跟我一起学PyTorch-09:PyTorch项目实战
在前面章节中,深入阐述了PyTorch和深度学习的基础知识,包括PyTorch的安装、常用命令和基本操作,讲述了深度神经网络、卷积神经网络、循环神经网络和自编码器等。初步学习了深度学习在图形分类、自然语言处理等方面的应用。
本章将着眼现实世界中的实际问题,运用深度学习的技术来解决。从数据的采集和预处理、模型的搭建,不断地调整模型参数,最后得到优化的结果。经历完整的开发流程,可以加深对深度学习的理解。同时,在算法的开发过程中,通过对实际场景的应用,明白各种算法的应用场景和局限,知道如何深入地调整模型结构和参数,最重要的是提高自己的工程应用能力。本章通过三个项目实战例子来介绍深度学习在实际场景——图像识别、自然语言处理以及语音识别中的应用。
1.图像识别和迁移学习——猫狗大战
图像识别是深度学习最先取得突破的地方,其实验使用的数据集一般是MNIST和ImageNet。在Kaggle图像识别竞赛中使用的数据集都是猫和狗,因而形象的称为猫狗大战。在本小节中,使用之前章节学习过的深度神经网络、卷积神经网络对猫狗进行识别,在实验结果欠拟合的情况下,使用迁移学习这个强有力的武器,把实验结果精确度立刻提高上来。
1.迁移学习介绍
随着深度神经网络越来越强大,监督学习下的很多场景能够很好地解决,比如在图像、语音、文本的场景下,能够非常准确地学习从大量的有标签的数据中输入到输出的映射。但是这种在特定环境下训练出来的模型,仍然缺乏泛化到其他不同环境的能力。比如将训练好的模型用到现实场景,而不是特地构建的数据集的时候,模型的性能大打折扣。这是因为现实的场景是混乱的,并且包含大量的全新的场景,尤其是很多是模型在训练的时候未曾遇到的,这使得模型做不出好的预测。同时,存在大量这样的情况,以语言识别为例,一些小语种的训练数据过小,而深度神经网络又需要大量的训练数据。如何解决这些问题?一种新的方法登场了,这种将知识迁移到新环境中的方法通常被称为迁移学习(Transfer Learning)。在猫和狗的图像识别中,直接使用卷积神经网络并不是很好,使用迁移学习后,识别的性能大大提高,有力地说明迁移学习的有效性。迁移学习一般用于迁移任务是相关的场景,在相似任务的数据上应用效果才是最好的。
2.计算机视觉工具包
计算机视觉是深度学习中最重要的一种应用,为了方便人们的研究和使用,PyTorch团队开发了计算机视觉工具包torchvision。这个包独立于PyTorch,可以通过pip install torchvision安装,当然,在Anaconda中也可以通过conda install torchvision安装。这里对torchvision工具包做一个系统的介绍。torchvision主要分为3个部分:
(1)models:提供深度学习中各个经典网络的网络结构和预训练好的各个模型,包括AlexNet、VGG系列、ResNet系列、Inception系列等。
(2)datasets:提供常用的数据集加载函数,设计上继承torch.utils.data.Dataset,同时包括常见的图像识别数据集MNIST、CIFAR-10、CIFAR-100、ImageNet、COCO等。
(3)transforms:提供常见的数据预处理操作,主要包括对Tensor和PIL Image对象的操作。
3.猫狗大战的PyTorch实现
(1)数据预处理
Kaggle竞赛的猫狗数据集在官网下载、网盘下载。猫狗大战数据集比较大,单机跑很吃力,这里选择前1000张狗狗图片和前1000张猫猫图片作为初始数据集,通过预处理按9:1分成训练集和测试集。preprocess_data.py:
# coding=utf-8
import os
import shutil
import numpy as np
# 随机种子设置
random_state = 42
np.random.seed(random_state)
# kaggle原始数据集地址
original_dataset_dir = 'data/all'
total_num = int(len(os.listdir(original_dataset_dir)) / 2)
random_idx = np.array(range(total_num))
np.random.shuffle(random_idx)
# 待处理的数据集地址
base_dir = 'data'
if not os.path.exists(base_dir):
os.mkdir(base_dir)
# 训练集、测试集的划分
sub_dirs = ['train', 'test']
animals = ['cats', 'dogs']
train_idx = random_idx[:int(total_num * 0.9)]
test_idx = random_idx[int(total_num * 0.9):]
numbers = [train_idx, test_idx]
for idx, sub_dir in enumerate(sub_dirs):
dir = os.path.join(base_dir, sub_dir)
if not os.path.exists(dir):
os.mkdir(dir)
for animal in animals:
animal_dir = os.path.join(dir, animal)
if not os.path.exists(animal_dir):
os.mkdir(animal_dir)
fnames = [animal[:-1] + '.{}.jpg'.format(i) for i in numbers[idx]]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(animal_dir, fname)
shutil.copyfile(src, dst)
# 打印训练集、测试集数目数目
print(animal_dir + ' total images : %d' % (len(os.listdir(animal_dir))))
结果如下:
data\train\cats total images : 900
data\train\dogs total images : 900
data\test\cats total images : 100
data\test\dogs total images : 100
(2)定义模型,训练模型,评估模型,main.py:
from __future__ import print_function, division
import time
import os
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data import Dataset
from torchvision import transforms, datasets, models
# 配置参数
random_state = 1
torch.manual_seed(random_state) # 设置随机数种子,确保结果可重复
torch.cuda.manual_seed(random_state)
torch.cuda.manual_seed_all(random_state)
np.random.seed(random_state)
epochs = 100 # 训练次数
batch_size = 10 # 批处理大小
num_workers = 8 # 多线程的数目
model = 'model.pt' # 把训练好的模型保存下来
use_gpu = torch.cuda.is_available()
# 对加载的图像作归一化处理, 并裁剪为[224x224x3]大小的图像
data_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 在训练集中,shuffle必须设置为True,表示次序是随机的
train_dataset = datasets.ImageFolder(root='data/train/', transform=data_transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers)
# 在测试集中,shuffle必须设置为False,表示每个样本都只出现一次
test_dataset = datasets.ImageFolder(root='data/test/', transform=data_transform)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers)
# 创建CNN模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.maxpool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 53 * 53, 1024)
self.fc2 = nn.Linear(1024, 512)
self.fc3 = nn.Linear(512, 2)
def forward(self, x):
x = self.maxpool(F.relu(self.conv1(x)))
x = self.maxpool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 53 * 53)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 定义训练函数:将训练好的模型保存
def train():
net = models.resnet18(pretrained=False)
num_ftrs = net.fc.in_features
net.fc = nn.Linear(num_ftrs, 2)
print('模型:', net)
if use_gpu:
net = net.cuda()
print('CUDA:', use_gpu)
# 定义loss和optimizer
cirterion = nn.CrossEntropyLoss()
print('损失函数:', cirterion)
optimizer = optim.SGD(net.parameters(), lr=0.0001, momentum=0.9)
print('优化器:', optimizer)
# 开始训练
net.train()
print('开始训练...')
start = time.time()
for epoch in range(epochs):
start1 = time.time()
running_loss = 0.0
train_correct = 0
train_total = 0
for images, labels in train_loader:
if use_gpu:
images, labels = Variable(images.cuda()), Variable(labels.cuda())
else:
images, labels = Variable(images), Variable(labels)
optimizer.zero_grad()
outputs = net(images)
_, train_predicted = torch.max(outputs.data, 1)
train_correct += (train_predicted == labels.data).sum()
loss = cirterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss
train_total += labels.size(0)
end1 = time.time()
print('epoch:{%d/%d} loss: {%.6f} acc: {%.6f} time: {%d 秒}' %
(epoch + 1, epochs, running_loss / train_total, float(train_correct) / float(train_total), end1 - start1))
torch.save(net, model)
end = time.time()
print("训练完毕!总耗时:%d 秒" % (end - start))
# 定义测试函数:加载训练好的模型,评估其性能
def test():
print('开始评估...')
net = torch.load(model)
net.eval()
correct = 0
test_loss = 0.0
test_total = 0
cirterion = nn.CrossEntropyLoss()
start = time.time()
for images, labels in test_loader:
if use_gpu:
images, labels = Variable(images.cuda()), Variable(labels.cuda())
else:
images, labels = Variable(images), Variable(labels)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
loss = cirterion(outputs, labels)
test_loss += loss
test_total += labels.size(0)
correct += (predicted == labels.data).sum()
print('loss: {%.6f} acc: {%.6f} ' % (test_loss / test_total, float(correct) / float(test_total)))
end = time.time()
print("评估完毕!总耗时:%d 秒" % (end - start))
# 主函数:如果模型不存在,则训练并测试;如果模型存在,则只测试。
def main():
if os.path.exists(model):
test()
else:
train()
test()
if __name__ == '__main__':
main()
结果如下:
C:\ProgramData\Anaconda3\python.exe E:/workspace/python/dogs-vs-cats/convert.py
模型: ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=2, bias=True)
)
CUDA: True
损失函数: CrossEntropyLoss()
优化器: SGD (
Parameter Group 0
dampening: 0
lr: 0.0001
momentum: 0.9
nesterov: False
weight_decay: 0
)
开始训练...
epoch:{1/100} loss: {0.069481} acc: {0.540000} time: {17 秒}
epoch:{2/100} loss: {0.066797} acc: {0.585000} time: {15 秒}
epoch:{3/100} loss: {0.065948} acc: {0.609444} time: {15 秒}
epoch:{4/100} loss: {0.065300} acc: {0.613333} time: {15 秒}
epoch:{5/100} loss: {0.064805} acc: {0.617778} time: {15 秒}
epoch:{6/100} loss: {0.063552} acc: {0.636111} time: {15 秒}
epoch:{7/100} loss: {0.062005} acc: {0.658333} time: {15 秒}
epoch:{8/100} loss: {0.062005} acc: {0.667222} time: {15 秒}
epoch:{9/100} loss: {0.061178} acc: {0.678333} time: {15 秒}
epoch:{10/100} loss: {0.060407} acc: {0.670556} time: {15 秒}
……
epoch:{91/100} loss: {0.004315} acc: {0.981111} time: {15 秒}
epoch:{92/100} loss: {0.004754} acc: {0.983889} time: {15 秒}
epoch:{93/100} loss: {0.003877} acc: {0.988889} time: {15 秒}
epoch:{94/100} loss: {0.004233} acc: {0.984444} time: {15 秒}
epoch:{95/100} loss: {0.005921} acc: {0.977778} time: {15 秒}
epoch:{96/100} loss: {0.002608} acc: {0.991667} time: {15 秒}
epoch:{97/100} loss: {0.003761} acc: {0.985000} time: {15 秒}
epoch:{98/100} loss: {0.005136} acc: {0.983889} time: {15 秒}
epoch:{99/100} loss: {0.003277} acc: {0.985556} time: {15 秒}
epoch:{100/100} loss: {0.003656} acc: {0.988333} time: {15 秒}
训练完毕!总耗时:1695 秒
开始评估...
loss: {0.114807} acc: {0.740000}
评估完毕!总耗时:5 秒
这里训练结果准确率高到98%,测试结果准确率却只有74%,模型有点过拟合。我们可以增加数据规模,或者简化模型参数来优化模型。这里不再演示。
2.文本分类
文本分类时自然语言处理中一个非常经典的应用,应用的领域包括文章分类、邮件分类、垃圾邮件识别、用户情感识别等。传统文本分类方法的思路是分析分类的目标,从文档中提取与之相关的特征,把特征送入指定的分类器,训练分类模型对文章进行分类。整个文本分类问题分为特征提取和分类器两个部分。比较经典的特征提取方法有频次法、IF-IDF法、互信息法、N-Gram法等;分类器包括LR(线性回归模型)、KNN、SVM(支持向量机)、朴素贝叶斯方法、最大熵、神经网络、随机森林等。
自从深度学习在图像、语言、机器翻译等领域取得成功后,深度学习在NLP上也使用的越来越广泛。在传统的文本分类中,文本表示都是稀疏的,特征表达能力弱,神经网络并不擅长对此类问题的处理;此外,需要提取特定的特征,花费时间和精力在特征分析和提取上。应用深度学习解决大规模文本分类最重要的问题是解决文本表示,再利用CNN或RNN等深度神经网络结构自动获取特征表达能力,去除思路繁杂的特征提取,让神经网络自动提取有效的特征,端到端的解决问题。文本表示采用词向量的方法,文本分类模型利用CNN等神经网络模型解决自动特征提取的问题。
1.文本分类介绍
CNN(卷积神经网络)在图像识别领域取得了令人瞩目的成绩,可以说谁深度学习崛起的突破点,具体内容在前面章节已有介绍。但在NLP(自然语言处理)领域,深度学习的进展比较缓慢。尽管如此,深度学习在NLP的一些领域也取得了骄人的成绩。例如,在文本分类的任务上,基于卷积神经网络的算法就取得了比传统方法更好的效果。
现在采用CNN对文本进行分类,具体算法框架如下所示。

CNN文本分类的详细过程是:第一层是图中最左边的句子矩阵,每行是词向量,这个可以类比为图像中的原始像素点。第二层是filter_size=(3,4,5)的二维卷积层,每个filter_size有两个输出channel。第三层是一个max_pooling层,这样不同长度的句子经过pooling层之后都会变成长度相同的表示。最后接一个全连接的Softmax层,输出每个类别的概率。
特征:在CNN文本分类中,输入特征是词向量,可以采用预训练的词向量如GloVe来初始化词向量,训练过程中调整词向量能加速收敛,如果有大量且丰富的训练数据,直接初始化词向量的效果也是可以的。
CNN实现文本分类的原理如下:
(1)把输入的句子转换为词向量,通常使用Word2Vec方法实现:具体在PyTorch中调用Embedding函数。
(2)卷积神经网络由3个并联的卷积层、一个max_pooling层和全连接层构成。
(3)在具体的算法实践中,优化策略可以考虑Dropout、使用预训练的Word2Vec(如GloVe)、参数初始化设置等。
2.计算机文本工具包
自然语言处理时深度学习中重要的一类应用。为了方便研究和使用,有团队开发了计算机文本工具包torchtext,这个包独立于PyTorch,一般可以通过pip install torchtext安装。当然,在anaconda中也可以通过conda install torchtext安装。torchtext主要分为以下3个部分:
(1)Field:主要是文本数据预处理的配置,包括指定分词方法、是否转成小写、起始字符、结束字符、补全字符以及字典等。提供词向量中各个神经网络的网络结构和预训练好的各个模型,包括glove.6B系列、charngram系列、fasttext系列等。
(2)datasets:加载函数,并提供常用的数据集,设计上继承torch.utils.data.Dataset,同时包括常见的文本数据集的Dataset对象,可以直接加载使用,splits方法可以同时加载训练集、验证集和测试集。
(3)Iterator:主要提供数据输出模型的迭代器,支持batch定制。
3.基于CNN的文本分类的PyTorch实现
本实验使用的待分类数据集为20Newsgroups,这个数据集一共有20个种类的新闻文本,数据量比较大,单机跑有些吃力,这里我们只拿其中少数几个分类的数据来做实验。另外,使用的预训练好的词向量数据集为glove.6B,这个数据集有100维、200维、300维的词向量可以选择使用。
(1)数据预处理 data_preprocess.py
import os
import re
import tarfile
import urllib
from torchtext import data
class TarDataset(data.Dataset):
"""Defines a Dataset loaded from a downloadable tar archive.
Attributes:
url: URL where the tar archive can be downloaded.
filename: Filename of the downloaded tar archive.
dirname: Name of the top-level directory within the zip archive that
contains the data files.
"""
@classmethod
def download_or_unzip(cls, root):
path = os.path.join(root, cls.dirname)
if not os.path.isdir(path):
tpath = os.path.join(root, cls.filename)
if not os.path.isfile(tpath):
print('downloading')
urllib.request.urlretrieve(cls.url, tpath)
with tarfile.open(tpath, 'r') as tfile:
print('extracting')
tfile.extractall(root)
return os.path.join(path, '')
class NEWS_20(TarDataset):
url = 'http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz'
filename = 'data/20news-bydate-train'
dirname = ''
@staticmethod
def sort_key(ex):
return len(ex.text)
def __init__(self, text_field, label_field, path=None, text_cnt=1000, examples=None, **kwargs):
"""Create an MR dataset instance given a path and fields.
Arguments:
text_field: The field that will be used for text data.
label_field: The field that will be used for label data.
path: Path to the data file.
examples: The examples contain all the data.
Remaining keyword arguments: Passed to the constructor of
data.Dataset.
"""
def clean_str(string):
"""
Tokenization/string cleaning for all datasets except for SST.
Original taken from https://github.com/yoonkim/CNN_sentence/blob/master/process_data.py
"""
string = re.sub(r"[^A-Za-z0-9(),!?\'\`]", " ", string)
string = re.sub(r"\'s", " \'s", string)
string = re.sub(r"\'ve", " \'ve", string)
string = re.sub(r"n\'t", " n\'t", string)
string = re.sub(r"\'re", " \'re", string)
string = re.sub(r"\'d", " \'d", string)
string = re.sub(r"\'ll", " \'ll", string)
string = re.sub(r",", " , ", string)
string = re.sub(r"!", " ! ", string)
string = re.sub(r"\(", " \( ", string)
string = re.sub(r"\)", " \) ", string)
string = re.sub(r"\?", " \? ", string)
string = re.sub(r"\s{2,}", " ", string)
return string.strip().lower()
text_field.preprocessing = data.Pipeline(clean_str)
fields = [('text', text_field), ('label', label_field)]
categories = ['alt.atheism',
'comp.graphics',
'comp.os.ms-windows.misc',
'comp.sys.ibm.pc.hardware',
'comp.sys.mac.hardware',
'comp.windows.x',
'misc.forsale',
'rec.autos',
'rec.motorcycles',
'rec.sport.baseball',
'rec.sport.hockey',
'sci.crypt',
'sci.electronics',
'sci.med',
'sci.space',
'soc.religion.christian',
'talk.politics.guns',
'talk.politics.mideast',
'talk.politics.misc',
'talk.religion.misc'
]
# 数据集有20个分类,单机有些吃力,这里只选少量分类进行测试
categories = categories[:4]
if examples is None:
path = self.dirname if path is None else path
examples = []
for sub_path in categories:
sub_path_one = os.path.join(path, sub_path)
sub_paths_two = os.listdir(sub_path_one)
cnt = 0
for sub_path_two in sub_paths_two:
lines = ""
with open(os.path.join(sub_path_one, sub_path_two), encoding="utf8", errors='ignore') as f:
lines = f.read()
examples += [data.Example.fromlist([lines, sub_path], fields)]
cnt += 1
super(NEWS_20, self).__init__(examples, fields, **kwargs)
@classmethod
def splits(cls, text_field, label_field, root='./data',
train='20news-bydate-train', test='20news-bydate-test',
**kwargs):
"""Create dataset objects for splits of the 20news dataset.
Arguments:
text_field: The field that will be used for the sentence.
label_field: The field that will be used for label data.
train: The filename of the train data. Default: 'train.txt'.
Remaining keyword arguments: Passed to the splits method of
Dataset.
"""
path = cls.download_or_unzip(root)
train_data = None if train is None else cls(
text_field, label_field, os.path.join(path, train), 0, **kwargs)
dev_ratio = 0.1
dev_index = -1 * int(dev_ratio * len(train_data))
return (cls(text_field, label_field, examples=train_data[:dev_index]),
cls(text_field, label_field, examples=train_data[dev_index:]))
(2)定义模型 model.py
import torch
import torch.nn as nn
import torch.nn.functional as F
class CNN_Text(nn.Module):
def __init__(self, args):
super(CNN_Text, self).__init__()
self.args = args
embed_num = args.embed_num
embed_dim = args.embed_dim
class_num = args.class_num
Ci = 1
kernel_num = args.kernel_num
kernel_sizes = args.kernel_sizes
self.embed = nn.Embedding(embed_num, embed_dim)
self.convs_list = nn.ModuleList(
[nn.Conv2d(Ci, kernel_num, (kernel_size, embed_dim)) for kernel_size in kernel_sizes])
self.dropout = nn.Dropout(args.dropout)
self.fc = nn.Linear(len(kernel_sizes) * kernel_num, class_num)
def forward(self, x):
x = self.embed(x)
x = x.unsqueeze(1)
x = [F.relu(conv(x)).squeeze(3) for conv in self.convs_list]
x = [F.max_pool1d(i, i.size(2)).squeeze(2) for i in x]
x = torch.cat(x, 1)
x = self.dropout(x)
x = x.view(x.size(0), -1)
logit = self.fc(x)
return logit
(3)训练和评估 mian.py
import argparse
import random
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchtext.data as data
import model
import mydatasets
random_state = 1
torch.manual_seed(random_state)
torch.cuda.manual_seed(random_state)
torch.cuda.manual_seed_all(random_state)
np.random.seed(random_state)
random.seed(random_state)
parser = argparse.ArgumentParser(description='CNN text classificer')
# learning
parser.add_argument('-lr', type=float, default=0.001, help='initial learning rate [default: 0.001]')
parser.add_argument('-epochs', type=int, default=20, help='number of epochs for train [default: 20]')
parser.add_argument('-batch-size', type=int, default=128, help='batch size for training [default: 64]')
# data
parser.add_argument('-shuffle', action='store_true', default=False, help='shuffle the data every epoch')
# model
parser.add_argument('-dropout', type=float, default=0.2, help='the probability for dropout [default: 0.5]')
parser.add_argument('-embed-dim', type=int, default=100, help='number of embedding dimension [default: 100]')
parser.add_argument('-kernel-num', type=int, default=100, help='number of each kind of kernel, 100')
parser.add_argument('-kernel-sizes', type=str, default='3,5,7',
help='comma-separated kernel size to use for convolution')
parser.add_argument('-static', action='store_true', default=False, help='fix the embedding')
# device
parser.add_argument('-device', type=int, default=-1, help='device to use for iterate data, -1 mean cpu [default: -1]')
parser.add_argument('-no-cuda', action='store_true', default=False, help='disable the gpu')
args = parser.parse_args()
# load 20new dataset
def new_20(text_field, label_field, **kargs):
train_data, dev_data = mydatasets.NEWS_20.splits(text_field, label_field)
max_document_length = max([len(x.text) for x in train_data.examples])
print('train max_document_length', max_document_length)
max_document_length = max([len(x.text) for x in dev_data])
print('dev max_document_length', max_document_length)
text_field.build_vocab(train_data, dev_data)
text_field.vocab.load_vectors('glove.6B.100d')
label_field.build_vocab(train_data, dev_data)
train_iter, dev_iter = data.Iterator.splits(
(train_data, dev_data),
batch_sizes=(args.batch_size, len(dev_data)),
**kargs)
return train_iter, dev_iter, text_field
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv2d') != -1:
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
nn.init.xavier_normal_(m.weight.data)
m.bias.data.fill_(0)
elif classname.find('Linear') != -1:
m.weight.data.normal_(0.0, 0.02)
m.bias.data.fill_(0)
# load data
print("Loading data...")
text_field = data.Field(lower=True)
label_field = data.Field(sequential=False)
train_iter, dev_iter, text_field = new_20(text_field, label_field, repeat=False)
# update args and print
args.embed_num = len(text_field.vocab)
args.class_num = len(label_field.vocab) - 1
args.cuda = (not args.no_cuda) and torch.cuda.is_available()
del args.no_cuda
args.kernel_sizes = [int(k) for k in args.kernel_sizes.split(',')]
print("\nParameters:")
for attr, value in sorted(args.__dict__.items()):
print("\t{}={}".format(attr.upper(), value))
# model
cnn = model.CNN_Text(args)
# load pre-training glove model
cnn.embed.weight.data = text_field.vocab.vectors
# weight init
cnn.apply(weights_init) #
# print net
print(cnn)
if args.cuda:
torch.cuda.set_device(args.device)
cnn = cnn.cuda()
optimizer = torch.optim.Adam(cnn.parameters(), lr=args.lr, weight_decay=0.01)
# train
cnn.train()
for epoch in range(1, args.epochs + 1):
corrects, avg_loss = 0, 0
for batch in train_iter:
feature, target = batch.text, batch.label
feature = feature.data.t() # 转置
target = target.data.sub(1) # 减1
if args.cuda:
feature, target = feature.cuda(), target.cuda()
optimizer.zero_grad()
logit = cnn(feature)
loss = F.cross_entropy(logit, target)
loss.backward()
optimizer.step()
avg_loss += loss
corrects += (torch.max(logit, 1)[1].view(target.size()).data == target.data).sum()
size = len(train_iter.dataset)
avg_loss /= size
accuracy = 100.0 * float(corrects) / float(size)
print('epoch[{}] Traning - loss: {:.6f} acc: {:.4f}%({}/{})'.format(epoch, avg_loss, accuracy, corrects, size))
# test
cnn.eval()
corrects, avg_loss = 0, 0
for batch in dev_iter:
feature, target = batch.text, batch.label
feature = feature.data.t() # 转置
target = target.data.sub(1) # 减1
if args.cuda:
feature, target = feature.cuda(), target.cuda()
logit = cnn(feature)
loss = F.cross_entropy(logit, target, reduction='sum')
avg_loss += loss
corrects += (torch.max(logit, 1)
[1].view(target.size()).data == target.data).sum()
size = len(dev_iter.dataset)
avg_loss /= size
accuracy = 100.0 * float(corrects) / float(size)
print('Evaluation - loss: {:.6f} acc: {:.4f}%({}/{}) '.format(avg_loss, accuracy, corrects, size))
结果如下:
Loading data...
train max_document_length 9168
dev max_document_length 3754
Parameters:
BATCH_SIZE=128
CLASS_NUM=4
CUDA=True
DEVICE=-1
DROPOUT=0.2
EMBED_DIM=100
EMBED_NUM=64463
EPOCHS=20
KERNEL_NUM=100
KERNEL_SIZES=[3, 5, 7]
LR=0.001
SHUFFLE=False
STATIC=False
CNN_Text(
(embed): Embedding(64463, 100)
(convs_list): ModuleList(
(0): Conv2d(1, 100, kernel_size=(3, 100), stride=(1, 1))
(1): Conv2d(1, 100, kernel_size=(5, 100), stride=(1, 1))
(2): Conv2d(1, 100, kernel_size=(7, 100), stride=(1, 1))
)
(dropout): Dropout(p=0.2)
(fc): Linear(in_features=300, out_features=4, bias=True)
)
epoch[1] Traning - loss: 0.009915 acc: 54.8738%(1109/2021)
epoch[2] Traning - loss: 0.006585 acc: 74.0722%(1497/2021)
epoch[3] Traning - loss: 0.004464 acc: 81.5438%(1648/2021)
epoch[4] Traning - loss: 0.003681 acc: 84.3642%(1705/2021)
epoch[5] Traning - loss: 0.003188 acc: 86.7392%(1753/2021)
epoch[6] Traning - loss: 0.002859 acc: 89.9060%(1817/2021)
epoch[7] Traning - loss: 0.002631 acc: 91.8357%(1856/2021)
epoch[8] Traning - loss: 0.002406 acc: 93.1222%(1882/2021)
epoch[9] Traning - loss: 0.002231 acc: 94.1613%(1903/2021)
epoch[10] Traning - loss: 0.002147 acc: 94.0129%(1900/2021)
epoch[11] Traning - loss: 0.001999 acc: 95.1014%(1922/2021)
epoch[12] Traning - loss: 0.001909 acc: 96.2395%(1945/2021)
epoch[13] Traning - loss: 0.001855 acc: 95.8436%(1937/2021)
epoch[14] Traning - loss: 0.001763 acc: 96.7838%(1956/2021)
epoch[15] Traning - loss: 0.001770 acc: 96.1405%(1943/2021)
epoch[16] Traning - loss: 0.001639 acc: 97.3281%(1967/2021)
epoch[17] Traning - loss: 0.001612 acc: 97.1796%(1964/2021)
epoch[18] Traning - loss: 0.001606 acc: 97.0312%(1961/2021)
epoch[19] Traning - loss: 0.001589 acc: 97.2291%(1965/2021)
epoch[20] Traning - loss: 0.001547 acc: 98.0703%(1982/2021)
Evaluation - loss: 0.836256 acc: 67.8571%(152/224)
从输出结果可以看出,模型的训练效果要比测试效果好,我们可以尝试调整模型参数对模型进行优化。
3.语音识别
语音识别是自动将人类语音转换为相应文字的技术。语音识别的应用包括语音拨号、语音导航、车载控制、语音检索、听写、人工交互、语音搜索、人工智能助理等。语音识别技术包括命令词识别、连续语音识别、关键词识别等。传统的语言识别技术是基于GMM-HMM模型的。语音识别系统包括下图所示的几个基本模块(在孤立词识别中,可以不使用语音模型)。
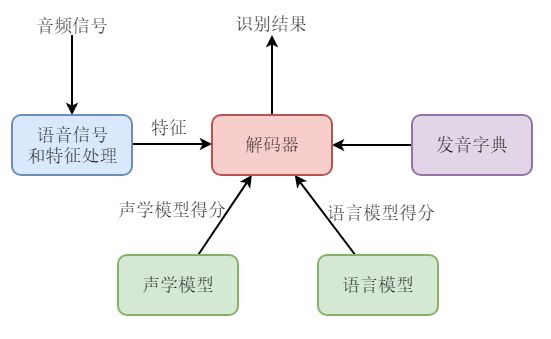
- 语音信号和特征处理模块。该模块从输入信号中提取特征,供声学模型处理。
- 声学模型。典型系统多采用基于隐马尔可夫模型进行建模。
- 发音字典。发音字典包含系统所能处理的词汇及其发音。发音字典实际提供了声学模型建模单元与语言模型建模单元之间的映射。
- 语言模型。语言模型对系统所针对的语言进行建模。
- 解码器。解码器是语音识别系统的核心之一,其任务是对输入的信号,根据声学模型、语言模型及发音字典,寻找能够以最大概率输出该信号的词串。
传统的语音识别是以GMM-HMM(混合高斯模型-隐马尔可夫)声学模型为基础的。随着深度学习的兴起,语音识别逐渐被深度学习改造。目前,市面上主流的语音识别系统都包含有深度学习算法。
1.语音识别介绍
在深度学习兴起以后,对语音识别的改进提供了很大的帮助。本节以简单命令词的语音识别来说明深度学习在语音识别上的应用。真正的语音识别要比这个复杂的多,就像通过MNIST数据集来学习基于深度神经网络的图像识别一样,通过命令词识别来对基于深度神经网络语音识别技术有个基本的了解。学习完本节,将能够使用一个模型把时长1秒左右的音频识别为“yes”、“no”、“up”、“down”等十多个命令词。我们还将学习到数据的预处理、音频的特征提取、模型的搭建和训练、测试及音频的识别等知识。
2.命令词识别的PyTorch实现
(1)数据集准备
在工程下分别创建org_data和data两个文件夹,下载命令词语音识别数据集speech_commands_v0.01.tar.gz,放到org_data文件夹并解压。执行make_dataset.py文件把数据集划分为:训练集、验证集和测试集,并放到data文件夹下面。可以看到这个数据集一共有30个命令词,数据量有点大,单机跑优点吃力,我这里手动选择前5个命令词,并保证每个命令词样本的数量为:训练集:验证集:测试集=800:100:100。make_dataset.py代码如下:
import argparse
import os
import shutil
# 把文件从源文件夹移动到目标文件夹
def move_files(original_fold, data_fold, data_filename):
with open(data_filename) as f:
for line in f.readlines():
vals = line.split('/')
dest_fold = os.path.join(data_fold, vals[0])
if not os.path.exists(dest_fold):
os.mkdir(dest_fold)
shutil.move(os.path.join(original_fold, line[:-1]), os.path.join(data_fold, line[:-1]))
# 建立train文件夹
def create_train_fold(original_fold, train_fold, test_fold):
# 文件夹名列表
dir_names = list()
for file in os.listdir(test_fold):
if os.path.isdir(os.path.join(test_fold, file)):
dir_names.append(file)
# 建立训练文件夹train
for file in os.listdir(original_fold):
if os.path.isdir(os.path.join(test_fold, file)) and file in dir_names:
shutil.move(os.path.join(original_fold, file), os.path.join(train_fold, file))
# 建立数据集,train,valid, 和 test
def make_dataset(in_path, out_path):
validation_path = os.path.join(in_path, 'validation_list.txt')
test_path = os.path.join(in_path, 'testing_list.txt')
# train, valid, test三个数据集文件夹的建立
train_fold = os.path.join(out_path, 'train')
valid_fold = os.path.join(out_path, 'valid')
test_fold = os.path.join(out_path, 'test')
for fold in [valid_fold, test_fold, train_fold]:
if not os.path.exists(fold):
os.mkdir(fold)
# 移动train, valid, test三个数据集所需要的文件
move_files(in_path, test_fold, test_path)
move_files(in_path, valid_fold, validation_path)
create_train_fold(in_path, train_fold, test_fold)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Make speech commands dataset.')
parser.add_argument('--in_path', default='org_data',
help='the path to the root folder of te speech commands dataset.')
parser.add_argument('--out_path', default='data', help='the path where to save the files splitted to folders.')
args = parser.parse_args()
make_dataset(args.in_path, args.out_path)
(2)特征提取
在本实验中,需要用到librosa库提取音频的频谱特征。speech_loader.py的代码如下:
import os
import os.path
import librosa
import numpy as np
import torch
import torch.utils.data as data
# 音频数据格式,只允许wav和WAV
AUDIO_EXTENSIONS = [
'.wav', '.WAV',
]
# 判断是否是音频文件
def is_audio_file(filename):
return any(filename.endswith(extension) for extension in AUDIO_EXTENSIONS)
# 找到类名并索引
def find_classes(dir):
classes = [d for d in os.listdir(dir) if os.path.isdir(os.path.join(dir, d))]
classes.sort()
class_to_idx = {classes[i]: i for i in range(len(classes))}
return classes, class_to_idx
# 构造数据集
def make_dataset(dir, class_to_idx):
spects = []
dir = os.path.expanduser(dir)
for target in sorted(os.listdir(dir)):
d = os.path.join(dir, target)
if not os.path.isdir(d):
continue
for root, _, fnames in sorted(os.walk(d)):
for fname in sorted(fnames):
if is_audio_file(fname):
path = os.path.join(root, fname)
item = (path, class_to_idx[target])
spects.append(item)
return spects
# 频谱加载器, 处理音频,生成频谱
def spect_loader(path, window_size, window_stride, window, normalize, max_len=101):
y, sr = librosa.load(path, sr=None)
# n_fft = 4096
n_fft = int(sr * window_size)
win_length = n_fft
hop_length = int(sr * window_stride)
# 短时傅立叶变换
D = librosa.stft(y, n_fft=n_fft, hop_length=hop_length,
win_length=win_length, window=window)
spect, phase = librosa.magphase(D) # 计算幅度谱和相位
# S = log(S+1)
spect = np.log1p(spect) # 计算log域幅度谱
# 处理所有的频谱,使得长度一致,少于规定长度,补0到规定长度; 多于规定长度的, 截短到规定长度;
if spect.shape[1] < max_len:
pad = np.zeros((spect.shape[0], max_len - spect.shape[1]))
spect = np.hstack((spect, pad))
elif spect.shape[1] > max_len:
spect = spect[:max_len, ]
spect = np.resize(spect, (1, spect.shape[0], spect.shape[1]))
spect = torch.FloatTensor(spect)
# z-score 归一化
if normalize:
mean = spect.mean()
std = spect.std()
if std != 0:
spect.add_(-mean)
spect.div_(std)
return spect
# 音频加载器, 类似PyTorch的加载器,实现对数据的加载
class SpeechLoader(data.Dataset):
""" Google 音频命令数据集的数据形式如下:
root/one/xxx.wav
root/head/123.wav
参数:
root (string): 原始数据集路径
window_size: STFT的窗长大小,默认参数是 .02
window_stride: 用于STFT窗的帧移是 .01
window_type: , 窗的类型, 默认是 hamming窗
normalize: boolean, whether or not to normalize the spect to have zero mean and one std
max_len: 帧的最大长度
属性:
classes (list): 类别名的列表
class_to_idx (dict): 目标参数(class_name, class_index)(字典类型).
spects (list): 频谱参数(spects path, class_index) 的列表
STFT parameter: 窗长, 帧移, 窗的类型, 归一化
"""
def __init__(self, root, window_size=.02, window_stride=.01, window_type='hamming',
normalize=True, max_len=101):
classes, class_to_idx = find_classes(root)
spects = make_dataset(root, class_to_idx)
if len(spects) == 0: # 错误处理
raise (RuntimeError(
"Found 0 sound files in subfolders of: " + root + "Supported audio file extensions are: " + ",".join(
AUDIO_EXTENSIONS)))
self.root = root
self.spects = spects
self.classes = classes
self.class_to_idx = class_to_idx
self.loader = spect_loader
self.window_size = window_size
self.window_stride = window_stride
self.window_type = window_type
self.normalize = normalize
self.max_len = max_len
def __getitem__(self, index):
"""
Args:
index (int): 序列
Returns:
tuple (spect, target):返回(spec,target), 其中target 是类别的索引..
"""
path, target = self.spects[index]
spect = self.loader(path, self.window_size, self.window_stride, self.window_type, self.normalize, self.max_len)
return spect, target
def __len__(self):
return len(self.spects)
(3)定义模型
model.py的代码如下:
import torch.nn as nn
import torch.nn.functional as F
# 建立VGG卷积神经的模型层
def _make_layers(cfg):
layers = []
in_channels = 1
for x in cfg:
if x == 'M': # maxpool 池化层
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else: # 卷积层
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1, stride=1)] # avgPool 池化层
return nn.Sequential(*layers)
# 各个VGG模型的参数
cfg = {
'VGG11': [32, 'M', 64, 'M', 128, 128, 'M', 256, 256, 'M', 256, 256, 'M'],
'VGG13': [32, 32, 'M', 64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 256, 256, 'M'],
'VGG16': [32, 32, 'M', 64, 64, 'M', 128, 128, 128, 'M', 256, 256, 256, 'M', 256, 256, 256, 'M'],
'VGG19': [32, 32, 'M', 64, 64, 'M', 128, 128, 128, 128, 'M', 256, 256, 256, 256, 'M', 256, 256, 256, 256, 'M'],
}
# VGG卷积神经网络
class VGG(nn.Module):
def __init__(self, vgg_name):
super(VGG, self).__init__()
self.features = _make_layers(cfg[vgg_name]) # VGG的模型层
self.fc1 = nn.Linear(3840, 256) # 7680,512
self.fc2 = nn.Linear(256, 5) # 输出类别5,由于全量比较大,这里只选择前5个类别
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1) # flatting
out = self.fc1(out) # 线性层
out = self.fc2(out) # 线性层
return F.log_softmax(out, dim=1) # log_softmax 激活函数
(4)定义训练和评估
train.py的代码如下:
from __future__ import print_function
import torch
import torch.nn.functional as F
from torch.autograd import Variable
# 训练函数, 模型在train集上训练
def train(loader, model, optimizer, epoch, cuda):
model.train()
train_loss = 0
train_correct = 0
for batch_idx, (data, target) in enumerate(loader):
if cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
train_loss += loss
pred = output.data.max(1, keepdim=True)[1]
train_correct += pred.eq(target.data.view_as(pred)).cpu().sum()
train_loss = train_loss / len(loader.dataset)
print('train set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)'.format(
train_loss, train_correct, len(loader.dataset), 100.0 * float(train_correct) / len(loader.dataset)))
# 测试函数,用来测试valid集和test集
def test(loader, model, cuda, dataset):
model.eval()
test_loss = 0
correct = 0
for data, target in loader:
if cuda:
data, target = data.cuda(), target.cuda()
with torch.no_grad():
data, target = Variable(data), Variable(target)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum') # sum up batch loss
pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
test_loss /= len(loader.dataset)
print(dataset + ' set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)'.format(
test_loss, correct, len(loader.dataset), 100.0 * float(correct) / len(loader.dataset)))
(5)主函数
run.py的代码如下:
from __future__ import print_function
import argparse
import torch
import torch.optim as optim
from model import VGG
from speech_loader import SpeechLoader
from train import train, test
import time
def main():
# 参数设置
parser = argparse.ArgumentParser(description='Google Speech Commands Recognition')
parser.add_argument('--train_path', default='data/train', help='path to the train data folder')
parser.add_argument('--test_path', default='data/test', help='path to the test data folder')
parser.add_argument('--valid_path', default='data/valid', help='path to the valid data folder')
parser.add_argument('--batch_size', type=int, default=100, metavar='N', help='training and valid batch size')
parser.add_argument('--test_batch_size', type=int, default=100, metavar='N', help='batch size for testing')
parser.add_argument('--arc', default='VGG11', help='network architecture: VGG11, VGG13, VGG16, VGG19')
parser.add_argument('--epochs', type=int, default=20, metavar='N', help='number of epochs to train')
parser.add_argument('--lr', type=float, default=0.001, metavar='LR', help='learning rate')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M', help='SGD momentum, for SGD only')
parser.add_argument('--optimizer', default='adam', help='optimization method: sgd | adam')
parser.add_argument('--cuda', default=True, help='enable CUDA')
parser.add_argument('--seed', type=int, default=1, metavar='S', help='random seed')
# 特征提取参数设置
parser.add_argument('--window_size', default=.02, help='window size for the stft')
parser.add_argument('--window_stride', default=.01, help='window stride for the stft')
parser.add_argument('--window_type', default='hamming', help='window type for the stft')
parser.add_argument('--normalize', default=True, help='boolean, wheather or not to normalize the spect')
args = parser.parse_args()
# 确定是否使用CUDA
args.cuda = args.cuda and torch.cuda.is_available()
torch.manual_seed(args.seed) # PyTorch随机种子设置
if args.cuda:
torch.cuda.manual_seed(args.seed) # CUDA随机种子设置
# 加载数据, 训练集,验证集和测试集
train_dataset = SpeechLoader(args.train_path, window_size=args.window_size, window_stride=args.window_stride,
window_type=args.window_type, normalize=args.normalize)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, shuffle=True,
num_workers=1, pin_memory=args.cuda, sampler=None)
valid_dataset = SpeechLoader(args.valid_path, window_size=args.window_size, window_stride=args.window_stride,
window_type=args.window_type, normalize=args.normalize)
valid_loader = torch.utils.data.DataLoader(
valid_dataset, batch_size=args.batch_size, shuffle=None,
num_workers=1, pin_memory=args.cuda, sampler=None)
test_dataset = SpeechLoader(args.test_path, window_size=args.window_size, window_stride=args.window_stride,
window_type=args.window_type, normalize=args.normalize)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=args.test_batch_size, shuffle=None,
num_workers=1, pin_memory=args.cuda, sampler=None)
# 建立网络模型
model = VGG(args.arc)
if args.cuda:
print('Using CUDA with {0} GPUs'.format(torch.cuda.device_count()))
model = torch.nn.DataParallel(model).cuda()
# 定义优化器
if args.optimizer.lower() == 'adam':
optimizer = optim.Adam(model.parameters(), lr=args.lr)
elif args.optimizer.lower() == 'sgd':
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
else:
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
# train 和 valid过程
print("train and valid model...")
start = time.time()
for epoch in range(1, args.epochs + 1):
# 模型在train集上训练
start1 = time.time()
train(train_loader, model, optimizer, epoch, args.cuda)
# 验证集测试
test(valid_loader, model, args.cuda, 'valid')
end1 = time.time()
print("epoch: {%d / %d} done. time: {%d} s" % (epoch, args.epochs, end1 - start1))
end = time.time()
print("train and valid done. total time: {%d} s" % (end - start))
# 测试集验证
print("test model...")
start = time.time()
test(test_loader, model, args.cuda, 'test')
end = time.time()
print("test done. total time: {%d} s" % (end - start))
if __name__ == '__main__':
main()
运行结果如下:
C:\ProgramData\Anaconda3\python.exe E:/workspace/python/MachineLearning/SpeechRecognition/run.py
Using CUDA with 1 GPUs
train and valid model...
train set: Average loss: 0.0235, Accuracy: 1114/4000 (27.85%)
valid set: Average loss: 1.6100, Accuracy: 162/500 (32.40%)
epoch: {1 / 20} done. time: {17} s
train set: Average loss: 0.0141, Accuracy: 1573/4000 (39.33%)
valid set: Average loss: 1.2482, Accuracy: 228/500 (45.60%)
epoch: {2 / 20} done. time: {17} s
train set: Average loss: 0.0106, Accuracy: 2309/4000 (57.73%)
valid set: Average loss: 1.3798, Accuracy: 193/500 (38.60%)
epoch: {3 / 20} done. time: {16} s
train set: Average loss: 0.0049, Accuracy: 3283/4000 (82.08%)
valid set: Average loss: 0.9996, Accuracy: 359/500 (71.80%)
epoch: {4 / 20} done. time: {17} s
train set: Average loss: 0.0022, Accuracy: 3701/4000 (92.53%)
valid set: Average loss: 0.5315, Accuracy: 417/500 (83.40%)
epoch: {5 / 20} done. time: {17} s
train set: Average loss: 0.0018, Accuracy: 3746/4000 (93.65%)
valid set: Average loss: 0.3026, Accuracy: 457/500 (91.40%)
epoch: {6 / 20} done. time: {16} s
train set: Average loss: 0.0013, Accuracy: 3819/4000 (95.47%)
valid set: Average loss: 0.5664, Accuracy: 415/500 (83.00%)
epoch: {7 / 20} done. time: {16} s
train set: Average loss: 0.0010, Accuracy: 3864/4000 (96.60%)
valid set: Average loss: 0.3123, Accuracy: 445/500 (89.00%)
epoch: {8 / 20} done. time: {17} s
train set: Average loss: 0.0008, Accuracy: 3880/4000 (97.00%)
valid set: Average loss: 0.3881, Accuracy: 441/500 (88.20%)
epoch: {9 / 20} done. time: {17} s
train set: Average loss: 0.0007, Accuracy: 3900/4000 (97.50%)
valid set: Average loss: 0.4283, Accuracy: 443/500 (88.60%)
epoch: {10 / 20} done. time: {16} s
train set: Average loss: 0.0006, Accuracy: 3915/4000 (97.88%)
valid set: Average loss: 0.3375, Accuracy: 443/500 (88.60%)
epoch: {11 / 20} done. time: {16} s
train set: Average loss: 0.0004, Accuracy: 3940/4000 (98.50%)
valid set: Average loss: 0.1895, Accuracy: 472/500 (94.40%)
epoch: {12 / 20} done. time: {17} s
train set: Average loss: 0.0006, Accuracy: 3911/4000 (97.78%)
valid set: Average loss: 0.5093, Accuracy: 446/500 (89.20%)
epoch: {13 / 20} done. time: {17} s
train set: Average loss: 0.0006, Accuracy: 3913/4000 (97.83%)
valid set: Average loss: 0.4108, Accuracy: 435/500 (87.00%)
epoch: {14 / 20} done. time: {16} s
train set: Average loss: 0.0006, Accuracy: 3917/4000 (97.92%)
valid set: Average loss: 0.2042, Accuracy: 476/500 (95.20%)
epoch: {15 / 20} done. time: {16} s
train set: Average loss: 0.0004, Accuracy: 3950/4000 (98.75%)
valid set: Average loss: 0.3510, Accuracy: 466/500 (93.20%)
epoch: {16 / 20} done. time: {17} s
train set: Average loss: 0.0003, Accuracy: 3955/4000 (98.88%)
valid set: Average loss: 0.2502, Accuracy: 470/500 (94.00%)
epoch: {17 / 20} done. time: {17} s
train set: Average loss: 0.0002, Accuracy: 3977/4000 (99.42%)
valid set: Average loss: 0.2413, Accuracy: 474/500 (94.80%)
epoch: {18 / 20} done. time: {17} s
train set: Average loss: 0.0001, Accuracy: 3990/4000 (99.75%)
valid set: Average loss: 0.1650, Accuracy: 483/500 (96.60%)
epoch: {19 / 20} done. time: {16} s
train set: Average loss: 0.0001, Accuracy: 3986/4000 (99.65%)
valid set: Average loss: 0.1345, Accuracy: 482/500 (96.40%)
epoch: {20 / 20} done. time: {16} s
train and valid done. total time: {341} s
test model...
test set: Average loss: 0.3549, Accuracy: 472/500 (94.40%)
test done. total time: {3} s
从输出结果可以看出,我们的命令词语音识别模型的效果还是不错的,验证集和测试集的正确率都达到了94%以上。由于单机性能有限,这里只选择了前5个命令词,并且为了进一步减少数据手动删除了一些频谱,可能对结果有一定的影响。如果你的电脑能跑完整的数据,还是建议使用全量数据进行实验。