R︱sparkR的安装与使用、函数尝试笔记、一些案例
本节内容转载于博客: wa2003
spark是一个我迟早要攻克的内容呀~
—————————————————————————————————————
一、SparkR 1.4.0 的安装及使用
1、./sparkR打开R shell之后,使用不了SparkR的函数
装在了 /usr/local/spark-1.4.0/ 下
[root@master sparkR]#./bin/sparkR
能进入R,和没装SparkR的一样,无报错
> library(SparkR)
Error in library.dynam(lib, package, package.lib) :
shared object ?.parkR.so?.not found
Error: package or namespace load failed for ?.parkR?
解决办法:重新编译sparkR之后,运行以下命令:
[root@master sparkR]# ./install-dev.sh
然后运行
[root@elcndc2bdwd01t spark-1.4.0]# ./bin/sparkR
R version 3.2.0 (2015-04-16) -- "Full of Ingredients"
Copyright (C) 2015 The R Foundation for Statistical Computing
Platform: x86_64-unknown-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
Natural language support but running in an English locale
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
下面是启动SparkR那些,包括加载SparkR的库,自动生成 Sparkcontext和sqlContext。
Launching java with spark-submit command /usr/local/spark-1.4.0/bin/spark-submit "sparkr-shell" /tmp/RtmpAN5LID/backend_port7d49547c6f51
log4j:WARN No appenders could be found for logger (io.netty.util.internal.logging.InternalLoggerFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/25 13:33:13 INFO SparkContext: Running Spark version 1.4.0
.........................................
15/06/25 13:33:16 INFO BlockManagerMaster: Registered BlockManager
Welcome to SparkR!
Spark context is available as sc, SQL context is available as sqlContext
2、修改log4j的日志控制台打印级别
在Spark的conf目录下,把log4j.properties.template修改为log4j.properties
[appadmin@elcndc2bdwd01t bin]$ cd /usr/local/spark-1.4.0/
$ sudo mv log4j.properties.template log4j.properties
把log4j.rootCategory=INFO, console改为log4j.rootCategory=ERROR, console即可抑制Spark把INFO级别的日志打到控制台上。
如果要显示全面的信息,则把INFO改为DEBUG。
3、在Rstudio 下使用sparkR的设置
[root@elcndc2bdwd01t /]# ln -s /usr/local/spark-1.4.0/R/lib/SparkR /home/enn_james/R/x86_64-unknown-linux-gnu-library/3.2
(2)在R的环境设置文件(.Rprofile)中增加一行
Sys.setenv(SPARK_HOME=”/usr/local/spark-1.4.0”)
两个配置文件,.Renviron和.Rprofile。这两个文件名看起来有点奇怪,怪在哪儿?它们只有扩展名,没有主文件名
在操作系统中有一个默认的规则,凡是以点开头的文件都是隐藏文件,而且通常都是配置文件。前面那句list.files()代码你要是运行过,可能就会发现很多以点开头的文件和文件夹。
R启动的时候会在系统的若干位置寻找配置文件,如果文件存在就会使用这些配置。
其中.Renviron文件用来设置一些R要用的环境变量,而.Rprofile文件则是一个R代码文件,在R启动时,如果这个文件存在,它会被首先执行。因此,如果我们有一些任务要在R启动时运行,或有一些个人选项要配置,都可以写在这个文件里。
3、4040端口看Spark的任务执行情况
http://10.37.148.39:4040/jobs/
—————————————————————————————————————
二、SparkR跑通的函数(持续更新中...)
spark1.4.0的sparkR的思路:用spark从大数据集中抽取小数据(sparkR的DataFrame),然后到R里分析(DataFrame)。
这两个DataFrame是不同的,前者是分布式的,集群上的DF,R里的那些包都不能用;后者是单机版的DF,包里的函数都能用。
sparkR的开发计划,个人觉得是将目前包里的函数,迁移到sparkR的DataFrame里,这样就打开一片天地。
> a<- sql(hiveContext, "SELECT count(*) FROM anjuke_scores where restaurant>=10");
> a<- sql(hiveContext, "SELECT * FROM anjuke_scores limit 5")
> a
DataFrame[city:string, housingname:string, ori_traffic_score:int, ori_traffic_score_normal:double, metro_station:double, metro_station_normal:double,...
> first(a) #显示Formal Data Frame的第一行
> head(a) ; #列出a的前6行
> columns(a) # 列出全部的列
[1] "city" "housingname" "ori_traffic_score" "ori_traffic_score_normal"
[5] "metro_station" "metro_station_normal" "bus_station" "bus_station_normal" ...
> showDF(a)
> b<-filter(a, a$ori_comfort>8); # 行筛选, ori_comfort_normal:double
> print(a); #打印列名及类型
DataFrame[city:string, housingname:string, ori_traffic_score:int, ......
> printSchema(a); # 打印列名的树形框架概要 root |-- city: string (nullable = true) |-- housingname: string (nullable = true) |-- ori_traffic_score: integer (nullable = true) |-- ori_traffic_score_normal: double (nullable = true) |-- metro_station: double (nullable = true) > take(a,10) ; # 提取Formal class DataFrame的前面num行,成为R中普通的 data frame , take(x, num)
city housingname ori_traffic_score ori_traffic_score_normal metro_station metro_station_normal
1 \t\x9a \xddrw\xb8 NA 0 NA 0
2 \t\x9a \xe4\xf04\u03a2\021~ NA 0 NA 0
3 \t\x9a \xf6\xe3w\xb8 NA 0 NA 0
4 \t\x9a \x8e=\xb0w\xb8 NA 0 NA 0
5 \t\x9a \t\x9a\xe4\xf04\xce\xe4\xf0~ NA 0 NA 0
6 \t\x9a q4\xfdE NA 0 NA 0
7 \t\x9a \xe4\xf04\xce NA 0 NA 0
8 \t\x9a )\xfdVT NA 0 NA 0
9 \t\x9a q\177V NA 0 NA 0
10 \t\x9a \xe4\xf04\xceW\xb8 NA 0 NA 0
> b<-take(a,10)
> dim(b)
[1] 10 41
> aa <- withColumn(a, "ori_comfort_aa", a$ori_comfort * 5) #用现有的列生成新的列, 新增一列,ori_comfort_aa,结果还是Formal data frame结构
> printSchema(aa)
root
|-- city: string (nullable = true)
.........
|-- comfort_normal: double (nullable = true)
|-- ori_comfort_aa: double (nullable = true)> printSchema(aa)
root
|-- city: string (nullable = true)
。。。。。。。。。。。。。。。。。。
|-- comfort_normal: double (nullable = true)
|-- newCol1: double (nullable = true)
|-- newCol2: double (nullable = true)
a1<-arrange(a,asc(a$level_tow)); # 按列排序, asc升序,desc降序
a1<-orderBy(a,asc(a$level_tow)); # 按列排序
count(a) ; # 统计 Formal Data Frame有多少行数据
> dtypes(a); #以list的形式列出Formal Data Frame的全部列名及类型
[[1]]
[1] "city" "string"
[[2]]
[1] "housingname" "string" > a<-withColumnRenamed(a,"comfort_normal","AA"); # 更改列名
> printSchema(a)
root
|-- city: string (nullable = true)
|-- housingname: string (nullable = true)
..........
|-- AA: double (nullable = true)创建sparkR的数据框的函数createDataFrame
> df<-createDataFrame(sqlContext,a.df); # a.df是R中的数据框, df是sparkR的数据框,注意:使用sparkR的数据库,需要sqlContext'data.frame': 5 obs. of 41 variables:
> str(df)
Formal class 'DataFrame' [package "SparkR"] with 2 slots
..@ env:
..@ sdf:Class 'jobj'
> destDF <- select(SFO_DF, "dest", "cancelled"); #选择列
> showDF(destDF); #显示sparkR的DF
+----+---------+
|dest|cancelled|
+----+---------+
| SFO| 0|
................
> registerTempTable(SFO_DF, "flightsTable"); #要对sparkDF使用SQL语句,首先需要将DF注册成一个table
> wa <- sql(sqlContext, "SELECT dest, cancelled FROM flightsTable"); #在sqlContext下使用SQL语句
> showDF(wa); #查询的结果还是sparkDF
+----+---------+
|dest|cancelled|
+----+---------+
| SFO| 0|
................
> local_df <- collect(wa); #将sparkDF转换成R中的DF
> str(local_df)
'data.frame': 2818 obs. of 2 variables:
$ dest : chr "SFO" "SFO" "SFO" "SFO" ...
$ cancelled: int 0 0 0 0 0 0 0 0 0 0 ...
> wa<-flights_df[1:1000,]; #wa是R中的DF
> flightsDF<-createDataFrame(sqlContext,wa) ; #flightsDF是sparkR的DF
> library(magrittr); #管道函数的包对sparkRDF适用
> groupBy(flightsDF, flightsDF$date) %>%
+ summarize(avg(flightsDF$dep_delay), avg(flightsDF$arr_delay)) -> dailyDelayDF; #注意,语法和dplyr中的有所不同,结果还是sparkRDF
> str(dailyDelayDF)
Formal class 'DataFrame' [package "SparkR"] with 2 slots
..@ env:
..@ sdf:Class 'jobj'
> showDF(dailyDelayDF)
+----------+--------------------+--------------------+
| date| AVG(dep_delay)| AVG(arr_delay)|
+----------+--------------------+--------------------+
|2011-01-01| 5.2| 5.8|
|2011-01-02| 1.8333333333333333| -2.0|
................
在39机器上跑的
collect将sparkDF转化成DF
Collects all the elements of a Spark DataFrame and coerces them into an R data.frame.
collect(x, stringsAsFactors = FALSE),x:A SparkSQL DataFrame
> dist_df<- sql(hiveContext, "SELECT * FROM anjuke_scores where restaurant<=1");
> local_df <- dist_df %>%
groupBy(dist_df$city) %>%
summarize(count = n(dist_df$housingname)) %>%
collect
> local_df
city count
1 \t\x9a 5
2 8\xde 7
3 \xf0\xde 2
..........
..........
take也可将sparkDF转化成DF
Take the first NUM rows of a DataFrame and return a the results as a data.frame
take(x, num)
> local_df <- dist_df %>%
groupBy(dist_df$city) %>%
summarize(count = n(dist_df$housingname))
> a<-take(local_df,100)
[Stage 16:=========================================> (154 + 1) / 199] > View(a)
> a
city count
1 \t\x9a 5
2 8\xde 7
3 \xf0\xde 2
..........
..........
不通的函数:
> describe(a)
Error in x[present, drop = FALSE] :
object of type 'S4' is not subsettable
> jfkDF <- filter(flightsDF, flightsDF$dest == "DFW")
Error in filter(flightsDF, flightsDF$dest == "DFW") :
no method for coercing this S4 class to a vector——————————————————————————————————————————————————————
三、用Spark分析Amazon的8000万商品评价
这篇文章里面提到了spark通过R的调取轻松胜任了复杂的数据查询功能,同时用ggplot2进行可视化操作。该案例是一个很好的sparkR的使用案例,国内翻译过来不够全面,想深入研究的请看原文:http://minimaxir.com/2017/01/amazon-spark/
使用面对R语言的新的升级包,我可以使用一个spark_connect()命令轻松启动本地Spark集群,并使用单个spark_read_csv()命令很快将整个CSV加载到集群中。
1、用sparkR进行大规模数据整理
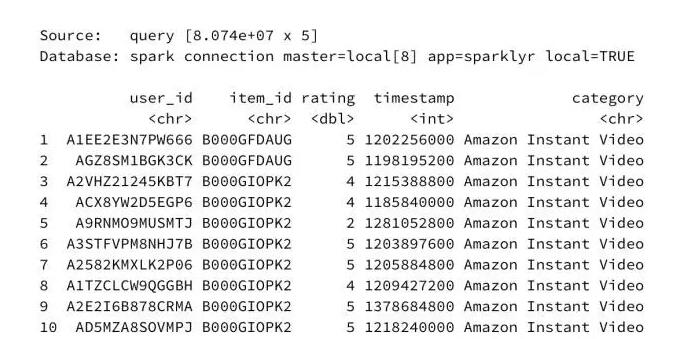
在数据集中总共有8074万条记录,即8.074e + 07条。如果使用传统工具(如dplyr或甚至Python pandas)高级查询,这样的数据集将需要相当长的时间来执行。
使用sparklyr,操作实际很大的数据就像对只有少数记录的数据集执行分析一样简单(并且比上面提到的eDX类中教授的Python方法简单一个数量级)。
2、用Rnotebook+ggplot2.0进行可视化
作者写了一些ggplot2实现可视化的函数,在他的github:https://github.com/minimaxir/amazon-spark?spm=5176.100239.blogcont69165.13.Eo3vpV
列举几个:
library(readr)
library(dplyr)
library(ggplot2)
library(extrafont)
library(scales)
library(grid)
library(RColorBrewer)
library(digest)
library(readr)
library(stringr)
fontFamily <- "Source Sans Pro"
fontTitle <- "Source Sans Pro Semibold"
color_palette = c("#16a085","#27ae60","#2980b9","#8e44ad","#f39c12","#c0392b","#1abc9c", "#2ecc71", "#3498db", "#9b59b6", "#f1c40f","#e74c3c")
neutral_colors = function(number) {
return (brewer.pal(11, "RdYlBu")[-c(5:7)][(number %% 8) + 1])
}
set1_colors = function(number) {
return (brewer.pal(9, "Set1")[c(-6,-8)][(number %% 7) + 1])
}
theme_custom <- function() {theme_bw(base_size = 8) +
theme(panel.background = element_rect(fill="#eaeaea"),
plot.background = element_rect(fill="white"),
panel.grid.minor = element_blank(),
panel.grid.major = element_line(color="#dddddd"),
axis.ticks.x = element_blank(),
axis.ticks.y = element_blank(),
axis.title.x = element_text(family=fontTitle, size=8, vjust=-.3),
axis.title.y = element_text(family=fontTitle, size=8, vjust=1.5),
panel.border = element_rect(color="#cccccc"),
text = element_text(color = "#1a1a1a", family=fontFamily),
plot.margin = unit(c(0.25,0.1,0.1,0.35), "cm"),
plot.title = element_text(family=fontTitle, size=9, vjust=1))
}
create_watermark <- function(source = '', filename = '', dark=F) {
bg_white = "#FFFFFF"
bg_text = '#969696'
if (dark) {
bg_white = "#000000"
bg_text = '#666666'
}