精心整理170道Python面试题,建议先收藏(二)
简介: 精心整理170道Python面试题,建议先收藏(二)
51. 字符串格式化方式
- 使用 % 操作符
print("This is for %s" % "Python")
print("This is for %s, and %s" %("Python", "You"))
output
This is for Python This is for Python, and You
- str.format
在 Python3 中,引入了这个新的字符串格式化方法
print("This is my {}".format("chat"))
print("This is {name}, hope you can {do}".format(name="zhouluob", do="like"))
output
This is my chat This is zhouluob, hope you can like
- f-strings
在 Python3-6 中,引入了这个新的字符串格式化方法
name = "luobodazahui"
print(f"hello {name}")
output
hello luobodazahui
一个复杂些的例子:
def mytest(name, age):
return f"hello {name}, you are {age} years old!"
people = mytest("luobo", 20)
print(people)
output
hello luobo, you are 20 years old!
52. 将"hello world"转换为首字母大写"Hello World"(不使用 title 函数)
str1 = "hello world"
print(str1.title())
" ".join(list(map(lambda x: x.capitalize(), str1.split(" "))))
output
Hello World 'Hello World'
53. 一行代码转换列表中的整数为字符串
如:[1, 2, 3] -> ["1", "2", "3"]
list1 = [1, 2, 3] list(map(lambda x: str(x), list1))
output
['1', '2', '3']
54. 合并两个元组到字典
如:("zhangfei", "guanyu"),(66, 80) -> {'zhangfei': 66, 'guanyu': 80}
a = ("zhangfei", "guanyu")
b = (66, 80)
dict(zip(a,b))
output
{'zhangfei': 66, 'guanyu': 80}
55. 给出如下代码的输入,并简单解释
例子1:
a = (1,2,3,[4,5,6,7],8) a[3] = 2
output
--------------------------------------------------------------------------- TypeError Traceback (most recent call last)in 1 a = (1,2,3,[4,5,6,7],8) ----> 2 a[3] = 2 3 #a TypeError: 'tuple' object does not support item assignment
例子2:
a = (1,2,3,[4,5,6,7],8) a[3][2] = 2 a
output
(1, 2, 3, [4, 5, 2, 7], 8)
从例子1的报错中也可以看出,tuple 是不可变类型,不能改变 tuple 里的元素,例子2中,list 是可变类型,改变其元素是允许的
56. Python 中的反射
反射就是通过字符串的形式,导入模块;通过字符串的形式,去模块寻找指定函数,并执行。利用字符串的形式去对象(模块)中操作(查找/获取/删除/添加)成员,一种基于字符串的事件驱动!
简单理解就是用来判断某个字符串是什么,是变量还是方法
class NewClass(object):
def __init__(self, name, male):
self.name = name
self.male = male
def myname(self):
print(f'My name is {self.name}')
def mymale(self):
print(f'I am a {self.male}')
people = NewClass('luobo', 'boy')
print(hasattr(people, 'name'))
print(getattr(people, 'name'))
setattr(people, 'male', 'girl')
print(getattr(people, 'male'))
output
True luobo girl
getattr,hasattr,setattr,delattr 对模块的修改都在内存中进行,并不会影响文件中真实内容
57. 实现一个简单的 API
使用 flask 构造 web 服务器
from flask import Flask, request
app = Flask(__name__)
@app.route('/', methods=['POST'])
def simple_api():
result = request.get_json()
return result
if __name__ == "__main__":
app.run()
58. metaclass 元类
类与实例:
首先定义类以后,就可以根据这个类创建出实例,所以:先定义类,然后创建实例
类与元类:
先定义元类, 根据 metaclass 创建出类,所以:先定义 metaclass,然后创建类
class MyMetaclass(type):
def __new__(cls, class_name, class_parents, class_attr):
class_attr['print'] = "this is my metaclass's subclass %s" %class_name
return type.__new__(cls, class_name, class_parents, class_attr)
class MyNewclass(object, metaclass=MyMetaclass):
pass
myinstance = MyNewclass()
myinstance.print
output
"this is my metaclass's subclass MyNewclass"
59. sort 和 sorted 的区别
sort() 是可变对象列表(list)的方法,无参数,无返回值,sort() 会改变可变对象
dict1 = {'test1':1, 'test2':2}
list1 = [2, 1, 3]
print(list1.sort())
list1
output
None [1, 2, 3]
sorted() 是产生一个新的对象。sorted(L) 返回一个排序后的L,不改变原始的L,sorted() 适用于任何可迭代容器
dict1 = {'test1':1, 'test2':2}
list1 = [2, 1, 3]
print(sorted(dict1))print(sorted(list1))
output
['test1', 'test2'] [1, 2, 3]
60. Python 中的 GIL
GIL 是 Python 的全局解释器锁,同一进程中假如有多个线程运行,一个线程在运行 Python 程序的时候会占用 Python 解释器(加了一把锁即 GIL),使该进程内的其他线程无法运行,等该线程运行完后其他线程才能运行。如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。所以在多线程中,线程的运行仍是有先后顺序的,并不是同时进行
61. 产生8位随机密码
import random "".join(random.choice(string.printable[:-7]) for i in range(8))
output
'd5^NdNJp'
62. 输出原始字符
print('hello\nworld')
print(b'hello\nworld')
print(r'hello\nworld')
output
hello world b'hello\nworld' hello\nworld
63. 列表内,字典按照 value 大小排序
list1 = [{'name': 'guanyu', 'age':29},
{'name': 'zhangfei', 'age': 28},
{'name': 'liubei', 'age':31}]
sorted(list1, key=lambda x:x['age'])
output
[{'name': 'zhangfei', 'age': 28},
{'name': 'guanyu', 'age': 29},
{'name': 'liubei', 'age': 31}]
64. 简述 any() 和 all() 方法
all 如果存在 0 Null False 返回 False,否则返回 True;any 如果都是 0,None,False,Null 时,返回 True
print(all([1, 2, 3, 0])) print(all([1, 2, 3])) print(any([1, 2, 3, 0])) print(any([0, None, False]))
output
False True True False
65. 反转整数
def reverse_int(x):
if not isinstance(x, int):
return False
if -10 < x < 10:
return x
tmp = str(x)
if tmp[0] != '-':
tmp = tmp[::-1]
return int(tmp)
else:
tmp = tmp[1:][::-1]
x = int(tmp)
return -x
reverse_int(-23837)
output
-73832
首先判断是否是整数,再判断是否是一位数字,最后再判断是不是负数
66. 函数式编程
函数式编程是一种抽象程度很高的编程范式,纯粹的函数式编程语言编写的函数没有变量,因此,任意一个函数,只要输入是确定的,输出就是确定的,这种纯函数称之为没有副作用。而允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入,可能得到不同的输出,因此,这种函数是有副作用的。由于 Python 允许使用变量,因此,Python 不是纯函数式编程语言
函数式编程的一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数!
函数作为返回值例子:
def sum(*args):
def inner_sum():
tmp = 0
for i in args:
tmp += i
return tmp
return inner_sum
mysum = sum(2, 4, 6)
print(type(mysum))
mysum()
output
12
67. 简述闭包
如果在一个内部函数里,对在外部作用域(但不是在全局作用域)的变量进行引用,那么内部函数就被认为是闭包(closure) 附上函数作用域图片
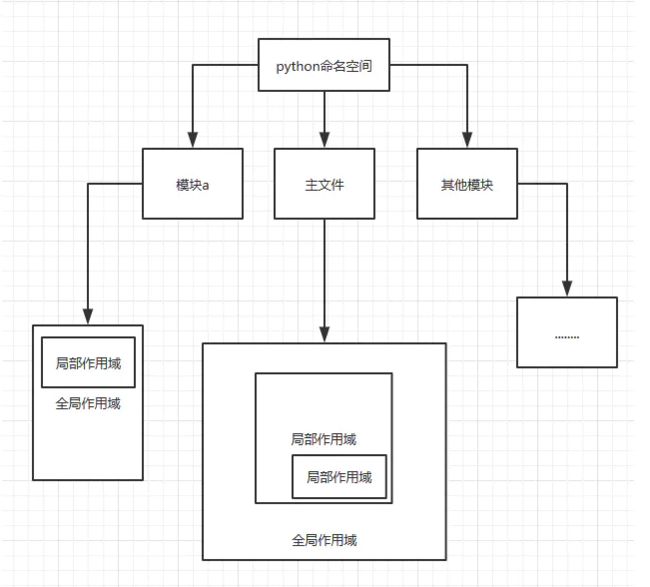
闭包特点
1.必须有一个内嵌函数
2.内嵌函数必须引用外部函数中的变量
3.外部函数的返回值必须是内嵌函数
68. 简述装饰器
装饰器是一种特殊的闭包,就是在闭包的基础上传递了一个函数,然后覆盖原来函数的执行入口,以后调用这个函数的时候,就可以额外实现一些功能了
一个打印 log 的例子:
import time
def log(func):
def inner_log(*args, **kw):
print("Call: {}".format(func.__name__))
return func(*args, **kw)
return inner_log
@log
def timer():
print(time.time())
timer()
output
Call: timer 1560171403.5128365
本质上,decorator就是一个返回函数的高阶函数
69. 协程的优点
子程序切换不是线程切换,而是由程序自身控制
没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显
不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁
70. 实现一个斐波那契数列
斐波那契数列:
又称黄金分割数列,指的是这样一个数列:1、1、2、3、5、8、13、21、34、……在数学上,斐波纳契数列以如下被以递归的方法定义:F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)(n>=2,n∈N*)
生成器法:
def fib(n):
if n == 0:
return False
if not isinstance(n, int) or (abs(n) != n): # 判断是正整数
return False
a, b = 0, 1
while n:
a, b = b, a+b
n -= 1
yield a
[i for i in fib(10)]
output
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
递归法:
def fib(n):
if n == 0:
return False
if not isinstance(n, int) or (abs(n) != n):
return False
if n <= 1:
return n
return fib(n-1)+ fib(n-2)
[fib(i) for i in range(1, 11)]
output
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
71. 正则切分字符串
import re str1 = 'hello world:luobo dazahui' result = re.split(r":| ", str1) print(result)
output
['hello', 'world', 'luobo', 'dazahui']
72. yield 用法
yield 是用来生成迭代器的语法,在函数中,如果包含了 yield,那么这个函数就是一个迭代器。当代码执行至 yield 时,就会中断代码执行,直到程序调用 next() 函数时,才会在上次 yield 的地方继续执行
def foryield():
print("start test yield")
while True:
result = yield 5
print("result:", result)
g = foryield()
print(next(g))
print("*"*20)
print(next(g))
output
start test yield 5 ******************** result: None 5
可以看到,第一个调用 next() 函数,程序只执行到了 "result = yield 5" 这里,同时由于 yield 中断了程序,所以 result 也没有被赋值,所以第二次执行 next() 时,result 是 None
73. 冒泡排序
list1 = [2, 5, 8, 9, 3, 11]
def paixu(data, reverse=False):
if not reverse:
for i in range(len(data) - 1):
for j in range(len(data) - 1 - i):
if data[j] > data[j+1]:
data[j], data[j+1] = data[j+1], data[j]
return data
else:
for i in range(len(data) - 1):
for j in range(len(data) - 1 - i):
if data[j] < data[j+1]:
data[j], data[j+1] = data[j+1], data[j]
return data
print(paixu(list1, reverse=True))
output
[11, 9, 8, 5, 3, 2]
74. 快速排序
快排的思想:首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序,之后再递归排序两边的数据
挑选基准值:从数列中挑出一个元素,称为"基准"(pivot)
分割:重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(与基准值相等的数可以到任何一边)
在这个分割结束之后,对基准值的排序就已经完成
递归排序子序列:递归地将小于基准值元素的子序列和大于基准值元素的子序列排序
list1 = [8, 5, 1, 3, 2, 10, 11, 4, 12, 20]
def partition(arr,low,high):
i = ( low-1 ) # 最小元素索引
pivot = arr[high]
for j in range(low , high):
# 当前元素小于或等于 pivot
if arr[j] <= pivot:
i = i+1
arr[i],arr[j] = arr[j],arr[i]
arr[i+1],arr[high] = arr[high],arr[i+1]
return ( i+1 )
def quicksort(arr,low,high):
if low < high:
pi = partition(arr,low,high)
quicksort(arr, low, pi-1)
quicksort(arr, pi+1, high)
quicksort(list1, 0, len(list1)-1)
print(list1)
output
[1, 2, 3, 4, 5, 8, 10, 11, 12, 20]
75. requests 简介
该库是发起 HTTP 请求的强大类库,调用简单,功能强大
import requests
url = "http://www.luobodazahui.top"
response = requests.get(url) # 获得请求
response.encoding = "utf-8" # 改变其编码
html = response.text # 获得网页内容
binary__content = response.content # 获得二进制数据
raw = requests.get(url, stream=True) # 获得原始响应内容
headers = {'user-agent': 'my-test/0.1.1'} # 定制请求头
r = requests.get(url, headers=headers)
cookies = {"cookie": "# your cookie"} # cookie的使用
r = requests.get(url, cookies=cookies)
76. 比较两个 json 数据是否相等
dict1 = {"zhangfei": 12, "guanyu": 13, "liubei": 18}
dict2 = {"zhangfei": 12, "guanyu": 13, "liubei": 18}
def compare_dict(dict1, dict2):
issame = []
for k in dict1.keys():
if k in dict2:
if dict1[k] == dict2[k]:
issame.append(1)
else:
issame.append(2)
else:
issame.append(3)
print(issame)
sum_except = len(issame)
sum_actually = sum(issame)
if sum_except == sum_actually:
print("this two dict are same!")
return True
else:
print("this two dict are not same!")
return False
test = compare_dict(dict1, dict2)
output
[1, 1, 1] this two dict are same!
77. 读取键盘输入
input() 函数
def forinput():
input_text = input()
print("your input text is: ", input_text)
forinput()
output
hello your input text is: hello
78. enumerate
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中
data1 = ['one', 'two', 'three', 'four']
for i, enu in enumerate(data1):
print(i, enu)
output
0 one 1 two 2 three 3 four
79. pass 语句
pass 是空语句,是为了保持程序结构的完整性。pass 不做任何事情,一般用做占位语句
def forpass(n):
if n == 1:
pass
else:
print('not 1')
forpass(1)
80. 正则匹配邮箱
import re email_list= ["[email protected]","[email protected]", "[email protected]", "[email protected]" ] for email in email_list: ret = re.match("[\w]{4,20}@(.*)\.com$",email) if ret: print("%s 是符合规定的邮件地址,匹配后结果是:%s" % (email,ret.group())) else: print("%s 不符合要求" % email)
output
[email protected] 是符合规定的邮件地址,匹配后结果是:[email protected] [email protected] 不符合要求 [email protected] 不符合要求 [email protected] 是符合规定的邮件地址,匹配后结果是:[email protected]
81. 统计字符串中大写字母的数量
str2 = 'werrQWSDdiWuW'
counter = 0
for i in str2:
if i.isupper():
counter += 1
print(counter)
output
6
82. json 序列化时保留中文
普通序列化:
import json
dict1 = {'name': '萝卜', 'age': 18}
dict1_new = json.dumps(dict1)
print(dict1_new)
output
{"name": "\u841d\u535c", "age": 18}
保留中文
import json
dict1 = {'name': '萝卜', 'age': 18}
dict1_new = json.dumps(dict1, ensure_ascii=False)
print(dict1_new)
output
{"name": "萝卜", "age": 18}
83. 简述继承
一个类继承自另一个类,也可以说是一个孩子类/派生类/子类,继承自父类/基类/超类,同时获取所有的类成员(属性和方法)
继承使我们可以重用代码,并且还可以更方便地创建和维护代码
Python 支持以下类型的继承:
单继承- 一个子类类继承自单个基类
多重继承- 一个子类继承自多个基类
多级继承- 一个子类继承自一个基类,而基类继承自另一个基类
分层继承- 多个子类继承自同一个基类
混合继承- 两种或两种以上继承类型的组合
84. 什么是猴子补丁
猴子补丁是指在运行时动态修改类和模块
猴子补丁主要有以下几个用处:
在运行时替换方法、属性等
在不修改第三方代码的情况下增加原来不支持的功能
在运行时为内存中的对象增加 patch 而不是在磁盘的源代码中增加
85. help() 函数和 dir() 函数
help() 函数返回帮助文档和参数说明:
help(dict)
output
Help on class dict in module builtins:
class dict(object)
| dict() -> new empty dictionary
| dict(mapping) -> new dictionary initialized from a mapping object's
| (key, value) pairs
| dict(iterable) -> new dictionary initialized as if via:
| d = {}
| for k, v in iterable:
| d[k] = v
| dict(**kwargs) -> new dictionary initialized with the name=value pairs
| in the keyword argument list. For example: dict(one=1, two=2)
......
dir() 函数返回对象中的所有成员 (任何类型)
dir(dict)
output
['__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', ......
86. 解释 Python 中的//,%和**运算符
// 运算符执行地板除法,返回结果的整数部分 (向下取整)
% 是取模符号,返回除法后的余数
** 符号表示取幂. a**b 返回 a 的 b 次方
print(5//3) print(5/3) print(5%3) print(5**3)
output
1 1.6666666666666667 2 125
87. 主动抛出异常
使用 raise
def test_raise(n):
if not isinstance(n, int):
raise Exception('not a int type')
else:
print('good')
test_raise(8.9)
output
--------------------------------------------------------------------------- Exception Traceback (most recent call last)in 4 else: 5 print('good') ----> 6 test_raise(8.9) in test_raise(n) 1 def test_raise(n): 2 if not isinstance(n, int): ----> 3 raise Exception('not a int type') 4 else: 5 print('good') Exception: not a int type
88. tuple 和 list 转换
tuple1 = (1, 2, 3, 4) list1 = list(tuple1) print(list1) tuple2 = tuple(list1) print(tuple2)
output
[1, 2, 3, 4](1, 2, 3, 4)
89. 简述断言
Python 的断言就是检测一个条件,如果条件为真,它什么都不做;反之它触发一个带可选错误信息的 AssertionError
def testassert(n):
assert n == 2, "n is not 2"
print('n is 2')
testassert(1)
output
--------------------------------------------------------------------------- AssertionError Traceback (most recent call last)in 2 assert n == 2, "n is not 2" 3 print('n is 2') ----> 4 testassert(1) in testassert(n) 1 def testassert(n): ----> 2 assert n == 2, "n is not 2" 3 print('n is 2') 4 testassert(1) AssertionError: n is not 2
90. 什么是异步非阻塞
同步异步指的是调用者与被调用者之间的关系
所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不会返回,一旦调用返回,就得到了返回值
异步的概念和同步相对,调用在发出之后,这个调用就直接返回了,所以没有返回结果。当该异步功能完成后,被调用者可以通过状态、通知或回调来通知调用者
阻塞非阻塞是线程或进程之间的关系
阻塞调用是指调用结果返回之前,当前线程会被挂起(如遇到io操作)。调用线程只有在得到结果之后才会返回。函数只有在得到结果之后才会将阻塞的线程激活
非阻塞和阻塞的概念相对应,非阻塞调用指在不能立刻得到结果之前也会立刻返回,同时该函数不会阻塞当前线程
91. 什么是负索引
Python 中的序列是有索引的,它由正数和负数组成。正的数字使用'0'作为第一个索引,'1'作为第二个索引,以此类推
负数的索引从'-1'开始,表示序列中的最后一个索引,' - 2'作为倒数第二个索引,依次类推
92. 退出 Python 后,内存是否全部释放
不是的,那些具有对象循环引用或者全局命名空间引用的变量,在 Python 退出时往往不会被释放
另外不会释放 C 库保留的部分内容
93. Flask 和 Django 的异同
Flask 是 “microframework”,主要用来编写小型应用程序,不过随着 Python 的普及,很多大型程序也在使用 Flask。同时,在 Flask 中,我们必须使用外部库
Django 适用于大型应用程序。它提供了灵活性,以及完整的程序框架和快速的项目生成方法。可以选择不同的数据库,URL结构,模板样式等
94. 创建删除操作系统上的文件
import os
f = open('test.txt', 'w')
f.close()
os.listdir()
os.remove('test.txt')
95. 简述 logging 模块
logging 模块是 Python 内置的标准模块,主要用于输出运行日志,可以设置输出日志的等级、日志保存路径、日志文件回滚等;相比 print,具备如下优点:
可以通过设置不同的日志等级,在 release 版本中只输出重要信息,而不必显示大量的调试信息
print 将所有信息都输出到标准输出中,严重影响开发者从标准输出中查看其它数据;logging 则可以由开发者决定将信息输出到什么地方,以及怎么输出
简单配置:
import logging
logging.debug("debug log")
logging.info("info log")
logging.warning("warning log")
logging.error("error log")
logging.critical("critica log")
output
WARNING:root:warning log ERROR:root:error log CRITICAL:root:critica log
默认情况下,只显示了大于等于WARNING级别的日志。logging.basicConfig()函数调整日志级别、输出格式等
96. 统计字符串中单词出现次数
from collections import Counter str1 = "nihsasehndciswemeotpxc" print(Counter(str1))
output
Counter({'s': 3, 'e': 3, 'n': 2, 'i': 2, 'h': 2, 'c': 2, 'a': 1, 'd': 1, 'w': 1, 'm': 1, 'o': 1, 't': 1, 'p': 1, 'x': 1})
97. 正则 re.complie 的作用
re.compile 是将正则表达式编译成一个对象,加快速度,并重复使用
98. try except else finally 的意义
try..except..else 没有捕获到异常,执行 else 语句
try..except..finally 不管是否捕获到异常,都执行 finally 语句
99.反转列表
使用切片:
$ python -m timeit -n 1000000 -s 'import numpy as np' 'mylist=list(np.arange(0, 200))' 'mylist[::-1]' 1000000 loops, best of 5: 15.6 usec per loop
使用 reverse():
$ python -m timeit -n 1000000 -s 'import numpy as np' 'mylist=list(np.arange(0, 200))' 'mylist.reverse()' 1000000 loops, best of 5: 10.7 usec per loop
这两种方法都可以反转列表,但需要注意的是内置函数 reverse() 会更改原始列表,而切片方法会创建一个新列表。
显然,内置函数 reverse() 比列表切片方法更快!
100. 字符串中数字替换
使用 re 正则替换
import re str1 = '我是周萝卜,今年18岁' result = re.sub(r"\d+","20",str1) print(result)
output
我是周萝卜,今年20岁
综合篇:网络编程
101. 简述 OSI 七层协议
是网络传输协议,人为的把网络传输的不同阶段划分成不同的层次
七层划分为:应用层、表示层、会话层、传输层、网络层、数据链路层、物理层
五层划分为:应用层、传输层、网络层、数据链路层、物理层
物理层:网线,电缆等物理设备
数据链路层:Mac 地址
网络层:IP 地址
传输层:TCP,UDP 协议
应用层:FTP 协议,Email,WWW 等
102. 三次握手、四次挥手的流程
都发生在传输层
三次握手:
TCP 协议是主机对主机层的传输控制协议,提供可靠的连接服务,采用三次握手确认建立一个连接。TCP 标志位(位码),有6种标示:SYN(synchronous建立联机) ACK(acknowledgement 确认) PSH(push传送) FIN(finish结束) RST(reset重置) URG(urgent紧急) Sequence number(顺序号码) Acknowledge number(确认号码) 第一次握手:主机 A 发送位码为 syn=1,随机产生 seq number=1234567 的数据包到服务器,并进入 SYN_SEND 状态,主机 B 由 SYN=1 知道,A 要求建立联机
第二次握手:主机 B 收到请求后要确认联机信息,向 A 发送 ack number=(主机 A 的 seq+1),syn=1,ack=1,随机产生 seq=7654321 的包,并进入 SYN_RECV 状态
第三次握手:主机 A 收到后检查 ack number 是否正确,即第一次发送的 seq number+1,以及位码 ack 是否为 1,若正确,主机 A 会再发送 ack number=(主机 B 的 seq+1),ack=1,主机 B 收到后确认 seq 值与 ack=1 则连接建立成功,两个主机均进入 ESTABLISHED 状态
以上完成三次握手,主机 A 与主机 B 开始传送数据
四次挥手:
因为 TCP 连接是全双工的,因此每个方向都必须单独进行关闭。这个原则是当一方完成它的数据发送任务后就能发送一个 FIN 来终止这个方向的连接。收到一个 FIN 只意味着这一方向上没有数据流动,一个 TCP 连接在收到一个 FIN 后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭
服务器 A 发送一个 FIN,用来关闭 A 到服务器 B 的数据传送。服务器 B 收到这个 FIN,它发回一个 ACK,确认序号为收到的序号加1。和 SYN 一样,一个 FIN 将占用一个序号
服务器 B 关闭与服务器 A 的连接,发送一个 FIN 给服务器 A
服务器 A 发回 ACK 报文确认,并将确认序号设置为收到序号加1
103. 什么是 C/S 和 B/S 架构
B/S 又称为浏览器/服务器模式。比如各种网站,jupyter notebook 等。优点:零安装,维护简单,共享性好。缺点:安全性较差,个性化不足
C/S 又称为客户端/服务器模式。比如微信客户端,Oracle 客户端等。优点:安全性好,数据传输较快,稳定。缺点:对 PC 机操作系统等有要求,当客户端较多时,服务器端负载较大
104. TCP 和 UDP 的区别
TCP 和 UDP 都是 OSI 模型中运输层的协议。TCP 提供可靠的通信传输,而 UDP 则常被用于广播和细节控制交给应用的通信传输。UDP 不提供复杂的控制机制,利用 IP 提供面向无连接的通信服务。TCP 充分实现了数据传输时各种控制功能,可以进行丢包的重发控制,还可以对次序乱掉的分包进行顺序控制
TCP 应用:FTP 传输,点对点短信等
UDP 应用:媒体流等
105. 局域网和广域网
广域网(WAN,Wide Area Network)也称远程网(long haul network )。通常跨接很大的物理范围,所覆盖的范围从几十公里到几千公里,它能连接多个城市或国家,或横跨几个洲并能提供远距离通信,形成国际性的远程网络
域网(Local Area Network,LAN)是指在某一区域内由多台计算机互联成的计算机组。一般是方圆几千米以内。局域网可以实现文件管理、应用软件共享、打印机共享、工作组内的日程安排、电子邮件和传真通信服务等功能。局域网是封闭型的,可以由办公室内的两台计算机组成,也可以由一个公司内的上千台计算机组成
106. arp 协议
ARP(Address Resolution Protocol)即地址解析协议, 用于实现从 IP 地址到 MAC 地址的映射,即询问目标 IP 对应的 MAC 地址
107. 什么是 socket?简述基于 TCP 协议的套接字通信流程
socket 是对 TCP/IP 协议的封装,它的出现只是使得程序员更方便地使用 TCP/IP 协议栈而已。socket 本身并不是协议,它是应用层与 TCP/IP 协议族通信的中间软件抽象层,是一组调用接口(TCP/IP网络的API函数)
“TCP/IP 只是一个协议栈,就像操作系统的运行机制一样,必须要具体实现,同时还要提供对外的操作接口。 这个就像操作系统会提供标准的编程接口,比如win32编程接口一样。TCP/IP 也要提供可供程序员做网络开发所用的接口,这就是 Socket 编程接口。”
Server:
import socket
import threading
def tcplink(sock, addr):
print('Accept new connection from %s:%s...' % addr)
sock.send(b'Welcome!')
while True:
data = sock.recv(1024)
time.sleep(1)
if not data or data.decode('utf-8') == 'exit':
break
sock.send(('Hello, %s!' % data.decode('utf-8')).encode('utf-8'))
sock.close()
print('Connection from %s:%s closed.' % addr)
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 监听端口:
s.bind(('127.0.0.1', 9999))
s.listen(5)
print('Waiting for connection...')
while True:
# 接受一个新连接:
sock, addr = s.accept()
# 创建新线程来处理TCP连接:
t = threading.Thread(target=tcplink, args=(sock, addr))
t.start()
Client:
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 建立连接:
s.connect(('127.0.0.1', 9999))
# 接收欢迎消息:
print(s.recv(1024).decode('utf-8'))
for data in [b'Michael', b'Tracy', b'Sarah']:
# 发送数据:
s.send(data)
print(s.recv(1024).decode('utf-8'))
s.send(b'exit')
s.close()
例子来源于廖雪峰的官网
108. 简述 进程、线程、协程的区别以及应用场景
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源
协程是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈
多进程:密集 CPU 任务,需要充分使用多核 CPU 资源(服务器,大量的并行计算)的时候,用多进程。 缺陷:多个进程之间通信成本高,切换开销大
多线程:密集 I/O 任务(网络 I/O,磁盘 I/O,数据库 I/O)使用多线程合适。缺陷:同一个时间切片只能运行一个线程,不能做到高并行,但是可以做到高并发
协程:又称微线程,在单线程上执行多个任务,用函数切换,开销极小。不通过操作系统调度,没有进程、线程的切换开销。缺陷:单线程执行,处理密集 CPU 和本地磁盘 IO 的时候,性能较低。处理网络 I/O 性能还是比较高
多线程请求返回是无序的,哪个线程有数据返回就处理哪个线程,而协程返回的数据是有序的
109. 如何使用线程池和进程池
池的功能是限制启动的进程数或线程数。当并发的任务数远远超过了计算机的承受能力时,即无法一次性开启过多的进程数或线程数时,就应该用池的概念将开启的进程数或线程数限制在计算机可承受的范围内
多进程
from multiprocessing import Pool
import os
import time
import random
def long_time_task(name):
print('Run task %s (%s)...' % (name, os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task %s runs %0.2f seconds.' % (name, (end - start)))
def test_pool():
print('Parent process %s.' % os.getpid())
p = Pool(4)
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print('Waiting for all subprocesses done...')
p.close()
p.join()
print('All subprocesses done.')
if __name__ == '__main__':
test_pool()
output
Parent process 32432. Waiting for all subprocesses done... Run task 0 (15588)... Run task 1 (32372)... Run task 2 (12440)... Run task 3 (18956)... Task 2 runs 0.72 seconds. Run task 4 (12440)... Task 3 runs 0.82 seconds. Task 1 runs 1.21 seconds. Task 0 runs 3.00 seconds. Task 4 runs 2.95 seconds. All subprocesses done.
apply_async(func[, args[, kwds]]) :使用非阻塞方式调用 func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args 为传递给 func 的参数列表,kwds 为传递给 func 的关键字参数列表;close():关闭 Pool,使其不再接受新的任务;terminate():不管任务是否完成,立即终止;join():主进程阻塞,等待子进程的退出, 必须在 close 或 terminate 之后使用
也可以使用 concurrent.futures 模块提供的功能来实现
def test_future_process():
print('Parent process %s.' % os.getpid())
p = ProcessPoolExecutor(4)
for i in range(5):
p.submit(long_time_task, i)
p.shutdown(wait=True)
print('Finish')
if __name__ == '__main__':
# test_pool()
test_future_process()
output
Parent process 29368. Run task 0 (32148)... Run task 1 (31552)... Run task 2 (24012)... Run task 3 (29408)... Task 2 runs 0.52 seconds. Run task 4 (24012)... Task 3 runs 0.86 seconds. Task 1 runs 1.81 seconds. Task 0 runs 1.83 seconds. Task 4 runs 1.69 seconds. Finish
多线程
def sayhello(a):
print("hello: " + a)
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task %s runs %0.2f seconds.' % (a, (end - start)))
def test_future_thread():
seed = ["a", "b", "c", "d"]
start = time.time()
with ThreadPoolExecutor(3) as executor:
for i in seed:
executor.submit(sayhello, i)
end = time.time()
print("Thread Run Time: " + str(end - start))
output
hello: a hello: b hello: c Task a runs 0.40 seconds. hello: d Task b runs 0.56 seconds. Task d runs 1.70 seconds. Task c runs 2.92 seconds. Thread Run Time: 2.9195945262908936
可以看出,由于是创建了限制为3的线程池,所以只有三个任务在同时执行
110. 进程之间如何进行通信
def write(q):
print("write(%s), 父进程为(%s)" % (os.getpid(), os.getppid()))
for i in "Python":
print("Put %s to Queue" % i)
q.put(i)
def read(q):
print("read(%s), 父进程为(%s)" % (os.getpid(), os.getppid()))
for i in range(q.qsize()):
print("read 从 Queue 获取到消息: %s" % q.get(True))
def test_commun():
print("(%s) start" % os.getpid())
q = Manager().Queue()
pw = Process(target=write, args=(q, ))
pr = Process(target=read, args=(q, ))
pw.start()
pr.start()
pw.join()
pr.terminate()
output
(23544) start write(29856), 父进程为(23544) Put P to Queue Put y to Queue Put t to Queue Put h to Queue Put o to Queue Put n to Queue read(25016), 父进程为(23544) read 从 Queue 获取到消息:P read 从 Queue 获取到消息:y read 从 Queue 获取到消息:t read 从 Queue 获取到消息:h read 从 Queue 获取到消息:o read 从 Queue 获取到消息:n
Python 的 multiprocessing 模块包装了底层的机制,提供了 Queue、Pipes 等多种方式来交换数据