第二十七记·Java操作Kafka实战案例
XY个人记
首先要启动kafka的所有服务,本人配置了0-3 四个服务,启动命令如下:
$ bin/kafka-server-start.sh -daemon config/server1.properties
$ bin/kafka-server-start.sh -daemon config/server2.properties
$ bin/kafka-server-start.sh -daemon config/server2.properties
$ bin/kafka-server-start.sh -daemon config/server3.properties写一个生产者的Java代码 ProduceDemo 用于生产数据
package com.ijeffrey.producer;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import java.util.Properties;
import java.util.Random;
public class ProduceDemo {
public static void main(String[] args) {
final char[] chars = "qazwsxedcrfvtgbyhnujmikolp".toCharArray();
final int charLength = chars.length;
final String topic = "ijeffrey0";
//1. 创建Producer对象
//1.1 创建Properties对象
Properties props = new Properties();
//a. 给定kafka服务器的路径信息
props.put("metadata.broker.list","hadoop01.com:9092,hadoop01.com:9093,hadoop01.com:9094,hadoop01.com:9095");
//b. 指定producer需要等待broker返回数据成功接收标识。默认0,0表示不等待,1表示等待一个broker返回结果,-1表 示等待所有broker返回结果
props.put("request.required.acks","0");
//c. 给定数据发送方式,默认同步发送sync,可以选择异步async
props.put("producer.type","sync");
//d. 给定消息序列化为byte数组的方式,默认kafka.serializer.DefaultEncoder
props.put("serializer.class","kafka.serializer.StringEncoder");
//e. 给定数据分区器,决定数据发送到哪一个分区,默认kafka.producer.DefaultPartitioner,采用key的hash值进行分区
props.put("partitioner.class","kafka.producer.DefaultPartitioner");
// f. 使用自定义分区器
//props.put("partitioner.class","com.ijeffrey.producer.PartitionerDemo");
//1.2 创建ProducerConfig对象
ProducerConfig config = new ProducerConfig(props);
final Producer prodecer = new Producer(config);
// 2.以多线程的形式发送数据
// 这里所发送的是自己通过26个字母随机组合成单词,每个value 由 随机的1 - 10个单词组成,每个单词长度为 2 - 5 个
final Random random = new Random(System.currentTimeMillis());
for (int i = 0;i <3 ;i++){
new Thread(new Runnable() {
public void run() {
// 初始化一个发送消息的条数的值
int events = random.nextInt(1000) + 100;
String threadName = Thread.currentThread().getName();
for (int j = 0;j message = new KeyedMessage(topic,key,value);
// 发送
prodecer.send(message);
}
System.out.println("线程[" + threadName + "]已经发送完成了,共发送了" +events+ "条数据!!!!");
}
},"Thread-" + i).start();
}
Runtime.getRuntime().addShutdownHook(new Thread(
new Runnable() {
public void run() {
System.out.println("关闭producer........");
prodecer.close();
}
}
));
}
} 自定义Java分区器
package com.ijeffrey.producer;
import kafka.producer.Partitioner;
import kafka.utils.VerifiableProperties;
/**
* 自定义分区器
*/
public class PartitionerDemo implements Partitioner {
// 首先必须给定一个构造函数
public PartitionerDemo(VerifiableProperties properties){
// 必须给定,properties 里面放的是produce链接kafka的配置信息
}
// 此API返回值表示数据key发送到哪个分区,分区索引从0开始, numPartitions 表示要发送的topic的总的分区数
public int partition(Object key, int numPartitions) {
// 代表所有数据都发送到0分区
return 0;
}
}
然后后台启动一个消费者来消费topic ijeffrey0 的数据
$ bin/kafka-console-consumer.sh --topic ijeffrey0 --zookeeper hadoop01.com:2181/jfy_kafka执行Java代码可以看到消费者消费的数据
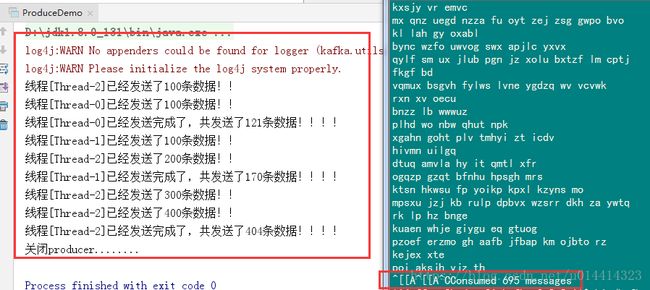
然后自定义一个消费者,ConsumerDemo,用于消费数据
package com.ijeffrey.consumer;
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.message.MessageAndMetadata;
import kafka.serializer.Decoder;
import kafka.serializer.StringDecoder;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
public class ConsumerDemo {
private ConsumerConnector connector = null;
private String topicName = null;
private int numThreads = 0;
public ConsumerDemo(String groupId, String zkUrl, boolean largest, String topicName, int numThreads) {
this.topicName = topicName;
this.numThreads = numThreads;
// 创建并给定consumer连接参数
Properties props = new Properties();
// a. 给定所属的consumer group id
props.put("group.id", groupId);
// b. 给定zk的连接位置信息
props.put("zookeeper.connect", zkUrl);
// c. 给定自动提交的间隔时间
props.put("auto.commit.interval.ms", "2000");
// d. 给定初始化consumer的时候使用offset偏移量值(只在第一次consumer启动消费数据的时候有效)
if (largest) {
props.put("auto.offset.reset", "largest");
} else {
props.put("auto.offset.reset", "smallest");
}
// 创建Consumer上下文对象
ConsumerConfig config = new ConsumerConfig(props);
// 创建Consumer连接对象
this.connector = Consumer.createJavaConsumerConnector(config);
}
public void run() {
// TODO: topicCountMap给定消费者消费的Topic名称以及消费该Topic需要使用多少个线程进行数据消费
// 一个消费者可以消费多个Topic
// topicCountMap以topic的名称为key,以线程数为value
Map topicCountMap = new HashMap();
topicCountMap.put(topicName, numThreads);
Decoder keyDecoder = new StringDecoder(null);
Decoder valueDecoder = new StringDecoder(null);
// 2. 根据参数创建一个数据读取流
// TODO: 该API返回的集合是一个以Topic名称为Key,以该Topic的数据读取流为集合的value的Map集合
// TODO: List> ===> 指的其实就是对应Topic消费的数据流,该List集合中的KafkaStream流的数目和给定的参数topicCountMap中对应topic的count数量一致;类似Consumer Group,一个线程/一个KafkaStream消费一个或者多个分区(>=0)的数据,一个分区的数据只被一个KafkaStream进行消费
Map>> consumerStreamsMap = connector.createMessageStreams(topicCountMap, keyDecoder, valueDecoder);
// 3. 获取对应topic的数据消费流
List> streams = consumerStreamsMap.get(topicName);
// 4. 数据消费
int k = 0;
for (final KafkaStream stream : streams) {
new Thread(new Runnable() {
public void run() {
int count = 0;
String threadNames = Thread.currentThread().getName();
ConsumerIterator iter = stream.iterator();
while (iter.hasNext()) {
// 获取数据
MessageAndMetadata messageAndMetadata = iter.next();
// 处理数据
StringBuilder sb = new StringBuilder();
sb.append("Topic名称=").append(messageAndMetadata.topic());
sb.append("; key=").append(messageAndMetadata.key());
sb.append("; value=").append(messageAndMetadata.message());
sb.append("; partition ID=").append(messageAndMetadata.partition());
sb.append("; offset=").append(messageAndMetadata.offset());
System.out.println(sb.toString());
count++;
}
System.out.println("线程" + threadNames + "总共消费" + count + "条数据!!");
}
}, "Thread-" + k++).start();
}
}
public void shutdown() {
if (this.connector != null) {
System.out.println("关闭consumer连接");
this.connector.shutdown();
}
}
public static void main(String[] args) throws InterruptedException {
String groupId = "jeffrey_0";
String zkUrl = "hadoop01.com:2181/jfy_kafka";
boolean largest = true;
String topicName = "ijeffrey0";
int numThreads = 10;
ConsumerDemo demo = new ConsumerDemo(groupId, zkUrl, largest, topicName, numThreads);
demo.run();
// 运行一段时间后进行关闭
Thread.sleep(10000000);
demo.shutdown();
}
}
我们可以启动多个消费者,然后用生产者生产数据,当断开一个消费者,其他消费者会继续消费数据,所以同一个组的offset不会同时消费数据,一个分区的数据只能被一个消费者消费。