hadoop+Zookeeper集群安装配置高可用-HadoopHA
1、请看:https://blog.csdn.net/sunxiaoju/article/details/85222290,此处只是配置系统的:硬件配置以及操作系统、节点需要安装的工具、安装JDK环境、创建hadoop用户、建立ssh无密码登录本机前五部分,第6部分的hadoop安装在此博文中需要重新配置,所以不需要查看,在此处博文中需要添加一个master1的namenode节点要结合前五部分一起配置。
2、下载zookeeper:https://zookeeper.apache.org/releases.html
如下图所示,第一个是下载当前活跃的版本,第二个是下载旧版本:

2、然后将下载好的zookeeper通过scp命令上传到master节点,如:
scp zookeeper-3.4.10.tar.gz [email protected]:/home/sunftp/ftpdir/
如下图所示:

3、此时在master节点的/home/sunftp/ftpdir/目录中有一个zookeeper-3.4.10.tar.gz文件,如下图所示:
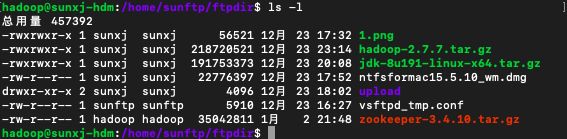
4、使用如下命令解压:
tar -xzvf zookeeper-3.4.10.tar.gz如下图所示:

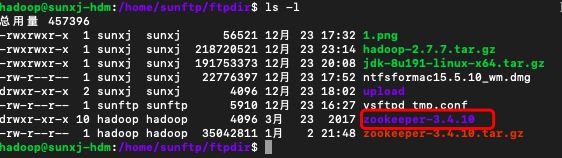
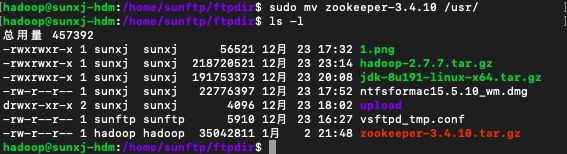
5、将zookeeper-3.4.10文件夹移动到/usr/目录下,使用如下命令移动:
sudo mv zookeeper-3.4.10 /usr/如下图所示:
6、然后进入到/usr/zookeeper-3.4.10/conf/目录,修改配置,使用如下命令从模板配置文件中复制一个zookeeper的配置文件,如:
sudo cp zoo_sample.cfg zoo.cfg如下图所示:

7、在zookeeper-3.4.10目录中新建一个data目录,使用如下命令:
sudo mkdir data如下图所示:
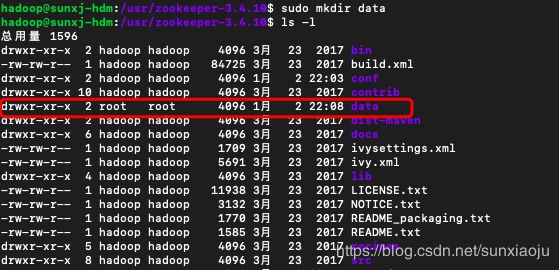
8、使用如下命令打开zoo.cfg进行编辑
sudo vim conf/zoo.cfg 如下图所示

9、然后修改添加入下信息:
dataDir=/usr/zookeeper-3.4.10/data/
server.1=192.168.0.109:2888:3888
server.2=192.168.0.110:2888:3888
server.3=192.168.0.111:2888:3888其中dataDir修改为刚刚新建data的目录,server.1是master节点IP,1是编号,其余的是slave节点IP,如下图所示:

10、在dataDir指定的目录中新建一个myid文件,文件内容:master节点上为:1,slave1节点上为:2,slave2节点上为:3,使用如下命令新建文件,然后输入1:
sudo vim data/myid如下图所示:

11、保存退出,然后通过如下命令分别上传到slave1和slave2:
scp -r zookeeper-3.4.10 [email protected]:/home/sunftp/ftpdir/
scp -r zookeeper-3.4.10 [email protected]:/home/sunftp/ftpdir/如下图所示:


13、然后将slave节点上的zookeeper目录从/home/sunftp/ftpdir/移动到/usr/,如下图所示:

14、然后分别使用如下命令:在slave1节点上编辑/usr/zookeeper-3.4.10/data/myid文件,然后将1改为2,在slave2节点上编辑/usr/zookeeper-3.4.10/data/myid文件,然后将1改为3,
sudo vim /usr/zookeeper-3.4.10/data/myid如下图所示:


15、将/usr/zookeeper-3.4.10/bin/添加到环境变量中,修改/etc/profile,添加入下:
export ZOOKEEPER_HOME=/usr/zookeeper-3.4.10
export PATH="$ZOOKEEPER_HOME/bin:$PATH"如下图所示:

16、保存退出,然后执行source /etc/profile,使之生效,然后在slave1和slave2节点上用同样的方法配置。
17、使用如下命令启动zookeeper:
zkServer.sh start此时提示没有权限,如下图所示:

18、使用如下命令修改zookeeper目录权限,并且在slave1和slave2分别执行:
sudo chmod -R 777 /usr/zookeeper-3.4.1019、在master、slave1、salve2启动zookeeper,如下图所示:



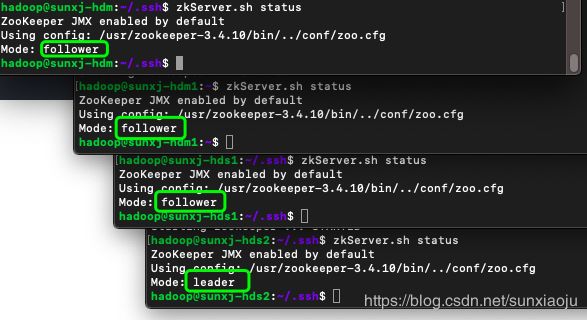
20、然后使用如下命令分别查看master、slave1、slave2的状态:
zkServer.sh status如下图所示:



21、三台机器必须只有一个leader,其他都是follower。
22、此时用jps查看进程会多一个QuorumPeerMain则表示zookeeper配置启动成功,如下图所示:
master:

slave1:
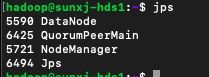
slave2:

23、如果想要看出zookeeper效果,需要多配置一台hadoop的namenode节点,那么现在在新建一台hadoop的namenode节点,配置方法与其他3台相同,新建的一台我们叫做master1,域名配置为:sunxj-hdm1.myhd.com,IP:192.168.0.108,首先在master1节点上使用如下命令创建一个hadoop用户:
sudo adduser hadoop如下图所示:

24、使用如命令把hadoop用户加入到hadoop用户组,前面一个hadoop是组名,后面一个hadoop是用户名:
sudo usermod -a -G hadoop hadoop如下图所示:
![]()
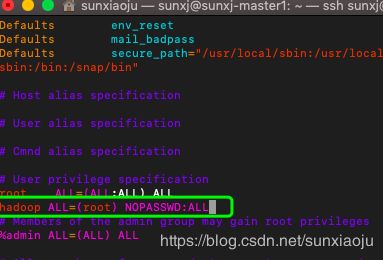
25、把hadoop用户赋予root权限,让他可以使用sudo命令,使用如下命令编辑:
sudo vim /etc/sudoers在root ALL=(ALL:ALL) ALL下一行加入:
hadoop ALL=(root) NOPASSWD:ALL如下图所示:
26、修改master1的主机名为:sunxj-hdm1,使用如下命令修改:
sudo vim /etc/hostname如下图所示:
![]()
然后将:sunxj-master1修改为sunxj-hdm1
修改前:![]() ,修改后:
,修改后:![]()
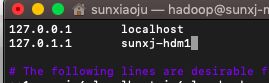
27、修改/etc/hosts文件中对应的主机名,如下图所示:
28、然后使用reboot重启,之后即可看到主机名已改,如下图所示:

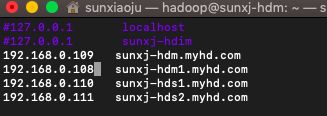
29、在master、master1、slave1、slave2节点上在/etc/hosts文件中加入:
192.168.0.109 sunxj-hdm.myhd.com
192.168.0.108 sunxj-hdm1.myhd.com
192.168.0.110 sunxj-hds1.myhd.com
192.168.0.111 sunxj-hds2.myhd.com然后将原来的localhost,sunxj-hdm1注释掉,如下图所示:
30、然后使用如下命令,在四个节点中执行使配置生效
sudo /etc/init.d/networking restart如下图所示:

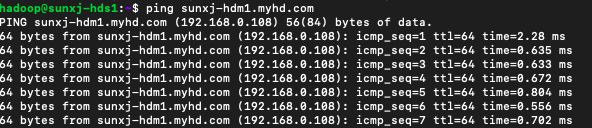
31、如果直接通过ping sunxj-hdm1.myhd.com是通的即可配置完成,如下图所示:
33、建立ssh无密码登录,具体方法请看:https://blog.csdn.net/sunxiaoju/article/details/85222290中的第五部分。
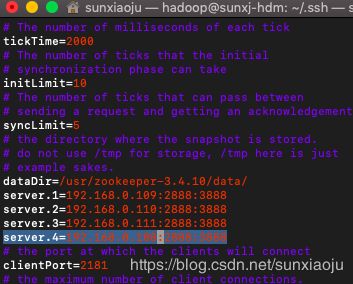
34、在配置master,slave1,slave2上的zookeeper,在zoo.cfg配置文件加一个服务列表server.4=192.168.0.108:2888:3888,如下图所示:
35、然后将zookeeper-3.4.10传到master1节点上的/usr/目录。
36、修改master1节点上的/usr/zookeeper-3.4.10/data/myid为4,如下图所示:

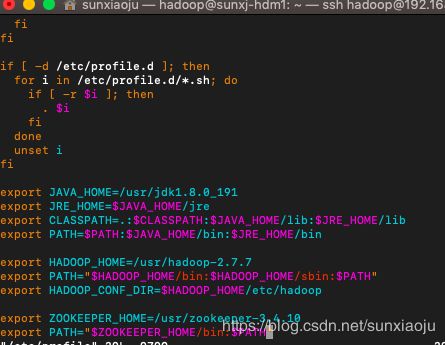
38、配置master1节点的环境变量,编辑/etc/profile文件,如下图所示:
发现没有配置jdk环境,以及hadoop环境,我们将hadoop上相应的配置全部拷贝过来,然后在传输文件,修改后的内容如下图所示:
37、然后使用如下命令分别启动四个节点的zookeeper:
zkServer.sh start如下图所示:




38、最后在使用如下命令查看状态:
zkServer.sh status如下图所示:
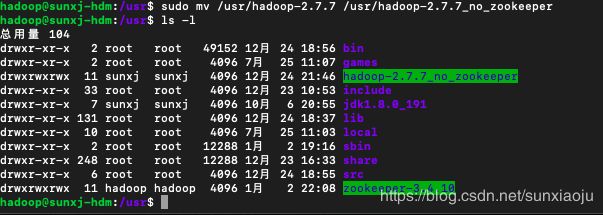
39、为了保持干净,我们把master、slave1、slave2上的hadoop目录更改一个名字,然后重新解压一个干净的hadoop,比如将原来的hadoop-2.7.7更改为hadoop-2.7.7_no_zookeeper,使用如下命令进行更改:
sudo mv /usr/hadoop-2.7.7 /usr/hadoop-2.7.7_no_zookeeper如下图所示:
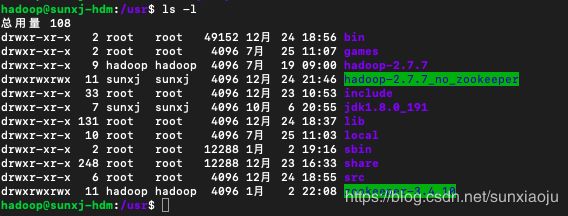
40、拷贝一个新的hadoop到usr,注意:文件夹名应与原来的文件夹名相同,这样对于环境变量就不用重新配置了,如下图所示:
41、修改hadoop-2.7.7的权限,使用如下命令修改权限:
sudo chmod 777 /usr/hadoop-2.7.7如下图所示:

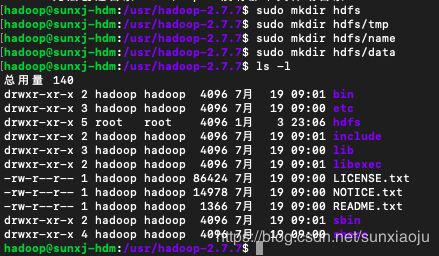
42、在hadoop-2.7.7目录中一个hdfs目录和三个子目录,如
- hadoop-2.7.3/hdfs
- hadoop-2.7.3/hdfs/tmp
- hadoop-2.7.3/hdfs/name
- hadoop-2.7.3/hdfs/data
- hadoop-2.7.3/hdfs/data/journaldata
如下图所示:
![]()
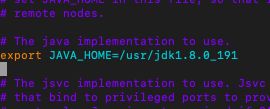
43、此时的修改都集中到master修改,首先修改hadoop-env.sh文件,将export JAVA_HOME=${JAVA_HOME}更改为:/usr/jdk1.8.0_191,如下图所示:
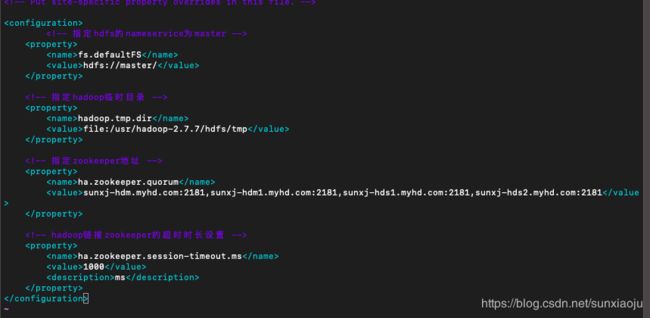
44、修改core-site.xml,如下:
fs.defaultFS
hdfs://master/
hadoop.tmp.dir
file:/usr/hadoop-2.7.7/hdfs/tmp
ha.zookeeper.quorum
sunxj-hdm.myhd.com:2181,sunxj-hdm1.myhd.com:2181,sunxj-hds1.myhd.com:2181,sunxj-hds2.myhd.com:2181
ha.zookeeper.session-timeout.ms
1000
ms
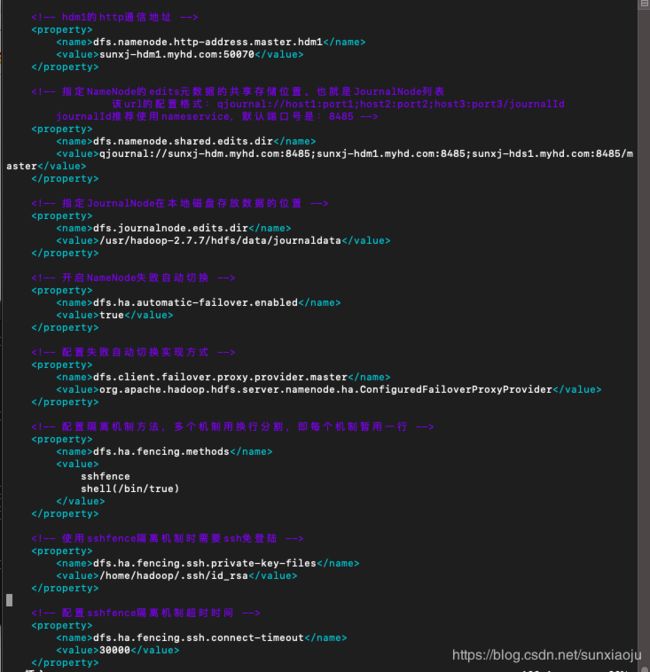
45、修改hdfs-site.xml,修改如下:
dfs.replication
2
dfs.namenode.name.dir
file:/usr/hadoop-2.7.7/hdfs/name
dfs.datanode.data.dir
file:/usr/hadoop-2.7.7/hdfs/data
dfs.webhdfs.enabled
true
dfs.nameservices
master
dfs.ha.namenodes.master
hdm,hdm1
dfs.namenode.rpc-address.master.hdm
sunxj-hdm.myhd.com:9000
dfs.namenode.http-address.master.hdm
sunxj-hdm.myhd.com:50070
dfs.namenode.rpc-address.master.hdm1
sunxj-hdm1.myhd.com:9000
dfs.namenode.http-address.master.hdm1
sunxj-hdm1.myhd.com:50070
dfs.namenode.shared.edits.dir
qjournal://sunxj-hdm.myhd.com:8485;sunxj-hdm1.myhd.com:8485;sunxj-hds1.myhd.com:8485/master
dfs.journalnode.edits.dir
/usr/hadoop-2.7.7/hdfs/data/journaldata
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.master
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/home/hadoop/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
ha.failover-controller.cli-check.rpc-timeout.ms
60000
如下图所示:


46、修改mapred-site.xml ,先通过如下命令拷贝一个模板文件:
sudo cp mapred-site.xml.template mapred-site.xml如下图所示:
![]()
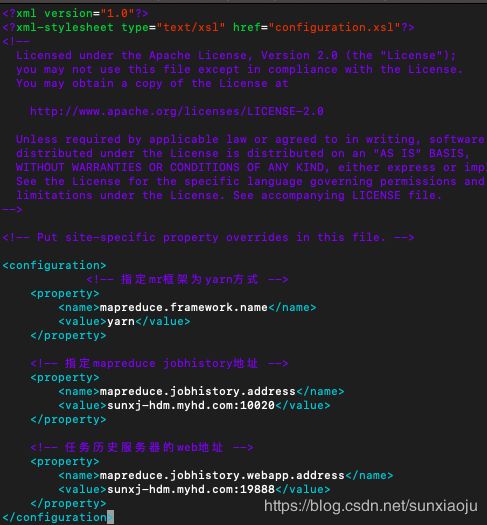
47、然后编辑修改mapred-site.xml,修改如下:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
sunxj-hdm.myhd.com:10020
mapreduce.jobhistory.webapp.address
sunxj-hdm.myhd.com:19888
如下图所示:
47、修改yarn-site.xml ,修改如下:
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yrc
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
sunxj-hds1.myhd.com
yarn.resourcemanager.hostname.rm2
sunxj-hds2.myhd.com
yarn.resourcemanager.zk-address
sunxj-hdm.myhd.com:2181,sunxj-hdm1.myhd.com:2181,sunxj-hds1.myhd.com:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
86400
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
如下图所示:


48、在mapred-env.sh加入JAVA_HOME,如下图所示:
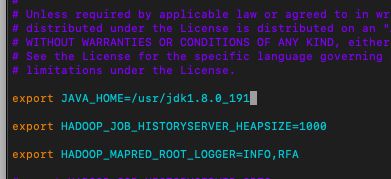
49、在yarn-env.sh加入JAVA_HOME,如下代码:
export JAVA_HOME=/usr/jdk1.8.0_191如下图所示:
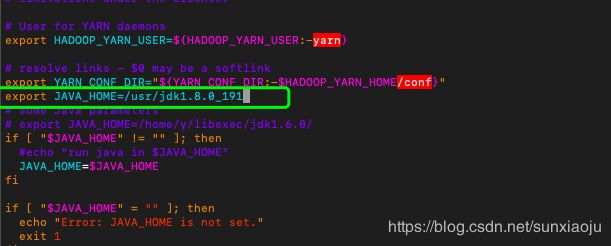
50、修改slaves,修改如下:
sunxj-hdm.myhd.com
sunxj-hdm1.myhd.com
sunxj-hds1.myhd.com
sunxj-hds2.myhd.com如下图所示:

注意:这些配置文件全部在/usr/hadoop.2.7.7/etc/hadoop目录下:

51、将hadoop-2.7.7目录分发到master1、slave1、slave2的usr目录中,使用如下命令:
scp -r hadoop-2.7.7 [email protected]:/home/sunftp/ftpdir/
scp -r hadoop-2.7.7 [email protected]:/home/sunftp/ftpdir/
scp -r hadoop-2.7.7 [email protected]:/home/sunftp/ftpdir/52、然后在每个节点执行:
sudo mv /home/sunftp/ftpdir/hadoop-2.7.7 /usr/53、启动zookeeper,由于之前已启动过,这里不在启动。
54、在master,master1,slave1节点上启动journalnode进程,使用如下命令启动:
hadoop-daemon.sh start journalnode此时在master1,slave1节点上已出现journalnode进程,如下图所示:


但是在master上启动即没报错,也没有journalnode进程,如下图所示:

55、然后通过:
cat hadoop-2.7.7/logs/hadoop-hadoop-journalnode-sunxj-hdm.log 查看日志出现以下错误:
STARTUP_MSG: java = 1.8.0_191
************************************************************/
2019-01-04 00:16:58,071 INFO org.apache.hadoop.hdfs.qjournal.server.JournalNode: registered UNIX signal handlers for [TERM, HUP, INT]
2019-01-04 00:16:58,477 ERROR org.apache.hadoop.hdfs.qjournal.server.JournalNode: Failed to start journalnode.
org.apache.hadoop.util.DiskChecker$DiskErrorException: Directory is not writable: /usr/hadoop-2.7.7/hdfs/data/journaldata
at org.apache.hadoop.util.DiskChecker.checkAccessByFileMethods(DiskChecker.java:193)
at org.apache.hadoop.util.DiskChecker.checkDirAccess(DiskChecker.java:174)
at org.apache.hadoop.util.DiskChecker.checkDir(DiskChecker.java:108)
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.validateAndCreateJournalDir(JournalNode.java:118)
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.start(JournalNode.java:138)
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.run(JournalNode.java:128)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:84)
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.main(JournalNode.java:299)
2019-01-04 00:16:58,482 INFO org.apache.hadoop.util.ExitUtil: Exiting with status -1
2019-01-04 00:16:58,486 INFO org.apache.hadoop.hdfs.qjournal.server.JournalNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down JournalNode at sunxj-hdm.myhd.com/192.168.0.109
************************************************************/出现此问题是由于没有写权限,然后具体查看hadoop-2.7.7/hdfs/data/journaldata的权限,发现属于root用户,而非hadoop哦用户,如下图所示:

55、这是由于在创建时默认为了root用户,那么我们查看以下hdfs,tmp,data,name的权限,如下图所示:
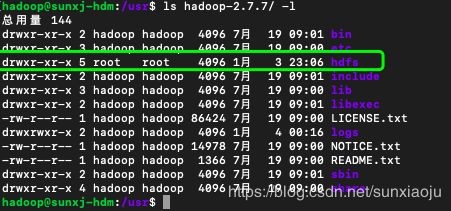

56、通过如下命令更改:
sudo chown hadoop:hadoop hadoop-2.7.7/hdfs
sudo chown hadoop:hadoop hadoop-2.7.7/hdfs/tmp
sudo chown hadoop:hadoop hadoop-2.7.7/hdfs/name
sudo chown hadoop:hadoop hadoop-2.7.7/hdfs/data
sudo chown hadoop:hadoop hadoop-2.7.7/hdfs/data/journaldata如下图所示:

57、再次使用hadoop-daemon.sh start journalnode启动即可,如下图所示:

58、使用如下命令在master格式化namenode:
hadoop namenode -format如下图所示:


59、把在master节点上生成的元数据 给复制到 另一个namenode(master1)节点上,数据位置在/usr/hadoop-2.7.7/hdfs/name/,如下图所示:
![]()
60、将current目录放置到到master1节点相同的位置,通过如下命令先传输到master1节点上:
scp -r /usr/hadoop-2.7.7/hdfs/name/current [email protected]:/home/sunftp/ftpdir/如下图所示:

61、通过如下命令在master1上将current移动到/usr/hadoop-2.7.7/hdfs/name/中:
sudo mv /home/sunftp/ftpdir/current /usr/hadoop-2.7.7/hdfs/name/
如下图所示:

62、在master节点上使用如下命令格式化zkfc:
hdfs zkfc -formatZK如下图所示:
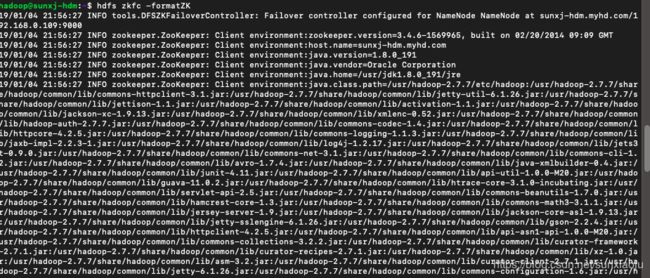

63、上图中显示格式化成功,然后在master节点上使用start-all.sh启动HDFS,如下图所示:
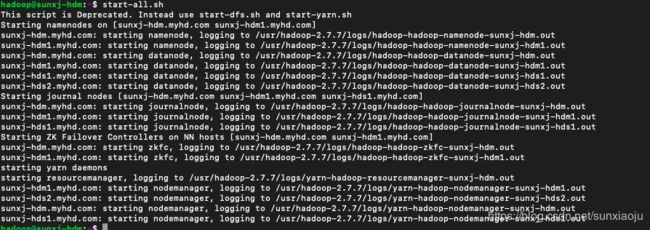
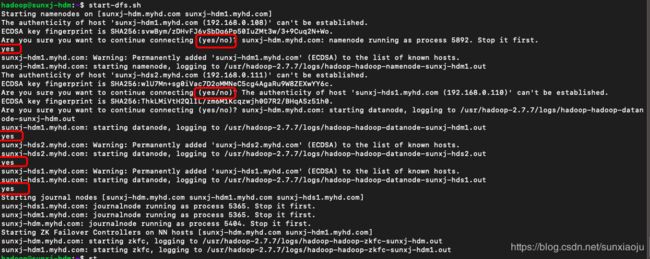
注意:如果启动的时候卡住,说明需要输入yes,比如:
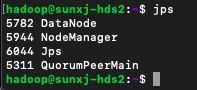
64、启动之后,检查各节点的进程,如下图所示:
master节点:

master1节点:

slave1节点:

slave2节点:
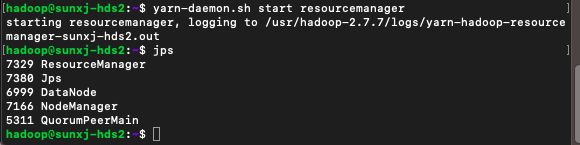
65、此时发现slave1和slave2上没有ResourceManager进程(通过start-all.sh启动),那么需要单独的使用如下命令进行启动:
yarn-daemon.sh start resourcemanager如下图所示:

注意:在nodename节点上resourcemanager和NodeManager进程同时只能运行一个,而datanode节点可以同时运行。
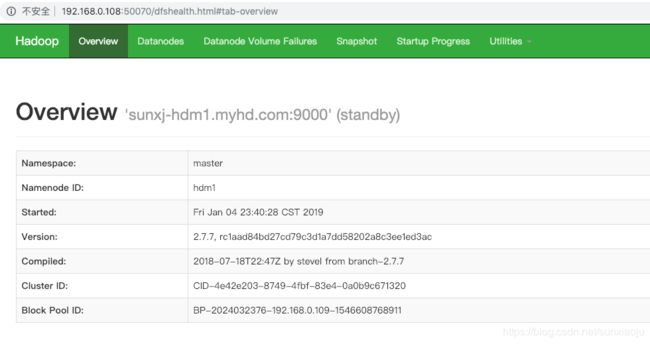
66、此时可通过web界面来查看master和master1两个节点的状态,必然有一个是active,一个是standby,如下图所示:
(1)master:http://192.168.0.109:50070,如下图所示:

(2)master1:http://192.168.0.108:50070,如下图所示:

67、在slave2节点上查看yarn的web界面,地址为:http://192.168.0.111:8088,如下图所示:

68、web界面来查看master和master1两个节点的状态,可以确定在master1节点上的namenode是活动的,那么我们在master1节点上找到namenode进程的PID,然后强制结束,如下图所示:

69、再次通过查看web界面上的状态,此时原来master1节点无法打开web,而master的状态从standby变为了active,说明已经自动切换了,如下图所示:

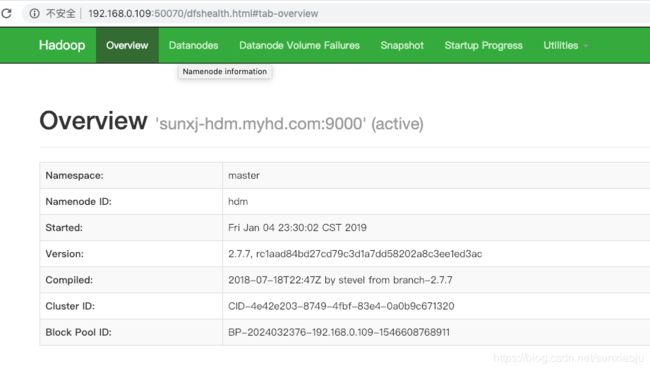
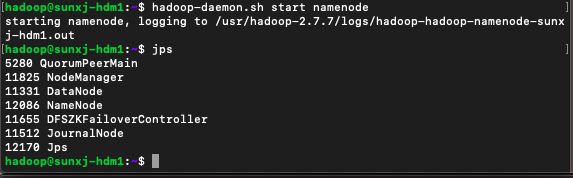
70、现在将master1上的namenode通过如下命令单独启动起来:
hadoop-daemon.sh start namenode如下图所示:
此时的web界面如下图所示:
71、在上传文件的时候干掉 active namenode,在上传文件之前首先要确定上传的位置在哪里,我们可以通过如下命令来查看hdfs系统下的目录信息:
hadoop fs -ls /如下图所示:
![]()
![]()
78、此时master和master1节点上的hdfs系统中没有一个文件或文件夹,那么我们可以通过如下命令来创建一个文件夹,比如在master1上创建一个user_data文件夹,那么使用如下命令:
hadoop fs -mkdir /user_data那么此时会在master也会自动创建一个user_data的,如下图所示:
在master1上创建:

在master节点上查看:

79、现在在master1节点上准备一个文件,文件大小为218720521kb,比如:

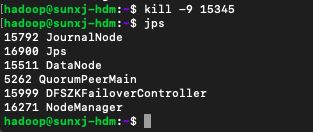
80、在master1上传的过程中,在master上kill掉namenode进程,如下图所示:

81、在master1上通过如下命令上传:
hadoop fs -put /home/sunftp/ftpdir/hadoop-2.7.7.tar.gz /user_data如下图所示:
![]()
82、现在开始上传,在上传过程中kill掉master上的namenode,如下图所示:

83、查看文件是否上传成功,可通过如下命令查看:
hadoop fs -ls /user_data/如下图所示:

我们可以看到上传的大小与原始文件大小相同,所以可以确定上传成功,所以在上传过程中如果出现active的namenode节点异常退出,会有一个备用namenode节点启动来保证文件不会丢失。
84、现在将master上的namenode启动,然后查看数据,如下图所示:
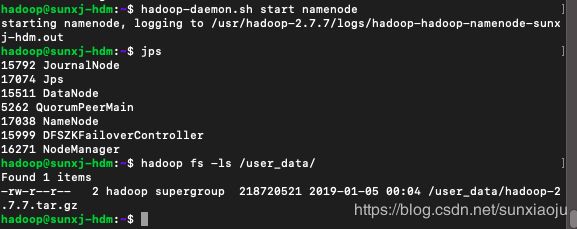
此时在两个slave1和slave2的节点上同样可以查看到文件,如下图所示;

85、然后也可以通过web界面查看,注意只能在active的节点上查看,如下图所示:
active节点(master1)

standby(master)节点:

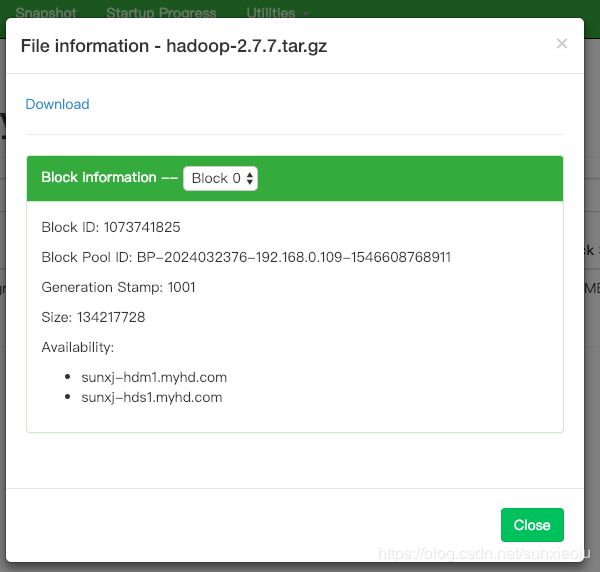
86、然后在查看user_data目录,如下图所示:

87、然后也可以点击下载,如下图所示:
主要参考:https://www.cnblogs.com/qingyunzong/p/8634335.html