoField(Field)
- int自增列,必须填入参数 primary_key=True
BigAutoField(AutoField)
- bigint自增列,必须填入参数 primary_key=True
注:当model中如果没有自增列,则自动会创建一个列名为id的列
from django.db import models
class UserInfo(models.Model):
# 自动创建一个列名为id的且为自增的整数列
username = models.CharField(max_length=32)
class Group(models.Model):
# 自定义自增列
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
SmallIntegerField(IntegerField):
- 小整数 -32768 ~ 32767
PositiveSmallIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField)
- 正小整数 0 ~ 32767
IntegerField(Field)
- 整数列(有符号的) -2147483648 ~ 2147483647
PositiveIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField)
- 正整数 0 ~ 2147483647
BigIntegerField(IntegerField):
- 长整型(有符号的) -9223372036854775808 ~ 9223372036854775807
自定义无符号整数字段
class UnsignedIntegerField(models.IntegerField):
def db_type(self, connection):
return 'integer UNSIGNED'
PS: 返回值为字段在数据库中的属性,Django字段默认的值为:
'AutoField': 'integer AUTO_INCREMENT',
'BigAutoField': 'bigint AUTO_INCREMENT',
'BinaryField': 'longblob',
'BooleanField': 'bool',
'CharField': 'varchar(%(max_length)s)',
'CommaSeparatedIntegerField': 'varchar(%(max_length)s)',
'DateField': 'date',
'DateTimeField': 'datetime',
'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)',
'DurationField': 'bigint',
'FileField': 'varchar(%(max_length)s)',
'FilePathField': 'varchar(%(max_length)s)',
'FloatField': 'double precision',
'IntegerField': 'integer',
'BigIntegerField': 'bigint',
'IPAddressField': 'char(15)',
'GenericIPAddressField': 'char(39)',
'NullBooleanField': 'bool',
'OneToOneField': 'integer',
'PositiveIntegerField': 'integer UNSIGNED',
'PositiveSmallIntegerField': 'smallint UNSIGNED',
'SlugField': 'varchar(%(max_length)s)',
'SmallIntegerField': 'smallint',
'TextField': 'longtext',
'TimeField': 'time',
'UUIDField': 'char(32)',
BooleanField(Field)
- 布尔值类型
NullBooleanField(Field):
- 可以为空的布尔值
CharField(Field)
- 字符类型
- 必须提供max_length参数, max_length表示字符长度
TextField(Field)
- 文本类型
EmailField(CharField):
- 字符串类型,Django Admin以及ModelForm中提供验证机制
IPAddressField(Field)
- 字符串类型,Django Admin以及ModelForm中提供验证 IPV4 机制
GenericIPAddressField(Field)
- 字符串类型,Django Admin以及ModelForm中提供验证 Ipv4和Ipv6
- 参数:
protocol,用于指定Ipv4或Ipv6, 'both',"ipv4","ipv6"
unpack_ipv4, 如果指定为True,则输入::ffff:192.0.2.1时候,可解析为192.0.2.1,开启刺功能,需要protocol="both"
URLField(CharField)
- 字符串类型,Django Admin以及ModelForm中提供验证 URL
SlugField(CharField)
- 字符串类型,Django Admin以及ModelForm中提供验证支持 字母、数字、下划线、连接符(减号)
CommaSeparatedIntegerField(CharField)
- 字符串类型,格式必须为逗号分割的数字
UUIDField(Field)
- 字符串类型,Django Admin以及ModelForm中提供对UUID格式的验证
FilePathField(Field)
- 字符串,Django Admin以及ModelForm中提供读取文件夹下文件的功能
- 参数:
path, 文件夹路径
match=None, 正则匹配
recursive=False, 递归下面的文件夹
allow_files=True, 允许文件
allow_folders=False, 允许文件夹
FileField(Field)
- 字符串,路径保存在数据库,文件上传到指定目录
- 参数:
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage
ImageField(FileField)
- 字符串,路径保存在数据库,文件上传到指定目录
- 参数:
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage
width_field=None, 上传图片的高度保存的数据库字段名(字符串)
height_field=None 上传图片的宽度保存的数据库字段名(字符串)
DateTimeField(DateField)
- 日期+时间格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ]
DateField(DateTimeCheckMixin, Field)
- 日期格式 YYYY-MM-DD
TimeField(DateTimeCheckMixin, Field)
- 时间格式 HH:MM[:ss[.uuuuuu]]
DurationField(Field)
- 长整数,时间间隔,数据库中按照bigint存储,ORM中获取的值为datetime.timedelta类型
FloatField(Field)
- 浮点型
DecimalField(Field)
- 10进制小数
- 参数:
max_digits,小数总长度
decimal_places,小数位长度
BinaryField(Field)
- 二进制类型
字段附ORM字段与数据库实际字段的对应关系:
对应关系:
'AutoField': 'integer AUTO_INCREMENT',
'BigAutoField': 'bigint AUTO_INCREMENT',
'BinaryField': 'longblob',
'BooleanField': 'bool',
'CharField': 'varchar(%(max_length)s)',
'CommaSeparatedIntegerField': 'varchar(%(max_length)s)',
'DateField': 'date',
'DateTimeField': 'datetime',
'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)',
'DurationField': 'bigint',
'FileField': 'varchar(%(max_length)s)',
'FilePathField': 'varchar(%(max_length)s)',
'FloatField': 'double precision',
'IntegerField': 'integer',
'BigIntegerField': 'bigint',
'IPAddressField': 'char(15)',
'GenericIPAddressField': 'char(39)',
'NullBooleanField': 'bool',
'OneToOneField': 'integer',
'PositiveIntegerField': 'integer UNSIGNED',
'PositiveSmallIntegerField': 'smallint UNSIGNED',
'SlugField': 'varchar(%(max_length)s)',
'SmallIntegerField': 'smallint',
'TextField': 'longtext',
'TimeField': 'time',
'UUIDField': 'char(32)',
对应关系3.2、字段的参数
对应关系:
'AutoField': 'integer AUTO_INCREMENT',
'BigAutoField': 'bigint AUTO_INCREMENT',
'BinaryField': 'longblob',
'BooleanField': 'bool',
'CharField': 'varchar(%(max_length)s)',
'CommaSeparatedIntegerField': 'varchar(%(max_length)s)',
'DateField': 'date',
'DateTimeField': 'datetime',
'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)',
'DurationField': 'bigint',
'FileField': 'varchar(%(max_length)s)',
'FilePathField': 'varchar(%(max_length)s)',
'FloatField': 'double precision',
'IntegerField': 'integer',
'BigIntegerField': 'bigint',
'IPAddressField': 'char(15)',
'GenericIPAddressField': 'char(39)',
'NullBooleanField': 'bool',
'OneToOneField': 'integer',
'PositiveIntegerField': 'integer UNSIGNED',
'PositiveSmallIntegerField': 'smallint UNSIGNED',
'SlugField': 'varchar(%(max_length)s)',
'SmallIntegerField': 'smallint',
'TextField': 'longtext',
'TimeField': 'time',
'UUIDField': 'char(32)',
对应关系3.2、字段的参数
null 数据库中字段是否可以为空
db_column 数据库中字段的列名
db_index 如果db_index=True则代表着为此字段设置索引
db_tablespace
default 数据库中字段的默认值
primary_key 数据库中字段是否为主键
db_index 数据库中字段是否可以建立索引
unique 数据库中字段是否可以建立唯一索引
unique_for_date 数据库中字段【日期】部分是否可以建立唯一索引
unique_for_month 数据库中字段【月】部分是否可以建立唯一索引
unique_for_year 数据库中字段【年】部分是否可以建立唯一索引
verbose_name Admin中显示的字段名称
blank Admin中是否允许用户输入为空
editable Admin中是否可以编辑
help_text Admin中该字段的提示信息
choices Admin中显示选择框的内容,用不变动的数据放在内存中从而避免跨表操作
如:gf = models.IntegerField(choices=[(0, '何穗'),(1, '大表姐'),],default=1)
error_messages 自定义错误信息(字典类型),从而定制想要显示的错误信息;
字典健:null, blank, invalid, invalid_choice, unique, and unique_for_date
如:{'null': "不能为空.", 'invalid': '格式错误'}
validators 自定义错误验证(列表类型),从而定制想要的验证规则
from django.core.validators import RegexValidator
from django.core.validators import EmailValidator,URLValidator,DecimalValidator,\
MaxLengthValidator,MinLengthValidator,MaxValueValidator,MinValueValidator
如:
test = models.CharField(
max_length=32,
error_messages={
'c1': '优先错信息1',
'c2': '优先错信息2',
'c3': '优先错信息3',
},
validators=[
RegexValidator(regex='root_\d+', message='错误了', code='c1'),
RegexValidator(regex='root_112233\d+', message='又错误了', code='c2'),
EmailValidator(message='又错误了', code='c3'), ]
)
参数3.2.1、DateField和DateTimeField才有的参数
auto_now_add=True --> 创建数据的时候自动把当前时间赋值
auto_add=True --> 每次更新数据的时候更新当前时间
上述两个不能同时设置!!!
3.3、元信息
class UserInfo(models.Model):
nid = models.AutoField(primary_key=True)
username = models.CharField(max_length=32)
class Meta:
# 数据库中生成的表名称 默认 app名称 + 下划线 + 类名
db_table = "table_name"
# 联合索引
index_together = [
("pub_date", "deadline"),
]
# 联合唯一索引
unique_together = (("driver", "restaurant"),)
# admin中显示的表名称
verbose_name
# verbose_name加s
verbose_name_plural
更多:https://docs.djangoproject.com/en/1.10/ref/models/options/
元信息3.4、自定义字段
自定义IntegerField字段:
class UnsignedIntegerField(models.IntegerField):
def db_type(self, connection):
return 'integer UNSIGNED'class FixedCharField(models.Field):
"""
自定义的char类型的字段类
"""
def __init__(self, max_length, *args, **kwargs):
self.max_length = max_length
super(FixedCharField, self).__init__(max_length=max_length, *args, **kwargs)
def db_type(self, connection):
"""
限定生成数据库表的字段类型为char,长度为max_length指定的值
"""
return 'char(%s)' % self.max_length
class Class(models.Model):
id = models.AutoField(primary_key=True)
title = models.CharField(max_length=25)
# 使用自定义的char类型的字段
cname = FixedCharField(max_length=25)4、连接结构
- 一对多:models.ForeignKey(其他表)
- 多对多:models.ManyToManyField(其他表)
- 一对一:models.OneToOneField(其他表)
应用场景:
| 表结构 | 应用场景 | 举例 |
| 一对多 | 当一张表中创建一行数据时,有一个单选的下拉框(可以被重复选择) | 例如:创建用户信息时候,需要选择一个用户类型【普通用户】【金牌用户】【铂金用户】等。 |
| 多对多 | 在某表中创建一行数据是,有一个可以多选的下拉框 | 例如:创建用户信息,需要为用户指定多个爱好 |
| 一对一 | 在某表中创建一行数据时,有一个单选的下拉框(下拉框中的内容被用过一次就消失了 | 例如:原有含10列数据的一张表保存相关信息,经过一段时间之后,10列无法满足需求,需要为原来的表再添加5列数据 |
4.1、ForeignKey
外键类型在ORM中用来表示外键关联关系,一般把ForeignKey字段设置在 '一对多'中'多'的一方。ForeignKey可以和其他表做关联关系同时也可以和自身做关联关系。
4.2、MangToMangField
创建方式:
| 创建方式 | 优点 | 缺点 | 使用场景 |
| ORM自动创建第三张表 | 查询方便 | 如果第三张表没有额外的字段,使用这种方法 | |
| 利用外键自己创建第三张表 | 关联查询比较麻烦,因为没办法使用ORM提供的便利方法 | 第三张表有额外的字段 | |
| 自己创建第三张表,使用ORM 的ManyToManyFiled() | 使用此种方式创建多对多表的时候,没有 add() remove() 等方法 | 第三张表有额外的字段 |
4.3、OneToOneField
当 一张表的某一些字段查询的比较频繁,另外一些字段查询的不是特别频繁把不怎么常用的字段 单独拿出来做成一张表 然后用过一对一关联起来
优势:既保证数据都完整的保存下来,又能保证大部分的检索更快
5、使用ORM操作表
5.1、增
方式一
models.User.objects.create(name='qianxiaohu',age=18)
dic = {'name': 'xx', 'age': 19}
models.User.objects.create(**dic)方法二
obj = models.User(name='qianxiaohu',age=18)
obj.save()5.2、删
models.User.objects.filter(id=1).delete()5.3、改
models.User.objects.filter(id__gt=1).update(name='alex',age=84)
dic = {'name': 'xx', 'age': 19}
models.User.objects.filter(id__gt=1).update(**dic)5.4、查
models.User.objects.filter(id=1,name='root')
models.User.objects.filter(id__gt=1,name='root')
models.User.objects.filter(id__lt=1)
models.User.objects.filter(id__gte=1)
models.User.objects.filter(id__lte=1)
models.User.objects.filter(id=1,name='root')
dic = {'name': 'xx', 'age__gt': 19}
models.User.objects.filter(**dic)
v1 = models.Business.objects.all()
# QuerySet ,内部元素都是对象
# QuerySet ,内部元素都是字典
v2 = models.Business.objects.all().values('id','caption')
# QuerySet ,内部元素都是元组
v3 = models.Business.objects.all().values_list('id','caption')
# 获取到的一个对象,如果不存在就报错
models.Business.objects.get(id=1)
对象或者None = models.Business.objects.filter(id=1).first()
外键:
v = models.Host.objects.filter(nid__gt=0)
v[0].b.caption ----> 通过.进行跨表5.5、更多操作
"""
ORM小练习
如何在一个Python脚本或文件中 加载Django项目的配置和变量信息
"""
import os
if __name__ == '__main__':
# 加载Django项目的配置信息
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "ormday69.settings")
# 导入Django,并启动Django项目
import django
django.setup()
from app01 import models
# # 查询所有的人
# ret = models.Person.objects.all()
# print(ret)
# # get查询
# ret = models.Person.objects.get(name="小黑")
# print(ret)
# # filter
# ret = models.Person.objects.filter(id=100) # 不存在返回一个空的QuerySet,不会报错
# print(ret)
# # 就算查询的结果只有一个,返回的也是QuerySet,我们要用索引的方式取出第一个元素
# ret = models.Person.objects.filter(id=1)[0]
# print(ret)
# print("exclude".center(80, "*"))
# # exclude
# ret = models.Person.objects.exclude(id=1)
# print(ret)
# print("values".center(80, "*"))
# # values 返回一个QuerySet对象,里面都是字典。 不写字段名,默认查询所有字段
# ret = models.Person.objects.values("name", "birthday")
# print(ret)
# print("values_list".center(80, "*"))
# # values_list 返回一个QuerySet对象,里面都是元祖。 不写字段名,默认查询所有字段
# ret = models.Person.objects.values_list()
# print(ret)
# print("order_by".center(80, "*"))
# # order_by 按照指定的字段排序
# ret = models.Person.objects.all().order_by("birthday")
# print(ret)
# print("reverse".center(80, "*"))
# # reverse 将一个有序的QuerySet 反转顺序
# # 对有序的QuerySet才能调用reverse
# ret = models.Person.objects.all().reverse()
# print(ret)
# print("count".center(80, "*"))
# # count 返回QuerySet中对象的数量
# ret = models.Person.objects.all().count()
# print(ret)
# print("first".center(80, "*"))
# # first 返回QuerySet中第一个对象
# ret = models.Person.objects.all().first()
# print(ret)
# print("last".center(80, "*"))
# # last 返回QuerySet中最后一个对象
# ret = models.Person.objects.all().last()
# print(ret)
# print("exists".center(80, "*"))
# # exists 判断表里有没有数据
# ret = models.Book.objects.exists()
# print(ret)
# 单表查询之神奇的双下划线
# # 查询id值大于1小于4的结果
# ret = models.Person.objects.filter(id__gt=1, id__lt=4)
# print(ret)
# # in
# # 查询 id 在 [1, 3, 5, 7]中的结果
# ret = models.Person.objects.filter(id__in=[1, 3, 5, 7])
# print(ret)
# ret = models.Person.objects.exclude(id__in=[1, 3, 5, 7])
# print(ret)
# # contains 字段包含指定值的
# # icontains 忽略大小写包含指定值
# ret = models.Person.objects.filter(name__contains="小")
# print(ret)
# # range
# # 判断id值在 哪个区间的 SQL语句中的between and 1<= <=3
# ret = models.Person.objects.filter(id__range=[1,3])
# print(ret)
# # 日期和时间字段还可以有以下写法
# ret = models.Person.objects.filter(birthday__year=2000)
# print(ret)
# ret = models.Person.objects.filter(birthday__year=2000, birthday__month=5)
# print(ret)
# 外键的查询操作
# 正向查询
# 基于对象 跨表查询
# book_obj = models.Book.objects.all().first()
# ret = book_obj.publisher # 和我这本书关联的出版社对象
# print(ret, type(ret))
# ret = book_obj.publisher.name # 和我这本书关联的出版社对象
# print(ret, type(ret))
# 查询id是1的书的出版社的名称
# 利用双下划线 跨表查询
# 双下划线就表示跨了一张表
# ret = models.Book.objects.filter(id=1).values_list("publisher__name")
# print(ret)
# 反向查询
# 1. 基于对象查询
# publisher_obj = models.Publisher.objects.get(id=1) # 得到一个具体的对象
# # ret = publisher_obj.book_set.all()
# ret = publisher_obj.books.all()
# print(ret)
#
# # 2. 基于双下划线
# ret = models.Publisher.objects.filter(id=1).values_list("xxoo__title")
# print(ret)
# 多对多
# 查询
# author_obj = models.Author.objects.first()
# print(author_obj.name)
# 查询金老板写过的书
# ret = author_obj.books.all()
# print(author_obj.books, type(author_obj.books))
# print(ret)
# 1. create
# 通过作者创建一本书,会自动保存
# 做了两件事:
# 1. 在book表里面创建一本新书,2. 在作者和书的关系表中添加关联记录
# author_obj.books.create(title="金老板自传", publisher_id=2)
# 2. add
# 在金老板关联的书里面,再加一本id是4的书
# book_obj = models.Book.objects.get(id=4)
# author_obj.books.add(book_obj)
# 添加多个
# book_objs = models.Book.objects.filter(id__gt=5)
# author_obj.books.add(*book_objs) # 要把列表打散再传进去
# 直接添加id
# author_obj.books.add(9)
# remove
# 从金老板关联的书里面把 开飞船 删掉
# book_obj = models.Book.objects.get(title="跟金老板学开飞船")
# author_obj.books.remove(book_obj)
# 从金老板关联的书里面把 id是8的记录 删掉
# author_obj.books.remove(8)
# clear
# 清空
# 把景女神 关联的所有书都删掉
# jing_obj = models.Author.objects.get(id=2)
# jing_obj.books.clear()
# 额外补充的,外键的反向操作
# 找到id是1的出版社
# publisher_obj = models.Publisher.objects.get(id=2)
# publisher_obj.books.clear()
# 聚合
from django.db.models import Avg, Sum, Max, Min, Count
# ret = models.Book.objects.all().aggregate(price_avg=Avg("price"))
# print(ret)
#
# ret = models.Book.objects.all().aggregate(price_avg=Avg("price"), price_max=Max("price"), price_min=Min("price"))
# print(ret)
# print(ret.get("price_max"), type(ret.get("price_max")))
# 分组查询
# 查询每一本书的作者个数
# ret = models.Book.objects.all().annotate(author_num=Count("author"))
# # print(ret)
# for book in ret:
# print("书名:{},作者数量:{}".format(book.title, book.author_num))
# 查询作者数量大于1的书
# ret = models.Book.objects.all().annotate(author_num=Count("author")).filter(author_num__gt=1)
# print(ret)
# 查询各个作者出的书的总价格
# ret = models.Author.objects.all().annotate(price_sum=Sum("books__price")).values_list("name", "price_sum")
# ret = models.Author.objects.all().annotate(price_sum=Sum("books__price"))
# print(ret)
# for i in ret:
# print(i, i.name, i.price_sum)
# print(ret.values_list("id", "name", "price_sum"))
# F和Q
# ret = models.Book.objects.filter(price__gt=9.99)
# print(ret)
# 查询出 库存数 大于 卖出数的 所有书(两个字段做比较)
from django.db.models import F
# ret = models.Book.objects.filter(kucun__gt=F("maichu"))
# print(ret)
# 刷单 把每一本书的卖出数都乘以3
# obj = models.Book.objects.first()
# obj.maichu = 1000 * 3
# obj.save()
# 具体的对象没有update(),QuerySet对象才有update()方法。
# models.Book.objects.update(maichu=(F("maichu")+1)*3)
# 给每一本书的书名后面加上 第一版
# from django.db.models.functions import Concat
# from django.db.models import Value
#
# models.Book.objects.update(title=Concat(F("title"), Value("第一版")))
# Q查询
from django.db.models import Q
# 查询 卖出数大于1000,并且 价格小于100的所有书
# ret = models.Book.objects.filter(maichu__gt=1000, price__lt=100)
# print(ret)
# 查询 卖出数大于1000,或者 价格小于100的所有书
# ret = models.Book.objects.filter(Q(maichu__gt=1000) | Q(price__lt=100))
# print(ret)
# Q查询和字段查询同时存在时, 字段查询要放在Q查询的后面
# ret = models.Book.objects.filter(Q(maichu__gt=1000) | Q(price__lt=100), title__contains="金老板")
# print(ret)
# Django ORM 事务
# try:
# from django.db import transaction
#
# with transaction.atomic():
# # 先创建一个出版社
# new_publisher = models.Publisher.objects.create(name="火星出版社")
# # 创建一本书
# models.Book.objects.create(
# title="橘子物语",
# price=11.11,
# kucun=10,
# maichu=10,
# publisher_id=1000 # 指定一个不存在的出版社id)
# )
# except Exception as e:
# print(str(e))
# 没有指定原子操作
# try:
#
# # 先创建一个出版社
# new_publisher = models.Publisher.objects.create(name="火星出版社")
# # 创建一本书
# models.Book.objects.create(
# title="橘子物语",
# price=11.11,
# kucun=10,
# maichu=10,
# publisher_id=1000 # 指定一个不存在的出版社id
# )
# except Exception as e:
# print(str(e))
# 执行原生SQL
# 更高灵活度的方式执行原生SQL语句
# from django.db import connection
# cursor = connection.cursor() # cursor = connections['default'].cursor()
# cursor.execute("SELECT * from app01_book where id = %s", [1])
# ret = cursor.fetchone()
# print(ret)
# 在QuerSet查询的基础上自己指定其他的SQL语句(了解即可)
ret = models.Book.objects.extra(
# 把出版社计数 赋值给newid
select={'newid': 'select count(1) from app01_publisher where id>%s'},
select_params=[1, ],
where=["app01_book.id=%s"],
params=[1, ],
tables=['app01_publisher']
)
print(ret)
for i in ret:
print(i)