Python实现基于BIC的语音对话分割(一)
1. 贝叶斯信息准则
在统计学里,处理模型选择问题时我们往往采用BIC进行判定,即贝叶斯信息准则。BIC是似然函数(likelihood function)加上一个惩罚项组成的,这个加上的惩罚项与模型拟合的参数有关,这样可以防止过拟合。
一般来说,贝叶斯信息准测的定义如下所示:
其中:
- L^ 是基于观测数据 x 拟合的模型 M 的似然函数的最大值, L^=p(x|θ^,M)
- x 是观测数据,即样本数据
- n 是观测数据的数量,也可以叫样本值
- k 是模型 M 的参数数量
一般来说,BIC值小的模型会被选择。
2. BIC实现语音分割
参考论文”Speaker, Environment and Channel Change Detection and Clustering via the Bayesian Information Criterion”
我们将语音信号的特征序列建模为独立多变量高斯过程:
其中: xi∈Rd,i=1,2,...N 。语音的特征我们一般来说选取MFCC,特征向量维数为 d ,特征的个数(样本数)为 N 。
假设有一段语音对话,在第i时刻有一个跳变点,那么寻找跳变点的问题就是对于下面两个假设模型进行选择的问题:
如果假设跳变点存在,那么对应的对数最大似然比为:
其中, Σ 是所有数据的协方差矩阵, Σ1 是 {x1...xi} 的协方差矩阵, Σ2 是 {xi+1...xN} 的协方差矩阵。符号 |Σ| 代表矩阵 Σ 的行列式。
额外的,我们对这个模型选择问题加入惩罚项,得到BIC值的计算:
其中:
惩罚项的权重 λ 一般取为1。
上式和第二节中的BIC定义式相比,有一个 −12 的权重,因为求解问题的目标从求解BIC值最小变为最大,即:
此外,还有一个前提就是: {maxiBIC(i)} >0,此时表示有两个独立的语音分段;若 {maxiBIC(i)} <0,此时表示只有一个独立的语音分段,没有分割点。
3. python中的语音处理package
在做语音分割之前,我们需要从语音信息中提取MFCC特征,有一个比较好用的Python库——librosa,它只一个专门做音频信号分析的库,里面提供了MFCC的计算接口。
mfccs = librosa.feature.mfcc(y, sr, n_mfcc=12, hop_length=frmae_shift, n_fft=frame_size)其中n_fft为enframe的帧长度(采样点),hop_length为帧移的长度,n_mfcc为特征的维数。
有关librosa的安装指导请看官方的github地址:
https://github.com/librosa/librosa
推荐采用Anaconda的方式安装。
conda install -c conda-forge librosa4. 代码实现
在测试过程中,选取的音频文件为采样率16KHz,16bit量化的wav音频,该音频中只有两端对话,是一个很简单的测试音频。部分代码如下:
4.1 音频读取与MFCC计算
y, sr = librosa.load("test3.wav", sr=16000)
frame_size = 256
frmae_shift = 128
mfccs = librosa.feature.mfcc(y, sr, n_mfcc=12, hop_length=frmae_shift, n_fft=frame_size)4.2 BIC计算
conv_all = np.cov(mfccs)
log_lh_all = np.log(np.linalg.det(conv_all))
#
part1 = mfccs[:,0:index]
part2 = mfccs[:,index:n]
conv_1 = np.cov(part1)
conv_2 = np.cov(part2)
log_lh_first = np.log(np.linalg.det(conv_1))
log_lh_second = np.log(np.linalg.det(conv_2))
BIC = n*log_lh_all-index*log_lh_first-(n-index)*log_lh_second-0.5*(m+0.5*m*(m+1))*np.log(n)4.3 测试结果
原始的分割点查看,用cooledit打开音频文件:
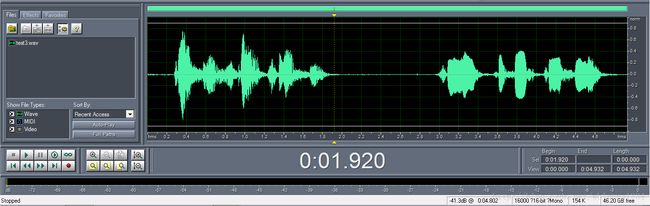
程序的运行结果:
分割点所在的位置是: 1.92 秒还是比较准确,接下来会找一个比较复杂的多分割点的对话来进行测试,敬请期待!