关于I/O操作
https://blog.csdn.net/deram_boy/article/details/51191425
提及这个,就想到了各种文件操作,这种流,什么reader 啊, writer啊,buffer啊,file啊。但是综合的东西与总结,只是曾经了解。因为工作中也没有太做这方面的东西。逐渐被忘记了。但是找工作要会这些呀。这些也不难。下面总结下吧!
首先了解文件操作:
文件,也就是file是最常见的数据源之一,在程序中经常要把数据存储到一个文件中,比如将图片文件,声音文件等数据文件,也就是需要根据执行的文件中进行数据的读和取。当然,在实际情况下,每一个文件都含有一个唯一的格式,这个格式需要程序员根据需求进行设计,读取已有的文件时也应当熟悉其对应的格式,才能把数据从文件中正确的读取下来。
文件的存储介质有很多,比如光盘,硬盘,U盘,外置硬盘等等。由于IO类在设计之初,已经实现了从数据源变为流对象这个过程,所以存储介质对于程序员来说就相当于一个黑盒,不用管了,也不用自己实现,我们只需要关注如下图的I/O操作体系:
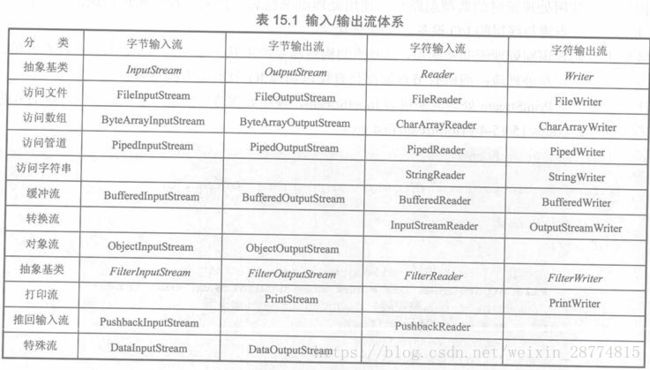
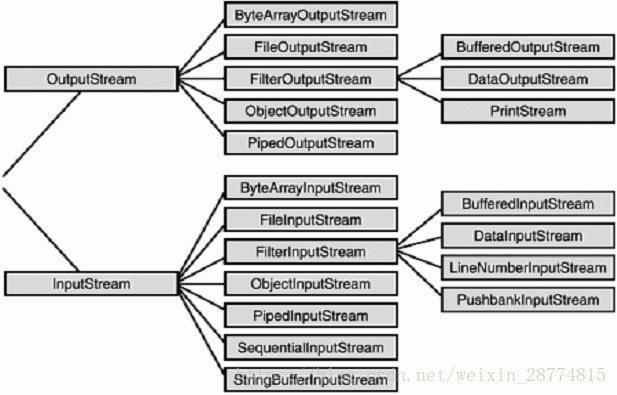
I/O操作主要指的是使用java进行输入,输出操作。Java所有的I/O机制都是基于数据流进行输入输出,这些数据流标识了字符或者字节的流动序列。Java.io是面向数据流的输入输出的主要软件包。此外java也对块传输提供支持,在核心库Java.nio 中采用的便是块IO. 流IO的好处是简单易用,缺点是效率比较低。块IO的效率很高,但是编程上稍微复杂。Java.io 包中包含了流式I/O所需要的所有类。其中有四个基类:inputStream, outPutStream, Reader, Writer。Java的IO模型设计的特别优秀,他使用了Decoretor模式,按功能划分为 Stream, 可以动态装配这些Stream,以便于获得我们所需要的功能,例如,我们需要一个具有缓冲的文件输入流,则应当使用FileInputStream 和 BufferedInputStream的组合来进行。
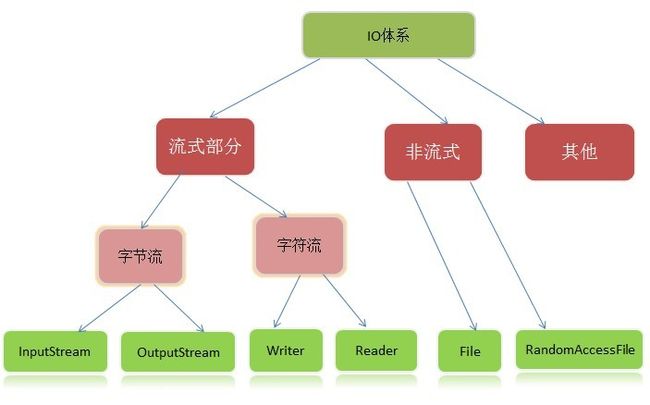
IO流的四个基本类: InputStream, OutputStream, Reader, Writer类。他们分别用于处理字节流和字符流。
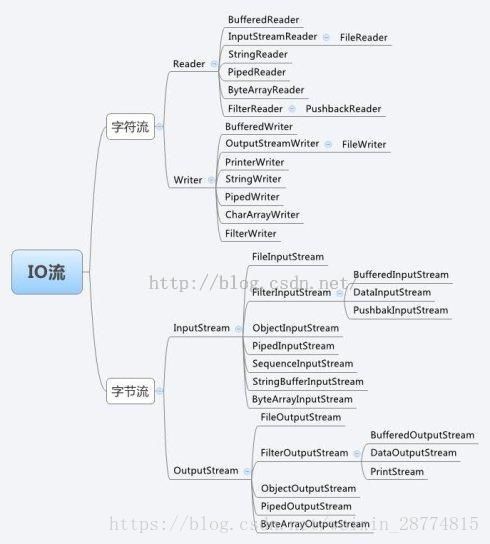
刚刚说的东西基本可以看出,java有字节流和字符流的区分。那么我们来简单的了解一下字节流和字符流。
https://blog.csdn.net/lwang_it/article/details/78886186
字节流和字符流在使用上非常相近,两者除了操作代码上有稍微不同之外还有什么不同呢?实际上字节流在操作上本身不会用到缓冲区,是文件本身直接操作的。但是字符流在操作时是要用到缓冲区的,通过缓冲区来操作文件。
举个栗子:
1 把流的关闭操作注释掉!!!!!!。看看字节流与字符流之间的变化
1字节流
public static void main(String[] karg)throws Exception {
File f = new File("d:" + File.separator + "test.txt");
OutputStream out = new FileOutputStream(f);
String string = "Hello World!";
byte[] b = string.getBytes();
out.write(b);
// out.close();
}执行,打开文件后发现文件写上了这几个字
2 字符流
public void testWriter(){
File f = new File("d:" + File.separator + "test.txt");
Writer writer = new FileWriter(f);
String string = "Hello World";
Byte[] bytes = string.getBytes();
writer.write(bytes);
// writer.close();
}
}执行代码,发现对应的文件并没有写上这几个字。因为字符流在操作的时候使用了缓冲区,而在关闭字符流的几时候会强制的将缓冲区中的内容进行输出,但是如果程序没有0关闭的话,则缓冲区的内容是没有办法输出出去的。所以得出结论,字符流使用了缓冲区,而字节流没有使用缓冲区是直接操作文件的。
那么又来了一个问题:什么是缓冲区啊???
缓冲区可以简单的一段内存区域。可以简单的把它理解为一段特殊的内存。某些情况下,如果一个程序频繁的操作一个资源,比如文件或者数据库,则性能可能会很低,此时为了提升性能,就可以将一部分数据暂时存到内存的一个区域里面,以后直接从这个区域读取数据即可。因为读取内存的速度是比较快的这样可以特生程序的性能。在字符流流的操作中,所有的字符都是内存中形成的,在输出前会将内容暂时保存在内存之中,所以使用了缓冲区暂存数据。如果想要在不关闭时可以将字符流的内容全部输出的话,可以调用writer的flush方法来完成。
那么在实际开发中我们是使用字符流好还是字节流比较好呢?已知字符流是有缓冲的,字节流是直接写进去的。
答案是字节流。所有的文件在硬盘或者传输时都是以字节的方式进行的,包括图片等都是按照字节的方式来存储的,而字符只是在内存中才会形成,在开发中,字节流的使用较为广泛。那么我又有问题了,字符和字节具体有什么区别?简单说一下,ASCLL码这个应该很清楚吧,那里的每一个内容都是一个字符,ASCALL码没记错的话,每个字符占8位吧好像。那要是Unicode编码的话,咱们的汉字要占两个字节呢!而字节呢,人家的单位是Byte,01010101这总明白吧,好吧每八位一个字节。我不管你内容是啥,我就按byte单位传!这俩的区别就是这么明显!
好,接下来我们看看Java中的流分类,java中的字节流,祖宗是 inputStream,outputStream, java中的字符流是 writer和reader。 并且这样分是有一定的历史渊源的。 字节流是最基本的,从上面讲的东西来说,已经可以很简单的推测出来。字节流的代表类是 inputStream, 和 OutputStream。他们主要用来处理二进制数据,他是按照字节流来处理的,但是实际中很多的数据就是简单的纯文本,这些文本都有一个特定的编码,无论是写入和读取都要保证编码的对应,才能解决常见的乱码问题,于是,又提出了字符流这个概念,他是按照虚拟机的encoder来处理,也就是要进行字符集的转化,在写入和读取的时候指定对应的(唯一的)编码,就能转化为正确的字符。这两个通过InputStreamReader 和 OutputStreamWriter来关联,实际上是 byte和string之间的关联。在开发工作中遇到的汉字乱码问题实际上是字符流和字节流之间转化不统一。
有一个byte转化为string的方法
public string(byte bytes[], String charesName),这里面有个很关键的参数,代表了编码集,
至于java.io包中的其他流,说白了主要是为了提高性能和使用户方便而搞出来的
好,接下来继续讲IO一些大方面架构上的。
一. Java.io的开始, 文件
File f = new File("e:\\file");
if (f.isDirectory()) {
System.out.printlin(f.getPath());
}删除文件
f.delete();获取子目录:
if(f.isDirectory()) {
File[] subs = dir.listFiles();
for (File sub : subs){
String name = sub.getName;
long length = sub.length();
}
}FileFilter类:就是自己写一个继承自这个借口的类,实现他的accept方法,这个方法的返回值是布尔类型的。然后直接调用file类的 listFiles方法,那个带fileFile的参数的,把你刚才写的那个塞进去就行。
创建多级目录下的一个文件。
public void testWriter(){
File f = new File("d:" + File.separator + "test.txt");
Writer writer = new FileWriter(f);
String string = "Hello World";
Byte[] bytes = string.getBytes();
writer.write(bytes);
// writer.close();
}
} public static void main(String[] karg)throws Exception {
File f = new File("d:" + File.separator + "test.txt");
OutputStream out = new FileOutputStream(f);
String string = "Hello World!";
byte[] b = string.getBytes();
out.write(b);
// out.close();
} public static void main(String[] karg)throws Exception {
File f = new File("d:" + File.separator + "test.txt");
OutputStream out = new FileOutputStream(f);
String string = "Hello World!";
byte[] b = string.getBytes();
out.write(b);
// out.close();
}import java.io.File;
import java.io.IOException;
/**
* 创建多级目录下的一个文件
* @author Administrator
*
*/
public class FileDemo3 {
public static void main(String[] args) throws IOException{
File file = new File(
"a"+File.separator+
"b"+File.separator+
"c"+File.separator+
"d"+File.separator+
"e"+File.separator+
"f"+File.separator+
"g"+File.separator+
"h.txt"
);
/*
* 创建文件时,应首先判断当前文件所在的
* 目录是否存在,因为若不存在,会抛出
* 异常的。
*/
/*
* File getParentFile()
* 获取当前文件或目录所在的父目录
*/
File parent = file.getParentFile();
if(!parent.exists()){
parent.mkdirs();
}
if(!file.exists()){
file.createNewFile();
System.out.println("文件创建完毕");
}
}
}RandomAccessFile 用于读写文件数据的类
看原文吧,太多不想写了
RandomAccessFile用于读写文件数据的类
RandomAccessFile raf = new RandomAccessFile("demo.dat", "rw");
int num = 97;
raf.write(num);
raf.close();RandomAccessFile raf = new RandomAccessFile("demo.adt", "rw");
raf.read();
raf.close();使用RandomAccessFile 完成复制操作
RandomAccessFile res = new RandomAccessFile("src.jpg", "r");
RandomAccessFile des = new RandomAccessFile("copy.jpg", "rw");
int d = -1;
while(d = res.read() != -1) {
des.write(d);
}
res.close();
des.close();使用RandomAccessFile批量写出一组字节:
RandomAccessFile raf = new RandomAccessFile("test.mp4", "rw");
String s = "我爱你中国!";
Byte [] bs = s.getBytes("gbk");
raf.write(bs);
raf.close();使用RandomAccessFile读取一个字节数组的数据。RandomAccessFile raf = new RandomAccessFile("read.mp4", "r");
Byte[] bytes = new Byte[50];
StringBuilder sb = new StringBuilder();
while(raf.read(bytes) != -1) {
sb.append(new String (bytes, "gbk"))//这句我编的不太好,总是new 会出问题
}
System.out.println(sb.toString());
raf.close();
使用RandomAccessFile 基于缓存的方式复制文件
简单的转化一下上面的用法就可以写出来了。就是读写都运用了一个 bytes数组。 最后不要忘记关流。算了还是写一下吧
RandomAccessFile res = new RandomAccessFile("res.avm", "r");
RandomAccessFile des = new RandomAccessFile("copy.avm", "rw");
Byte[] buffer = new Byte[60];
while(res.read(buffer) != -1) { //这里read方法的意思是,读出来并且给buffer赋值内容
des.write(buffer);
}
res.close();
des.close();使用RandomAccessFile 读取和写入基本类型数据。
RamdomAccessFile file = new RandomAccessFile(“test.mp4”, "rw");
file.writeInt(100);
file.writeDouble(200.0);
file.writeLong(200000000000000);
file.close();
RandomAccessFile reader = new RandomAccessFile("test.mp4", "r");
int inti = reader.readInt();
double d = reader.readDouble();
long l = reader.readLong();查看RandomAccessFile的指针位置
RandomAccessFile raf = new RandomAccessFile("raf.dat", "rw");
long point = raf.getFilePointer();//获取当前文件的指针位置 =0
raf.write(97);
point = raf.getFilePointer(); // = 1;
raf.writeInt(1);
point = raf.getFilePointer();// = 5 因为int类型的占四个字节空间
raf.seek(0);//。将指针移动到最开始的位置
point = raf.getfilePointer(); // = 0
raf.read(); //读取一个字节
point = raf.getFilePointer(); // = 1; 因为上次读取的时候,往后移动了一个字节字节流 InputStream, OutputStream
1 InputStream 抽象类,,抽象类抽象类!
InputStream作为字节输入流,他本是就是一个抽象类,必须靠其子类去实现各种功能,此抽象类是表示所有字节输入流的超类,所有继承自InputStream的流都是向程序中写入数据的,且数据单位是byte ,也就是8位 8bit
InputStream 是输入字节,也就是read数据的时候用到的类,所以 InputStream提供了3种重载的read 方法。InputStream中常用的方法有:
public abstract int read();
public abstract int read(byte[] b);
public abstract int read(bute[] b, int off, int len); //从输入流中最多读取len个字节的数据,存放到偏移量为off的b数组中。
public int avaliable();返回输入流中可以读取的字节数,注意如果输入阻塞了,当前线程将被挂起,如果inputStream对象调用这个方法的话,他只会返回0,因为此时读不了读不了挂起了就是不能读,没毛病!这个方法只有继承自inputStream的子类调用才会有用。
public long skip(long n) , skip中文翻译是跳跃的意思。方法名字将的明明白白的,忽略输入流中n个字节,返回值是实际忽略的字节数,跳过一些字节来读取。
public int close() 用完之后一定要关流!!!!关闭输入流并且释放这些流占用的系统资源。下面附上一张inputStream的族谱:
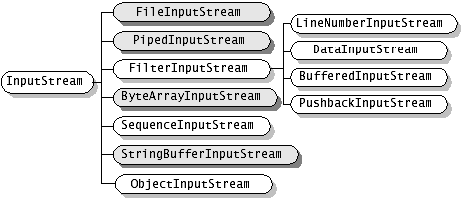
无论多么五花八门,反正你要彻彻底底记住的是他们的超类的那几个方法。
FileInputStream: 把一个文件放到inputStream中实现对文件的读写。
PipedInputStream: 实现了Piple的概念。主要在线程中使用。
FilterInputStream:
ByteArrayInputStream: 把内存中的一个缓冲区作为InputStream使用
SequenceInputStream: 把多个InputStream合并为一个InputStream
StringBufferInputStream: 把一个String对象当做一个inputStream
ObjectInputStream:
流结束的判断方式 read()返回-1 或者是readLine()返回null
2 OutputStream抽象类
感觉与InputStream基本是个对称的关系。 比如他的write方法,也提供了三个可以重载的。
public void write(byte[] b)
public void write(byte[]b, int off, int len)将参数b从偏移量off开始的len个字节处写出。
public void write(int b), 先将int转换为byte类型,把低字节写入到输出流里面。
public void flush() 将数据缓冲区中的数据全部写出, 并清空缓冲区。
public void close() 关闭输出流并释放与流相关的系统资源。
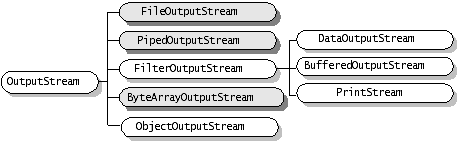
各类的理解按照上面那个来,一对一的不多说了。
3 文件输入流,FileInputStream类
FileInputStream可以使用一个read方法一次读入一个字节,并且返回一个数字,或者是使用read方法读入一个byte数组,byte数组的元素有多少个就有多少个字节,在将整个文件读取完或者写入的过程中这个byte数组可以当成一个缓冲区,因为这样的话一个byte数组旺旺担任的是承接数据的中间角色。
使用方法1 File file1 = new File("d:/abc.txt");
FileInputStream ins = new FileInputStream(file1);
2 FileInputStream ins1 = new FileInputStream("d:/abc.txt");那么关于FileInputStream的用法,基本就和RandomAccessFile 这个类差不多了。把byte【】当缓冲
FileInputStream ins = new FileInputStream("test.txt");
Byte[] buffer = new Byte[80];
StringBuilder sb new StringBuilder();
while(ins.read(buffer) != -1) {
sb.append(new String(buffer, "utf-8"));
}
ins.close();
System.out.println(sb);4 FilleOutStream 差不多的用法。
5 FileInputStream 和 FileOutputStream 的用法,复制文件!自己想想怎么写,反正前面的有了,这个大同小异。
6 缓冲输入输出流 BufferedInputStream , BufferedOutStream
先上图。事实上我从不感觉一张图能够表达的有多直白,反而看不懂。
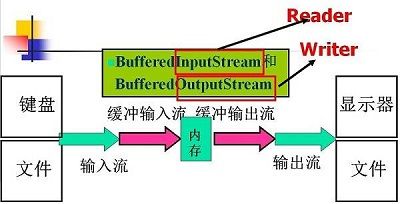
计算机访问外部设备的时候,是非常耗时的。并且对外访问的频率越高,造成CPU的闲置率就越大。为了减少访问外存的次数,应该在一次对外的访问中,读写更多的数据。为此,除了程序和流节点交换数据必须的读写机制外,应当增加缓存机制。缓冲流实则是对数据流分配一个缓冲区,一个缓冲区就是一个临时存储这段数据的内存。这样可以减少访问外部设备的次数,提高传输率。
BufferdInputStream当向缓冲流写入数据的时候,系统会先写到缓冲区,待到缓冲区的数据满了之后,系统就会一次性将数据发送到设备上。
BufferedOutputStream,当向缓冲流读数据的时候,系统先从缓冲流里找,当缓冲流是空的时候,系统再输入设备读数据到缓冲区。
这两个类的作用吧,其实就相当于M416上一个快速扩容弹夹的作用吧,吃鸡的都懂得。不晓得比喻的恰当不恰当,也就是枪没有这个照样可以发出子弹,但是有了这个更方便,减少了我亲换子弹的次数。并且更贴切的一个特点是,这丫真的就跟扩容弹夹一个德行,就是可拆卸,一个部件,想加就加上。看看代码就可以很清楚的感受到了。
FileOutputStream fw = new FileOutputStream("text.txt");
BufferdOutPutStream bos = new BufferedOutputStream(fw);//看吧,,这不就是相当于扩容弹夹被装上时的样子吗哈哈哈
String str = "我爱北京天安门,天安门上太阳升!";
bos.write(str.getBytes("UTF-8"));
bos.flush();
bos.close(); //关掉最外面的那个就行了。BufferedInputStream 与 BufferedOutpurStream 组合使用来加速文件的复制。
也就是那一套,自己想去吧。你那么聪明。别忘了关流就行。
7 字符流 Writer/Reader
有了字节流为毛还要整一个字符流。原因前面已经提到了。有的文件,人家就是纯文本。有的一个字符占16位也就是两个字节,在某些编码中汉字甚至占到3个字节。于是就有了字符流这个东西。
7.1 Reder抽象类 原文太长了,实在不想写了啊啊啊,坚持一下吧。
Reader是一个读取字符流的抽象类,子类必须实现其read(char【】, int, int)和 close() 方法。但是大部分子类将重写此处定义的一些方法,以提供更高的效率和功能。 下面晒一下它的族谱。,,,
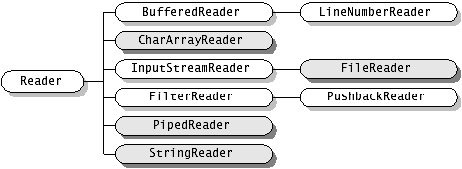
哈哈,似曾相识对不对?和 InputStream神相似对不对?在我看来就是大猩猩和人之间的距离,基因百分之70相似呵呵了。。。同时它的子类或者实现类,其实与InputStream的子类有对应之处。
1 FileReader 与 FileInputStream相对应
主要是用来读取字符文件,使用缺省的字符编码,有三种构造函数
1
File f = new File("c:/temp.txt");
FileReader reder = new FileReader(f);
2
FileReader reder = new FileReader(c:/temp.txt);
3
FileDescriptor fd = new FileDescriptor();
FileReder f2 = new FileReader(fd);2 CharArrayReader 与 ByteArrayInputStream 相互对应
StringReader 与 StringBufferInputStream 对应
InputStreamReader 从输入字节流读取字节并将其转化为字符。 Public inputStreamReder(inputStream ins);
FilterReader 允许过滤字符流, protected filterReader(Reader r);
BufferReader: 接受reader作为参数,并对其添加字符缓冲器,使用readLine()可以读取一行,public BufferReader(Reader r);
7.2 Writer抽象类
写入字符流的抽象类,子类必须实现的方法仅有 write(char[], int. int), flush(), 和 close()。但是多数子类将重写此处定义的一些方法,以提高效率或者其他功能。其族谱如下:
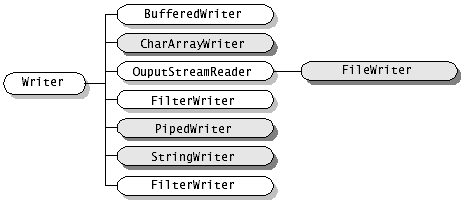
InputStream 与 Reader 的差别, OutputStream与Writer的差别。
先不着急看答案,我先来总结下,最明显的是一个是针对字节,一个是针对字符,然后就是字符的那一波带有缓冲机制。回答完毕!
看看原文给的其他答案哈
InputStream, OutputStream处理的是字节流,数据流中最小的单位就是字节(8 bit)。而Reader 与 Writer处理的是字符流,并且在处理字符流的时候涉及了字符编码的问题。这个答案着重编码方面的问题。下面上代码:
public static void main(String[] args) throws IOException{
String s = "你好!";
readBuffer(s.getBytes(s, "gbk"));
readbuffer (s.getBytes(s, "utf-8"));
}
private static void readBuffer(Byte[] bs)throws IOException{
BytyArrayInputStream bais = new ByteArrayInputStream(bs);
int data = -1;
while (data = bais.read() != -1) {
System.out.println(data + "");
}
bais.close();
} //感觉这个例子不是很贴切呀,这明明就是字节流的操作,哪儿来的字符流的各种编码问题???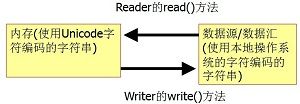
下面介绍下 BufferdReader 与 InputStreamReader 相结合的用法。这个和 BufferedInputStream 相对于 FileInputStream的用法一样,也就是一把M416加上一个扩容弹夹的道理。
//首先整到文件
FileInputStream fis = new FileInputStream("osw.txt");
//然后用 InputStreamReader来读
InputStreamReader isr = new InputStreamReader(fis, "utf-8"); //看吧,有编码,假设文件的编码就是utf-8 此时你如果不指定或者是其他的编码,出来的每个char八成都是乱了码的!
int d = -1;
while(d = fis.read() !=-1) {
char c = d;
System.out.println(c);
}
fis.close();然后咱们看看 InputStreamReader 与 BufferedRead相结合,快速的读取纯文本文件
FileInputStream fis = new FileInputStream("temp.txt");
InputStreamReader isr = new InputStreamReader(fis, "utf-8");
BufferedReader br = new BufferdReader(isr);
String s = null;
while(s = br.readLine() != null) {
System.out.println(s);
}
br.close(); //不要忘了关掉最外层的。