Kafka简介及集群搭建详细流程
Kafka原理:
Kafka 是一个消息系统,原本开发自 LinkedIn,用作 LinkedIn 的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。现在它已被多家公司作为多种类型的数据管道和消息系统使用。活动流数据是几乎所有站点在对其网站使用情况做报表时都要用到的数据中最常规的部分。活动数据包括页面访问量(Page View)、被查看内容方面的信息以及搜索情况等内容。这种数据通常的处理方式是先把各种活动以日志的形式写入某种文件,然后周期性地对这些文件进行统计分析。运营数据指的是服务器的性能数据(CPU、IO 使用率、请求时间、服务日志等等数据),总的来说,运营数据的统计方法种类繁多。
· Kafka 专用术语
Broker:Kafka 集群包含一个或多个服务器,这种服务器被称为 broker。
Topic:每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 Topic。(物理上不同 Topic 的消息分开存储,逻辑上一个 Topic 的消息虽然保存于一个或多个 broker 上,但用户只需指定消息的 Topic 即可生产或消费数据而不必关心数据存于何处)。
Partition:Partition 是物理上的概念,每个 Topic 包含一个或多个 Partition。
Producer:负责发布消息到 Kafka broker。
Consumer:消息消费者,向 Kafka broker 读取消息的客户端。
Consumer Group:每个 Consumer 属于一个特定的 Consumer Group(可为每个 Consumer 指定 group name,若不指定 group name 则属于默认的 group)。
· Kafka 交互流程
Kafka 是一个基于分布式的消息发布-订阅系统,它被设计成快速、可扩展的、持久的。与其他消息发布-订阅系统类似,Kafka 在主题当中保存消息的信息。生产者向主题写入数据,消费者从主题读取数据。由于 Kafka 的特性是支持分布式,同时也是基于分布式的,所以主题也是可以在多个节点上被分区和覆盖的。
信息是一个字节数组,程序员可以在这些字节数组中存储任何对象,支持的数据格式包括 String、JSON、Avro。Kafka 通过给每一个消息绑定一个键值的方式来保证生产者可以把所有的消息发送到指定位置。属于某一个消费者群组的消费者订阅了一个主题,通过该订阅消费者可以跨节点地接收所有与该主题相关的消息,每一个消息只会发送给群组中的一个消费者,所有拥有相同键值的消息都会被确保发给这一个消费者。
Kafka 设计中将每一个主题分区当作一个具有顺序排列的日志。同处于一个分区中的消息都被设置了一个唯一的偏移量。Kafka 只会保持跟踪未读消息,一旦消息被置为已读状态,Kafka 就不会再去管理它了。Kafka 的生产者负责在消息队列中对生产出来的消息保证一定时间的占有,消费者负责追踪每一个主题 (可以理解为一个日志通道) 的消息并及时获取它们。基于这样的设计,Kafka 可以在消息队列中保存大量的开销很小的数据,并且支持大量的消费者订阅。
一、单节点:一个broker
实例图如下所示:

1、首先启动zookeeper服务
Kafka本身提供了启动zookeeper的脚本(在kafka/bin/目录下)和zookeeper配置文件(在kafka/config/目录下),首先进入Kafka的主目录(可通过 whereis kafka命令查找到)
bin/zookeeper-server-start.shconfig/zookeeper.properties
也可以使用已经配置好的zookeeper集群环境
2、启动kafka broker
bin/kafka-server-start.sh config/server.properties
3、创建仅有一个partition的topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
4、显示topic
bin/kafka-topics.sh --list --zookeeper localhost:2181
Test
5、用kafka提供的生产者客户端启动一个生产者进程来发送消息
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
This is a message
This is another message
其中有两个参数需要注意:
broker-list:定义了生产者要推送消息的broker地址,以
topic:生产者发送给哪个topic
6、启动一个consumer实例来消费消息
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
This is a message
This is another message
二、单节点:多个broker
示例图如下所示
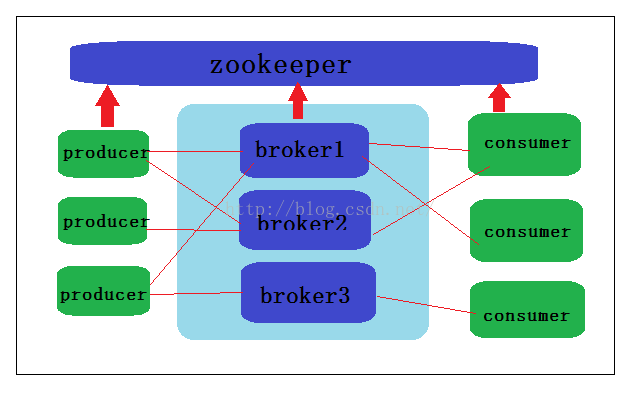
此时,只需要将config目录下的server.properties复制两份
> cp config/server.properties config/server-1.properties > cp config/server.properties config/server-2.properties
然后分别修改以上两个文件
config/server-1.properties: broker.id=1 port=9093 log.dirs=/tmp/kafka-logs-1
config/server-2.properties: broker.id=2 port=9094 log.dirs=/tmp/kafka-logs-2
1、启动zookeeper
2、分别启动三个broker
> bin/kafka-server-start.sh config/server.properties &...
> bin/kafka-server-start.sh config/server-1.properties &...> bin/kafka-server-start.sh config/server-2.properties &...
3、创建一个topic
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
4、查看该topic情况
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 1
Replicas: 1,2,0 Isr: 1,2,0
5、启动Producer发送消息
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic...
my test message 1
my test message 2
^C
6、启动一个消费者来消费消息
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic
...
my test message 1
my test message 2
^C
三、集群模式(多节点,多个broker)
示例图如下所示
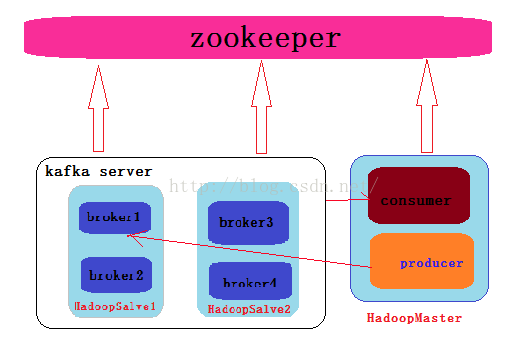
配置:
将config目录下的server.properties复制四四份
分别命名为server-1.properties,server-2.properties,server-3.properties
将四个配置文件里的
Broker.id分别取值为0,1,2,3
Port分别取值为:9092,9093,9094,9095
关键是设置:
zookeeper.connect=hadoopSalve1:2181,hadoopSalve2:2181
那么我们有四个配置文件,我们可以分别在两台机器上启动两个kafka
将完善的kafka文件夹发送到三台机器的相应目录
至此,一切ok,当然,我的zookeeper集群是配置在三台机器上的,也相应地启动好了
那么,来总结一下
Kafka集群的搭建(如上图所示)
环境:centos6.4,三台机器:hadoopMaster,hadoopSalve1,hadoopSalve2
三台机器上将配置好的kafka放到/usr/local/bigdata/目录下
hadoopSalve1:启动两个kafka broker broker-id:0,1 port:9092 9093
hadoopSalve2: 启动两个kafka broker broker-id:2,3 port:9094 9095
hadoopMaster: 启动一个producer发生消息,启动一个consumer消费消息
如下测试:
1、启动producer发送消息
[root@hadoopSalve2 kafka]# bin/kafka-console-producer.sh --broker-list hadoopSalve1:9092 --topic hadoopSalve1
[2015-08-26 01:45:02,023] WARN Property topic is not valid (kafka.utils.VerifiableProperties)
zaima
nihaoa
2、启动一个消费者消费消息
[root@hadoopSalve1 kafka]# bin/kafka-console-consumer.sh --zookeeper hadoopSalve2:2181 --from-beginning --topic hadoopSalve1
zaima
nihaoa
再测试,我们可以将producer放在没有启动broker的节点上,也将一个消费者在没有启动broker的节点上启动来消费消息
1、启动producer发送消息
[root@hadoopMaster kafka]# bin/kafka-console-producer.sh --broker-list hadoopSalve1:9092 --topic hadoopSalve1
hh
doubi
wocao
2、启动消费者消费消息
[root@hadoopMaster kafka]# bin/kafka-console-consumer.sh --zookeeper hadoopSalve2:2181 --from-beginning --topic hadoopSalve1
hh
doubi
wocao