基于python一种简单的pixiv排行榜图片爬虫
爬虫特点:
-不需要p站用户名密码登录
-经过修改可用于每日排行等多种排行榜爬取
本文示例为爬取插画每月排行榜
首先容易观察到p站每月排行榜网址为
https://www.pixiv.net/ranking.php?mode=monthly&content=illust&date=20190323
结尾字符串为查询相应年月日
用F12可以查看到每张图的网址和缩略图指向原图网址
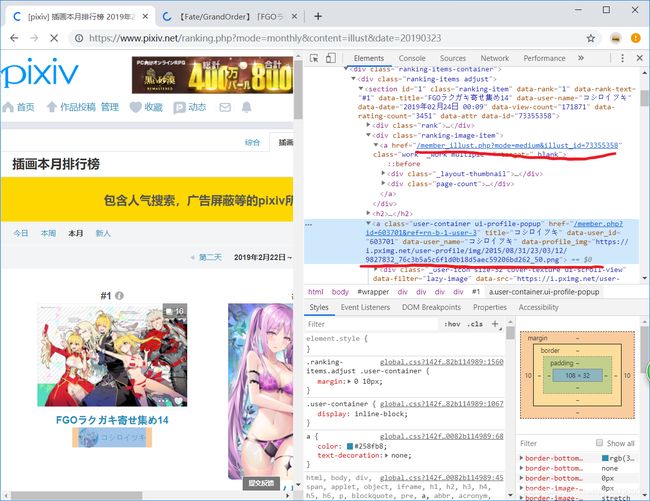
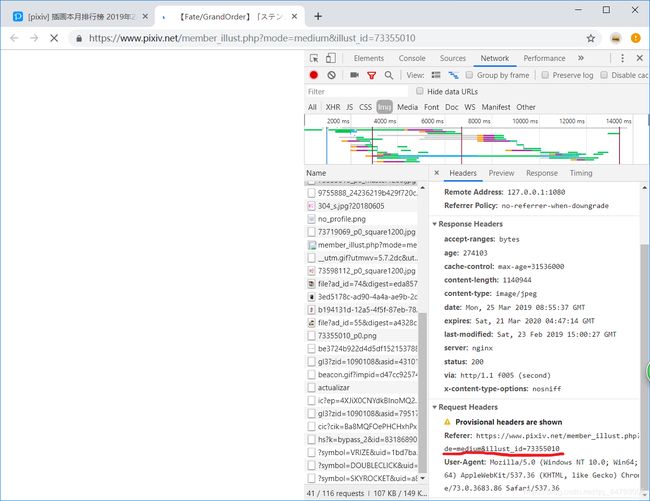
为了获取原图,我们进入某张图片,通过F12容易找到原图地址,在Network需要注意到GET图片需要headers[‘Referer’] (否则会403错误)。
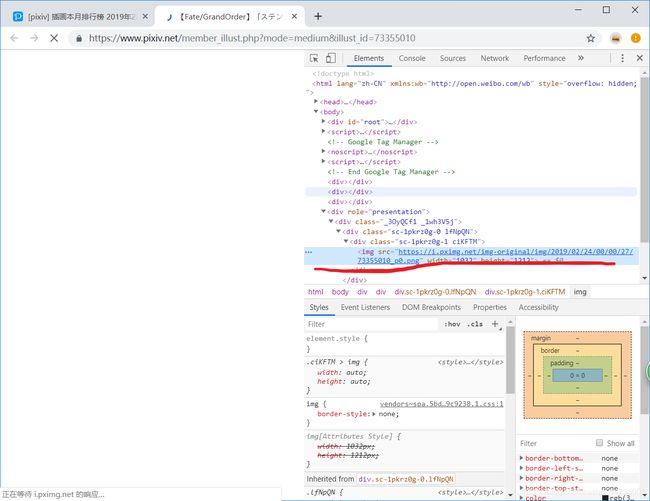
这里有一个误区:如果没有登录的话 进入原图是这样的

网页源文件中不存在原图网址 于是其他博主往往采用登录后再获取网址的方法 以下是我的方法
经过一番试错后 我们能观察到
缩略图网址:https://i.pximg.net/c/240x480/img-master/img/2019/02/24/00/00/27/73355010_p0_master1200.jpg
原图网址:https://i.pximg.net/img-original/img/2019/02/24/00/00/27/73355010_p0.png
绝大部分相似 由此想到 我们可以运用正则匹配加字符串替换方法将排行榜得到的缩略图网址修改成原图网址 从而避免了登录、在原图网页获取原图网址的步骤
以下为代码
函数geturl(year,month)为获取某年某月排行榜缩略图网址并返回列表:
def geturl(year,month):
baseurl='https://www.pixiv.net/ranking.php?mode=monthly&content=illust&date={}{}01'.format(str(year),str(month).zfill(2))
html=urllib.request.urlopen(baseurl)
soup=BeautifulSoup(html,'lxml')
a=soup.find_all(class_='_layout-thumbnail')
urllist=[]
for i in a:
urllist.append(i.find('img').get('data-src'))
return urllist
函数getori将缩略图网址用字符串替换方法得到原网址:
def getori(llist):
orilist=[]
for i in llist:
tem = re.search("/c/\d{0,3}x\d{0,3}/img-master/",i).group()
i=i.replace(tem,'/img-original/')
i=i.replace('_master1200','')
i=i.replace('.jpg','.png')
orilist.append(i)
return orilist
函数downloading为下载指定图片,注意到原图既有png又有jpg文件,首先访问png网址,根据返回值长度判断是否得到图片,否则换jpg再次访问。别忘了headers[‘Referer’]!此处图片命名采用#排名数-p站图片id方式,如果要以图片名命名,应该可以采用在geturl时获取图片名,返回dict方式进行。
def downloadimg(url,rank,fnum):
hheaders={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'}
pid=re.search('\d{7,9}',url).group()
hheaders['Referer']='https://www.pixiv.net/member_illust.php?mode=medium&illust_id='+pid
hou=['png','jpg']
img=requests.get(url,headers=hheaders).content
token=0
if(len(img)<100):
token=1
url=url.replace('.png','.jpg')
img=requests.get(url,headers=hheaders).content
with open('{}\\#{}-{}.{}'.format(str(fnum),rank,pid,hou[token]),'wb') as f:
f.write(img)
主函数采用多线程图片下载
if __name__=='__main__':
os.chdir("D:\\file\\PY\\爬虫\\pixiv")
p=Pool(8)
for k in range(1,13):
urls=getori(geturl(2018,k))
number=1
for i in urls:
p.apply_async(downloadimg,args=(i,number,k))
number=number+1
p.close()
p.join()
函数使用库:
from multiprocessing import Pool
from bs4 import BeautifulSoup
import urllib.request
import os,re,requests
源代码下载: https://pan.baidu.com/s/1HDXArfZDGH0eo10rOWGObQ 提取码: gk6q
QQ:825775001