企业服务架构演进-单库多服务的尴尬
本篇是企业服务架构演进系列的第四篇,这里着重讲述了基于自研微服务RPC,WEB框架下的分布式微服务系统实践。我选了HR相关服务作为背景来阐述单库多服务下服务之间如何协作,如何分工并划分领域模型和服务,最后引出两个要点:1.微服务拆分的方法论和规范2.服务化如何解决此类单库多服务的拆分和落地。
本文中的单库指的是hr数据库,这里简称hrdb.hrdb中的数据表大体可以分为三类1.单点登录用户账号表(account,loginlog),登录日志表.2.用户账号关联的内部员工信息表,部门表,薪资表,工作经历表等(staff,department,salary,expirence)3.三方用户信息表(third_user)。这里我统计了下基于以上三类数据表大概有16个工程,所以这里的单库多服务也算是名副其实了。另外我将这些工程按出现远近划分了4个阶段,每个阶段都有不同的服务产生。
远古时期:
sso-rpc
单点登录的rpc服务端,提供登录校验,查找用户,新增账号等rpc接口,与sso-web工程一起建设,作为基础服务在我们部门维护。直连HRDB。
sso-web
单点登录的http服务,提供统一的登录界面,有通过密码,扫码登录的方式,提供重置密码,忘记密码等功能。依赖sso-rpc服务。
#####hr-old-rpc
部门成立后做的第一版hr系统,相当于hr服务的服务端,提供员工信息的增删改查接口。工程直连HRDB。
hr-old-thirduser-web
部门成立后做的第一版hr系统可视化界面,我维护的时候已无源代码,之后也不曾改动,提供账号的增删改查禁用启用等,内部员工信息,三方账号的增删改查。这里不确定是否依赖hr-old-rpc。是否直连hrdb有待验证。
在这个时期中主要产生了两个领域的服务,也就是用户单点登录服务和hr服务,我个人觉得这两个其实不应该混在一起,因此算两个领域吧。另外一方面,由于hr服务经过两个版本迭代后并不被认可,领导层决定外采hr系统,因此web端管理系统(这里是另外一个工程,由于无法考证暂时忽略)直接下线,hr-old-rpc逐渐废弃。hr-old-thirduser-web工程也仅仅被当时的核心运维开发人员熟知。这个决定直接导致了后期整个hr服务在建设过程中异常漫长。
早期:
sso-findpwd-web
单点登录服务专门提供了一个可被外网访问的重新找回密码的服务,有一个域名,就2-3个界面操作,主要的目的是为了三方用户可以重置自己的账号密码。这个三方账号的用户名-密码字段存储在user表中,正式员工的账号密码也存在这张表中,通过字段区分。
hr-xinrenxinshi-web
这个服务其实是在远古时期留下的一个产物,由于领导要外采hr系统作为企业人力管理系统,因此作为企业信息化部门必须要对接这个系统才能满足整个公司的人力管理要求。因此我们跟外采公司做了一些数据同步的工作,整体流程就是hr先将待入职员工录入这个外采系统,然后通过定时同步拉取数据的机制去将入职员工拉取到hrdb数据库中保存,最后生成账号。由于服务和网络等问题,数据实时性一直无法保证,后期又加入数据对比机制,但是仍然会让其他下游部门感到数据时延太高,从而对我们部门感到部门,因此维护员工数据对当时的小伙伴来说苦不堪言。
sso-old-ldap-scheduler
早期公司的文档库,代码库,研发效能平台依赖我们部门的员工账号数据,而上面的这些文档库,代码库,研发效能平台都是直接搭建的系统,因此只支持ldap协议去进行员工信息的验证。因此我们配合运维和研发效能的同事一起搭建了第一版的ldap服务用来同步全公司的员工账号信息包括部门信息。sso-old-ldap-scheduler通过调用hr-ext-rpc接口的方式去捞取数据然后发送HTTP请求到ldap服务器去覆盖老数据。
hr-data-sync-web
这个服务比较隐蔽,是存在于沙箱环境的一个特殊服务。功能是将线上的新创建账号,新部门员工等数据同步到测试和沙箱环境,这个工程实际上并没有上线,在沙箱环境可以连接线上和线下进行数据同步。工程服务建设较早,因此也是直连线上和线下数据库通过DAO框架进行数据同步。
hr-ext-rpc
hr-ext-rpc服务也是远古时期做第一版hr系统的时候遗留下的产物,这个服务主要是提供对外的服务接口,提供各种(员工信息,账号信息,部门信息,钉钉userid信息等)查询接口,据我统计95%的接口都是查询类的。这个服务相当于整个hr服务的对外rpc服务,为各个部门的内部业务系统,自己部门的业务系统提供员工信息获取的服务。因此这有别于hr-old-rpc服务,hr-old-rpc服务相当于hrweb端管理系统对应的后端服务。接口不对外开放。这个服务和sso服务都是我长期维护的,其并发量也是部门全部系统中相对较高的。这个服务也是直连hrdb的。
hr-ext-web
有了对外的rpc服务,但是并不能满足系统对接的需求,有些系统是PHP的,有些系统是python开发的。这些系统不能直接使用hr-old-rpc的接口。因此我们通过hr-ext-web这个工程提供一个HTTP接口服务,然后内部引用hr-old-rpc的接口获取数据返回给调用方。
hr服务的早期其实没有多少波澜,大部分都是远古时期留下的产物。这段时间里主要是跟外采hr系统的相互纠缠太多,本身上面的服务虽然一直在迭代,但是对于整个hr服务来说并不完整,相当于一个本来就没有成长太多的人变成了跛脚的人,然后走了很远很远。
中期:
hr-new-thirduser-web
新的三方账号系统是为了解决当时业务线申请创建三方账号没有正式的申请流程,权限管控,审批等问题。这个服务实际上是一个单体服务,提供账号开通,禁用启用等功能,底层通过多数据源链接了新建设的三方账号数据库thirduserdb和hrdb。
hr-new-thirduser-scheduler
这个服务是一个定时任务工程,逻辑比较简单。就是每天扫描一下三方账号的数据库,如果账号快到期了没有重新申请则发邮件提醒,另外如果到期还没有申请则直接关闭相关账号。这里也是直连hrdb的。
corehr-rpc
这个服务和下面的其他corehr服务构成了新一代自研的hr服务系统。由于外采的hr系统本质上是一个saas系统或者saas平台,对hr提出的新需求总是要排期,要加钱。另外促成领导层要自研hr系统的一个主要动力是这个外采的系统出现了一次重大长时间的服务不可用问题。这里再说明一下,这个服务其实就是hr-old-rpc要提供的服务,只是功能和模块更多更复杂,整体支持了hr办公的闭环需求。这个服务逐渐成为整个hr系统服务的底层服务了。
corehr-web
corehr-web实际上替代了上文未统计到的hrweb端管理系统,整体上同corehr-rpc一起迭代了多个大版本,开发了1年多。是个前后端分离的工程,只提供http接口,依赖corehr-rpc提供的接口支持员工信息,部门信息,报表数据等功能模块。
corehr-sceduler
corehr-scheduler工程随着hr项目的启动将更多具有定时触发执行的功能模块放入了这个工程里面,基于公司的定时任务调度平台进行配置。由于项目人员较少,开发时间相对紧张,因此这个库里很多代码是从corehr-rpc工程里拷贝过来的,同时抽象一层service,job层写业务代码。因此这个工程实际上也是直连hrdb库的。
sso-new1-ldap-scheduler
跟sso相关的这两个ldap-scheduler工程实际上是为了业务需要而新建的工程,这个sso-new1-ldap-scheduler工程是为了提供更安全更通用的账号存储服务,区别于最老的那一套,用户名密码等传送更加安全,同时这个项目上线之后之前的老ldap-scheduler工程也就慢慢下线了,同时这个工程和对应的ldap服务器支持了更全面的confluenece文档库的用户验证,git账号验证等三方系统的账号验证。
sso-new2-ldap-scheduler
这个项目实际上是为了大数据部门要将系统迁移到阿里云上将阿里云操作账号与公司内部员工账号进行打通而建立的。在选取对接协议的时候考虑到ldap服务更加通用,双方都支持,建设起来更快更便捷,这个项目是企业主力开发对接,需求方是大数据部门,重点协助则为运维部门,是典型的跨部门合作项目。因此这套ldap服务也是区别于前面两套ldap,三者都是独立的。
在这个时间段内,我们的hr服务从无到有的又重新建立起来了,并且形成了业务闭环,同时与其他系统如招聘系统等进行了打通。corehr项目实际上在项目负责人的带领下重新定义了其基础服务的地位,保障了数据从上游到下游的统一管控,出现问题更容易排查。另一方面也通过这个项目潜移默化的协调了其他服务,保障了hr相关的工程服务共同形成了一个hr微服务生态。
后期:
corehr-api
corerhr-api是hr服务的移动端版本,提供钉钉微应用对应的后端接口,功能有合同管理,个人信息管理等。
corehr-salary-api
corehr-salary-api是为了与财务部门对应的金蝶第三方系统进行对接,我们提供数据源通过一定的机制将数据同步到这个第三方系统,为了数据安全我们并没有将这部分功能放到其他工程服务中。
在整个hr服务建设的后期基本上已经完成了员工的调转入离等功能,实现了各个业务系统之间的数据打通,虽然整个建设过程从corehr项目立项到最后完全形成功能闭环,形成服务生态花了一年多时间,但是为了企业发展更高效也是值得的。下面通过一张图来描述这些服务组成的hr微服务生态。
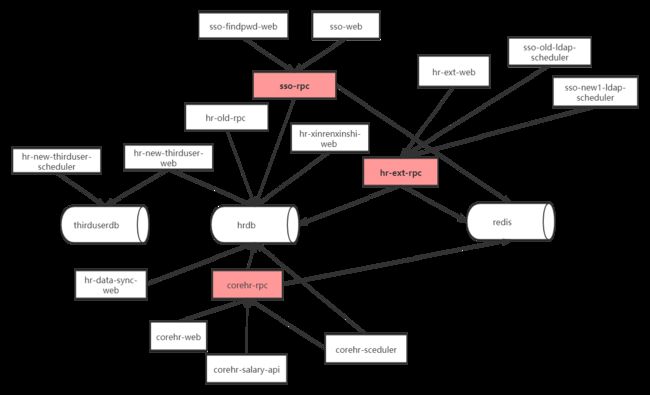
上图中仅包含相关模块服务到db之间的关系,各个服务之间更多的依赖关系并没有画出来,以免看着混乱。从整体的建设过程和hrdb创建的时间来看实际上是从2016年上半年开始到2019年下半年结束的。那么从上面的工程概览和大概的建设过程说明可以看出这些hr工程服务大概会有什么问题呢,以及如果重来我们如何更好更快的建设这些相关业务呢?下面我从三个方面来说明一些问题。
- 新服务与老服务之间的协调问题
在整个hr服务的建设过程中我们当时只对要做的功能去考虑是新建工程还是在已有工程上进行迭代,并没有从全局去考虑新建工程是否合理,直连数据库是否合理等问题,而是直接通过数据安全维度,业务相关维度,组织部门决策维度进行工程服务划分。那么在进行业务开发的时候实际上新服务并没有完全替代老服务,这样就导致了新老并行,老的服务依然在别的项目中被引用,新老服务提供相似的功能,比如hr-ext-rpc出现之后实际上hr-old-rpc服务应该早就下线才对。在进行基础服务定位的时候没有出现corerhr服务之前hr-ext-rpc是基础服务,但是这个服务是不完整的,虽然访问量很大,虽然查询很多但是并没有跟corerhr这样的新服务完全协调好,以及corehr服务和sso等老服务之间的协调问题都存在。 - 数据耦合下的服务层
我们从数据库表来看整个hr服务生态,实际上从数据库来看它本质上还是单库的,仅仅是工程是微服务形式的,所以是以单库多服务出现的形态,因此叫微服务显得有点尴尬。从服务层来看,基于hrdb数据库已经衍生出了很多服务,从工程上来看是微服务的,但是几乎每个工程负责的数据表都包括这三类数据表,出现了数据耦合。数据库表中包含的用户账号数据,这部分数据个人看来实际上需要把库独立出来,另一方面三方账号的数据在新开三方账号系统的时候也应该迁移出来,hr数据库最后只保留员工,部门等数据。然后服务之间依据这些库重新梳理。这样设想的理由是用户账号实际上是用户中心,属于用户域的一个子域,同时三方员工信息和内部员工信息实际上也是用户域的一个子域。三者独立出来各自发展通过微服务调用的方式进行业务数据交互会更加合理,可扩展也更强。不过如果这么做的话会影响已有服务的稳定性,会存在数据同步的问题,也存在跨库join的问题,因此结论上看,拆是合理的,不拆也有不拆的理由。 - 多服务之间的服务调用的尴尬
这里通过员工入职创建用户账号的例子来说明hr服务之间基于同一个数据库进行相互调用的过程。如下泳道图是一个简单的员工入职账号开通流程:
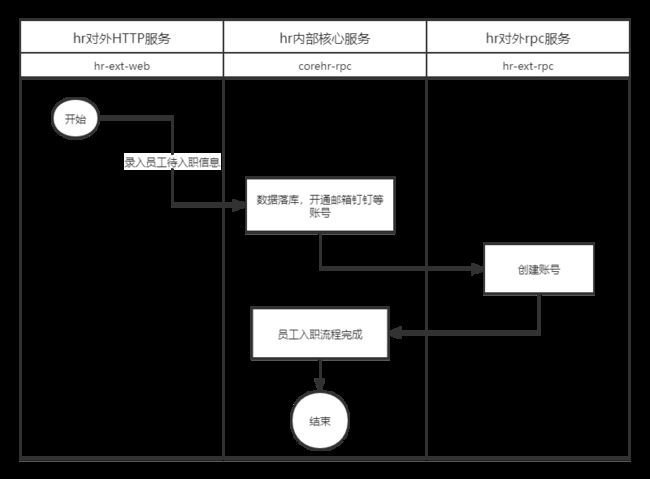
这里实际上如果从单库服务来说并不需要这些服务之间的调用,理论上一个服务即可完成。这么做的目的也是为了减少corehr服务的开发和维护成本,实际上如果以用户中心的角度去看账号体系的话那么corehr-rpc服务应该跟sso相关的服务去联调。 - 微服务拆分的方法论,规范,实践的探讨
通过hr服务的迭代演进过程中可知,微服务落地实际上并不容易,如果没有各方面的支持实际上是达不到很好的效果的。我认为以下几点可以帮忙在微服务落地实践中提供很好的帮助
1.首先要有基础框架和相关理论思想的支持,比如服务监控,降级,服务devops等。
2.需要有人对部门所有服务有个全局的思考,类似架构师的角色,对各个域和服务进行量化和边界划分。
3.服务之间调用需要统一api接口规范,明确异常编码等。
4.对数据表层面进行更好的管理,明确不同功能域对应的不同表。
5.对服务层来说要及时扩展和下线相关服务,确保整个功能域中都是有用而且可以服用的代码接口。
6.新建微服务工程时需要考虑是否可以合理的纳入其他工程中,避免增加微服务的运维负担。
这里我给出一些参考博客供读者深入了解微服务在企业中的实践
参考文档:https://www.cnblogs.com/HigginCui/p/10450798.html
https://blog.csdn.net/weixin_45139605/article/details/90796758
https://www.cnblogs.com/skyme/p/13093501.html - 通过服务化来解决单库多服务的问题
首先引用一下架构师之路公众号的一篇文章来说明什么是服务化:https://blog.csdn.net/chexlong/article/details/92761333
由于hr服务相对稳定,数据增量不多,因此很多数据表可以放在一起存,不拆也就不拆了。但是这样确实会存在一个问题就是有些服务的并发量特别高,有些服务的读写特别高,而另外一些服务则比较低,共用一个库的情况下会引起另外一个问题就是集群增加比较多的情况下数据库链接会到极限,因此需要合理的划分不同服务对应的不同业务库。比如上文中将userservice单独作为服务进行扩展,与其他业务线业务逻辑解耦实现可扩展高可用。那么基于上文中描述的众多服务工程可以梳理出以下4条迭代路线:
1.以corehr-rpc服务为核心,以corehr-*服务工程为企业内部服务作为外延;
2.以hr-ext-rpc服务为核心,以hr-ext-HTTP等调用hr-ext-rpc获取用户数据进行业务操作的api作为外延;
3.以sso-rpc服务为核心,以sso-web工程等作为用户中心的外延。
4.以hr-new-thirduser-web为核心作为单体服务提供三方员工账号的管理功能。
从上面的迭代路线看,任何一条业务路线发展较快的话可以顺势拆分数据库表,然后独自发展自己领域内的功能服务。另外一方面可以将自己领域内负责的老旧服务推动下线,将提供冗余功能的服务收敛到统一的rpc服务中。同时如果有新的业务需求或者对接需求我们可以更容易分辨出需要从哪里开始下手开发迭代,比如sso-rpc提供用户信息获取的接口,hr-ext-rpc服务也提供同样的接口那么我会建议使用hr-ext-rpc服务。
以上就是我在企业信息化部门中遇到的一个典型的单库多服务下的微服务实践问题,欢迎大家品评。