窥探黑盒-卷积神经网络的可视化
这是笔者第N+1次听到专家说,深度学习模型是“黑盒”。这个说法不能说他对,也不能说他错。但是这句话从专家那里说出来,感觉就有点不严谨了,想必专家应该长时间不在科研一线了... 对于某些类型的深度学习模型来说,确实通过可视化中间节点很难获取到直接判别的有效信息,但对于卷积神经网络来说,可不是这样子的。 因为卷积神经网络学习到的表示 learned representation 非常适合可视化。这很大程度上得益于卷积神经网络是基于视觉概念的表示。
1. 目前卷积深度表示的可视化/解释方法
- 中间激活态/特征图可视化。也就是对卷积神经网络的中间输出特征图进行可视化,这有助于理解卷积神经网络连续的层如何对输入的数据进行展开变化,也有注意了解卷及神经网络每个过滤器的含义。 更深入的, 笔者曾经讲中间激活态结合‘注意力机制’进行联合学习,确实显著提高了算法的精度。
- 空间滤波器组可视化。卷积神经网络学习的实质可以简单理解为学习一系列空间滤波器组的参数。可视化滤波器组有助于理解视觉模式/视觉概念。 更深入的,笔者曾经思考过,如何才能引导dropout趋向各项同性空间滤波器。因为从视觉感知对信息的捕捉效果来看,更倾向于捕捉高频成分,诸如边缘特征、纹理等。
- 原始图像中各组分贡献热力图。我们都知道,卷积神经网络是基于感受野以及感受野再次组合进行特征提取的。但是我们需要了解图像中各个部分对于目标识别的贡献如何?这里将会介绍一种hotmap的形式,判断图像中各个成分对识别结果的贡献度概率。
2. 中间特征图可视化
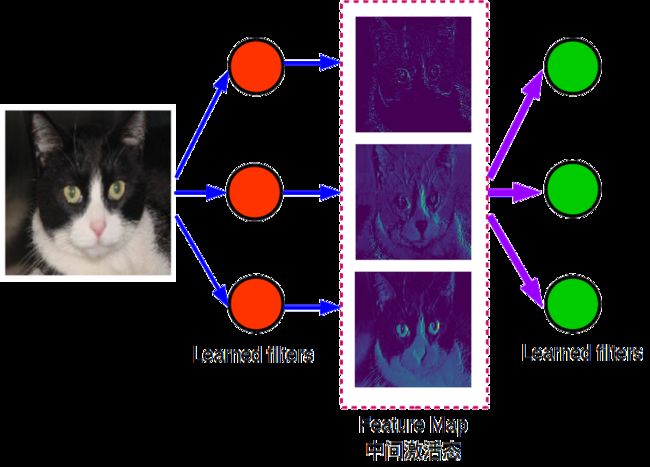
可视化卷积神经网络的中间层输出,可以让我们看到输入图像经过learned filters之后的输出结果(更习惯称之为中间激活态/特征图)。卷积神经网络每层都包含了N个learned filters,所以每个中间层的输出将会是N张特征图(每一个滤波器filters都会对输入图像进行滤波,N也成为中间特征图的深度/通道)。一般来说,每个通道特征图都对应着独立的特征,这些特征恰恰就是对应的learned filter 赋予的。通过对所有通道特征图进行可视化,我们可以很容易判断每个滤波器的性能。
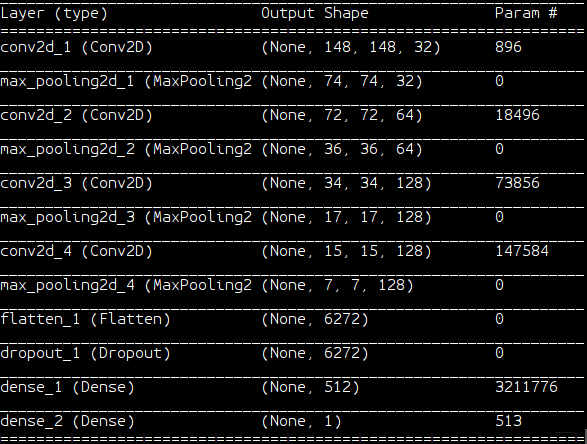
我们使用 ‘特征层次分析、视觉特征语义探索’ 中训练好的卷积神经网络进行测试[用于特征图/卷积核/响应图可视化的网络 ],其神经网络结构为:
核心代码:
model = load_model('cats_and_dogs_small_2.h5') # 加载已经训练好的模型
img_path = 'cats_dags_small/test/cats/cat.1535.jpg' # 提取实验图像
img = image.load_img(img_path, target_size = (150,150))
img_tensor = image.img_to_array(img)
img_tensor = np.expand_dims(img_tensor, axis = 0) # 图像维度拓展,输入网络 (1,150,150,3)
img_tensor /= 255.
#-----------------------------------
layer_outputs = [ layer.output for layer in model.layers[0:8] ] # 获取模型节点输出
# 构造节点测试模型,对实验数据进行测试
activation_model = models.Model(inputs = model.input, outputs = layer_outputs) # 8个激活模型
activations = activation_model.predict(img_tensor) # 8个激活层输出,即8个层输出的特征图
layer_names = [] # 读取各个输出节点对应的层名称
for layer in model.layers[0:8]:
layer_names.append(layer.name)
images_per_row = 16 # 每行现实的特征图数量
for layer_name, layer_activation in zip(layer_names, activations): # 每层名称+特征图输出
n_features = layer_activation.shape[-1]
size = layer_activation.shape[1] # feature_map = [1, size, size, n_features]
n_cols = n_features // images_per_row
display_grid = np.zeros((size * n_cols, images_per_row * size))
for col in range (n_cols):
for row in range(images_per_row):
channel_image = layer_activation[:,:,col*images_per_row + row]
channel_image = np.clip(channel_image, 0, 255).astype('uint8')
display_grid[col * size : (col + 1) * size,
row * size : (row + 1) * size] = channel_image
# Display the grid
scale = 1. / size
plt.figure(figsize=(scale * display_grid.shape[1],
scale * display_grid.shape[0]))
plt.title(layer_name)
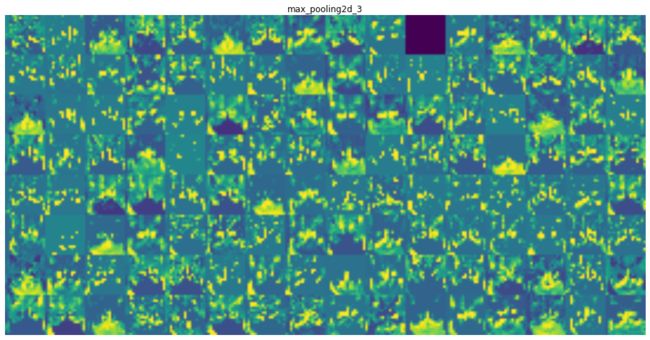
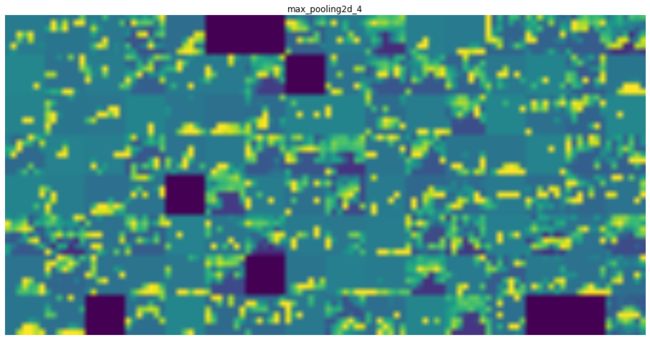
plt.imshow(display_grid, aspect='auto', cmap='viridis') 以第1-4卷积层为例,网络中间输出的激活态为:


总结:
- 通过检查卷积滤波器的中间输出,我们发现:靠近底层的CNN提取的是基础视觉特征,这些视觉特征是很容易被理解的,也是非常通用的。 靠近顶层的CNN提取的是综合高级语义信息,这些信息是对底层视觉特征的综合,更加有利于对识别、分类任务等决策任务形成贡献。
- 随着层数的加深,中间特征层变得越来越抽象,难以用视觉信息直观进行解释,但是明显可以感受到,确实在表征高层次的视觉概念。例如,响应图大的地方往往对应猫的耳朵、胡须、眼睛等生理结构。
- 顶层的输出告诉我们一个道理,其实CNN学习到的特征图并不都是有用的。随着CNN越深,有效的特征逐渐变得稀疏化。很多特征图[其对应的就是卷积滤波器]是没有效果的。这个时候就需要我们引入‘attention’的机制去弱化贡献度小的特征图,强化贡献度大的特征图。这也是我硕士期间一直努力的方向。
- 在keras中,Model模型和Sequential模型一样,可以将特定输入映射为特定输出。不同的是,Model模型允许有多个输出。
- 结合人体视觉系统更好解释。我们凭借记忆记住的猫狗等图像,仅仅是一个概念图/抽象图。很难画出像摄像机图像一样真实,这是因为我们大脑早就学会了将输入信息完全抽象化,进而转为更高层次的视觉概念,虑除掉不相关的视觉细节。
3. 空间滤波器组可视化
直接可视化3x3 5x5的滤波器模板并没有收益。学习过信号系统处理的同学应该知道,冲激信号最频繁用于测试系统,其响应直接表征了系统的特征。这里我也是通过可视化滤波器的响应,进而推断卷积核的作用。整个过程可以通过在输入空间中进行梯度上升实现:从空白输入图像开始,将梯度下降应用于卷积神经网络输入图像的值,目的就是为了让某个滤波器的响应最大化。这样得到的响应图像直接反映了滤波器视觉表征特征(变边缘提取描述子? 纹理提取描述子? or 色度信息提取描述子?)
- 补充知识【信号系统中,如何获取未知系统的性能】:
白噪声(自相关)->冲激信号->与系统进行卷积->得到响应(该响应可以表征系统的所有特性)
核心代码:
def generate_pattern(layer_name, filter_index, size = 150):
# 为滤波器的可视化定义损失张量
layer_output = model.get_layer(layer_name).output
loss = K.mean( layer_output[:,:,:,filter_index] )
# 获取损失相对于输入的梯度
grads = K.gradients(loss, model.input)[0]
grads /= (K.sqrt( K.mean( K.square(grads) ) ) + 1e-5 )
iterate = K.function([model.input], [loss, grads])
# 通过梯度下降让损失最大化
input_img_data = np.random.random((1,size,size,3))*20 + 128
step = 1
for i in range(100):
loss_value, grads_value = iterate([input_img_data])
input_img_data += grads_value * step
img = input_img_data[0]
return deprocess_image(img)这里对VGG16中 1-4 CNN层滤波器进行响应可视化,实验结果如下:

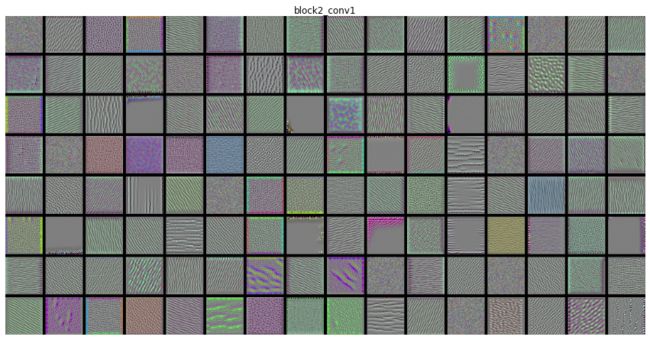
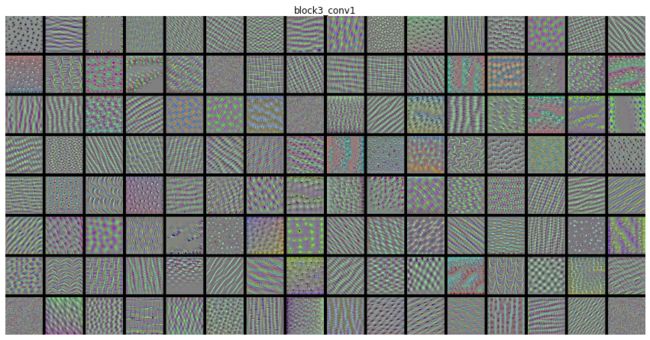

总结:
- 深度学习过程类似于傅里叶变换讲信号分解为一组余弦函数的过程。随着层数的加深,滤波器变得越来越复杂,提取的特征也越来越精细。
- 底层提取的确实是通用特征,更多的是边缘、纹理特征。
4. 组分贡献度可视化
由卷积神经网络构成的深度框架,如VGG16、VGG19、Xception、ResNet101等,在目标识别任务中取得了非常好的结果。特别的,我们知道卷积操作是存在感受野的,那么很自然的,我们想知道每个感受野对最终识别/分类/定位等决策结果的贡献程度。本节主要可视化这个过程,该过程也称之为类激活图[1](CAM,Class Activation Map)。
该方法[1]综述为: 给定一张图像,对于一个卷积层的输出特征图,用类别相对于通道的梯度对这个特征图中的每个通告进行加权。其实质就是,用‘每个通道对类别的重要程度’对‘输入图像对不同通道的激活强度’的空间图进行加权,从而得到‘输入图像对类别的激活强度’的空间图。
举例来说,对于输入到猫狗分类卷积神经网络的一张图像,CAM可视化可以生成类别‘猫’的热力图,该图热力图颜色深浅表示感受野对决策为'猫'的贡献;当然CAM也会生成类别为‘狗’的热力图。毕竟卷积神经网络通过概率进行决策。
 vvvv
vvvv
结论:
通过实验我们可以发现,之所以算法可以定位到目标,或者是识别出这是一只贵族犬,原因在于狗头部贡献了大量的信息。
5. 总结+参考文献
总结:
- 通过前面一系列可视化,我们可以发现深度学习之所以强,很大程度上是因为空间滤波器组的数量大、特征层次符合视觉系统。这能够解释卷积神经网络的效果往往比递归神经网络在解决视觉问题效果更好。
- 我们也能发现,其实相当大一部分卷积滤波器的效果是没有那么明显的。如何能够弱化低响应滤波器,强化高响应滤波器应该引起足够重视。目前,从我的工作中发现,Attention机制是一个非常好的解决方案。
- 定制化的网络裁剪也是一个很有潜力的方向,这实际上是对Attention机制的补充,此外,定制化裁剪可以提高网络的响应速度,这对于实际应用是非常有意义的。
[1] Selvaraju R R, Cogswell M, Das A, et al. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization[J]. international conference on computer vision, 2017: 618-626.
[2] python-with-deep-learning,2018.