大数据时代,TB级甚至PB级数据已经超过单机尺度的数据处理,分布式处理系统应运而生。
知识预热
- 「专治不明觉厉」之“大数据”;
- 大数据生态圈及其技术栈;
关于大数据的四大特征(4V)
- 海量的数据规模(Volume):Quantifiable(可量化)
- 高速的数据流转和动态的数据体系(Velocity):Measurable(可衡量)
- 多样的数据类型(Variety):Comparable(可对比)
- 巨大的数据价值(Value):Evaluable(可评估)
关于大数据应用场景:
- 数据挖掘
- 智能推荐
- 大数据风控
推荐目前三大应用最广泛、国人认知最多的Apache开源大数据框架系统:Hadoop,Spark和Storm。
Storm - 主要用于实时大数据分析,Spark - 主要用于“实时”(准实时)大数据分析,Hadoop - 主要用于离线大数据分析。
本文以 Hadoop 和 Spark 为主,Storm 仅作简单介绍。
历史发展小知识
2003年到2004年间,Google发表 MapReduce、GFS(Google File System)和 BigTable 三篇技术论文,提出一套全新的分布式计算理论,成为大数据时代的技术核心。
江湖传说永流传:谷歌技术有"三宝":
MapReduce:分布式计算框架,==> Hadoop MapReduce,并行计算的编程模型
GFS:分布式文件系统,==> HDFS,为上层提供高效的非结构化数据存储服务(一个master(元数据服务器),多个chunkserver(数据服务器))
BigTable:基于 GFS 的数据存储系统,==> HBase,提供结构化数据服务的分布式数据库(键值映射,稀疏、分布式、持久化、多维排序映射)
Hadoop
Hadoop是一个生态系统(分布式存储-运算集群),开发和运行处理大规模数据或超大数据集(Large Data Set)的软件平台,是Apache的一个用Java语言实现的开源软件框架,实现在大量计算机集群中对海量数据进行分布式计算。

关于官网对 Hadoop 的介绍:
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
Hadoop框架中最核心设计:(排序是Hadoop的灵魂)
- HDFS:(底层数据层),海量数据存储,磁盘存储;
- MapReduce:(上层运算层)数据批量计算;
HDFS
Hadoop Distributed File System,Hadoop分布式文件存储和管理系统,是数据管理和存储功能的一种辅助工具。每个文件被分成固定大小的块(默认64MB),块作为最小的存储单位放到众多服务器上(按键值对将块存储在HDFS上,并将键值对的映射存在内存中),文件的每个块都有备份(默认3份)。
关于副本存放策略
HDFS的存放策略是将一个副本存放在本地机架节点上,另外两个副本放在不同机架的不同节点上。
- 每个DN最多存储一个副本
- 每个机架最多存储两个副本
关于容错机制
Hadoop Master采用 Log + CheckPoint 技术实现故障恢复,同时采用 Secondary Master 辅助之:
- Log:记录元数据的每一次变化,相当于连续数据保护
- CheckPoint:冗余数据备份,相当于一次全量备份
Master宕机后,先恢复到checkpoint,然后根据log恢复到最新状态。每次创建一个新的checkpoint,log即可清空,有效控制log文件大小。
关于 Moving computation is cheaper than moving data
- 逻辑分发,而不是数据分发;
- 计算逻辑分发到数据侧,在数据侧分布式处理,而不是集中式处理;
优点
- 主从 Master-Slaver 模式,元数据和数据分离,负载均衡
- Cheap and Deep:适合部署在普通低廉的(low-cost)机器硬件上 and 水平扩展
- Scale "out",not "up":向"外"横向扩展,而非向"上"纵向扩展
- 高度容错处理、高吞吐量的数据访问
- 流式数据访问,一次写入、多次读取(Write Once Read Many,WORM)
- 为应用开发者隐藏系统层细节:Focus on what to compute,neglect how to compute
局限性
- 抽象层次低,API 支持少;
- 重吞吐量,轻时延:交互式数据处理和实时数据处理较弱;
- 迭代式数据处理性能比较差;
HDFS通信有 Client 和 NameNode + DataNode 两部分。NameNode 获取元数据,定位到具体的 DataNode,DataNode 读取相应的文件数据。Client和NameNode 以及 NameNode和DataNode 基于TCP/IP通信,远程过程调用(RPC)模型封装 ClientProtocol协议 和 DatanodeProtocol协议,Client和NameNode通过ClientProtocol协议交互,NameNode和DataNode通过DatanodeProtocol协议交互。
Master中的Task queue,存储待执行的任务,每一个Slaver有若干Task slots,用来接收Master分配来的任务并执行。
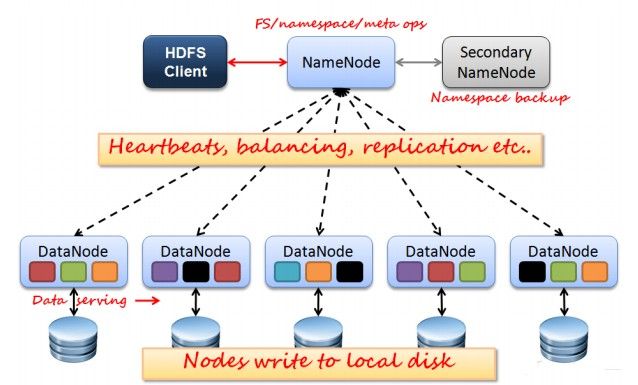
- Client:与NN交互获取文件元数据;与DN交互进行数据读写
- NameNode:Master Node,管理节点(元数据节点),管理数据块映射(目录和文件与Block的对应关系、Block与DataNode的对应关系);处理客户端的读写请求;配置副本策略;管理HDFS名称空间(维护文件系统的名字空间和文件属性);所有元数据都保存在内存中, 内存中存储的是 = fsimage + edits;存储文件系统运行的状态信息
- DataNode:Slaver Node,数据节点,存储Client发送的数据块;执行数据块的读写操作;执行副本策略;容错机制
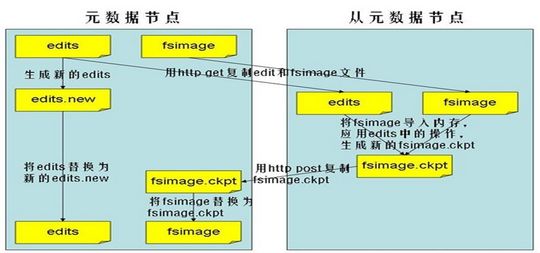
- fsimage:元数据镜像文件(文件系统的目录树)
- fsedits:元数据操作日志文件(针对文件系统所做的修改操作记录)
- JobTracker:in NameNode 中,当有任务提交到Hadoop集群时,负责Job的运行和多个TaskTrackers的调度
- TaskTracker:in DataNode 中,负责某一个Map或者Reduce任务
其中,fsimage和fsedits保存在硬盘上,映射关系不保存在硬盘上、而是在系统启动的时候从数据节点收集而成的。Secondary NameNode是NameNode的冷备份,分担NameNode的工作量(默认每隔1小时,从NameNode获取fsimage和edits来进行合并,然后再发送给NameNode)。关于冷备份和热备份,扼要说明:
- 冷备份:b 是 a 的冷备份,如果 a 坏掉,b 不能马上代替 a 工作。但 b 上存储会 a 的一些信息,减少 a 坏掉之后的损失
- 热备份:b 是 a 的热备份,如果 a 坏掉,b 马上运行代替 a 的工作
注意,NameNode节点只有1个,难以支持高效存储大量小文件。作为HDFS的神经中枢,存在单点故障(SPOF),可能导致数据丢失。
采用 HA(High Available)机制 冗余备份解决:
- Secondary NameNode:元数据备份方案
- AvatarNode:能够使HDFS以最短时间完成故障切换
亦可以通过ZooKeeper实现主从结构避免单点故障。
HDFS文件读写流程:
执行读或写过程,支持Staging(分段传输),NameNode与DataNode通过 HeartBeat(TaskTracker周期给JobTracker发送心跳,把TaskTracker的运行状态和map任务的执行情况发送给JobTracker)保持通信。
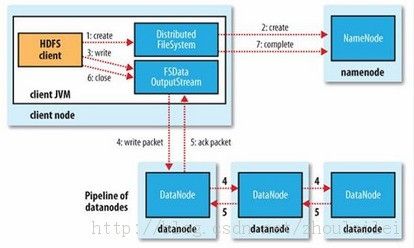
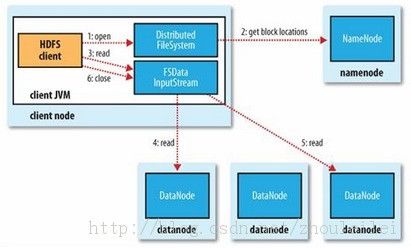
(1)文件读取
- Client向NameNode发起读文件请求
- NameNode把该文件的DataNode信息返回给Client
- Client从DataNode总读取信息
(2)文件写入
- Client向NameNode发起写文件请求
- NameNode根据文件大小和文件块配置情况,把它管理的DataNode信息返回给Client
- Client将文件划分为多个文件块,并根据DataNode的地址信息,按顺序把Block按顺序写入到DataNode中
一个文件经过创建、写入和关闭之后就不需要也不能再改变,解决数据一致性问题。
具体流程图参见:HDFS 工作原理;进一步的详细了解,请参见:HDFS 初探 - 读写数据流;
推荐参考:【漫画解读】HDFS存储原理;
MapReduce
第一代计算引擎,Hadoop分布式计算的关键技术,Job Scheduling/Executing System,简单编程模型(大规模数据集的并行计算)、磁盘读写、暴力但笨重。
核心思想:分而治之 ---> "拆分 + 合并",但是拆分要均匀(Shuffle)
数据处理流程中的每一步都需要一个Map阶段和一个Reduce阶段,即一个Job只有Map和Reduce两个阶段,每个阶段都是用键值对(key/value)作为输入和输出
Map:映射,对集合里的每个目标应用同一个操作,Mapper
Reduce:化整为零、大事化小,遍历集合中的元素来返回一个综合的结果,Reducer
关于网上用最简短的语言解释 MapReduce:
We want to count all the books in the library. You count up shelf #1, I count up shelf #2. That’s map. The more people we get, the faster it goes. Now we get together and add our individual counts. That’s reduce.
再通俗点,可以理解为,把一堆杂乱无章的数据按照某种特征归纳,然后处理并得到最后结果。Map阶段面对的是杂乱无章的互不相关的数据,它解析每个数据,从中提取key和value,也就是提取数据的特征。经过MapReduce的Shuffle阶段后,Reduce阶段看到的都是已经归纳好的数据,在此基础上可以做进一步的处理以便得到结果。
首先了解下 InputSplit 的基本概念:
- 分片,概念来源于文件,一个文件可以切分成多个片段
- Hadoop定义的用来传送给每个单独map的数据,InputSplit存储的并非数据本身,而是一个分片长度和一个记录数据位置的数组
- Map task 的最小输入单位
- 一个分片不会跨越两个文件,一个空的文件占用一个分片
- 分片不一定等长,一个分片可以跨一个大文件中连续的多个Block,通常分片大小就是BlockSize
关于MapReduce的大概处理流程:任务的分解与结果的汇总
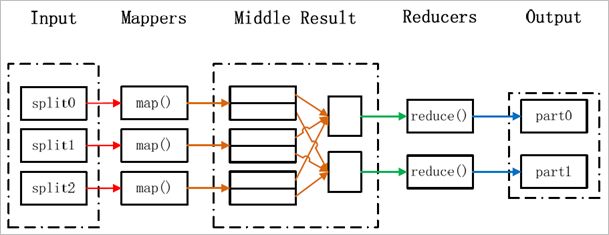
其中,Map过程需要继承org.apache.hadoop.mapreduce包中的Mapper类并重写map方法,Reduce过程需要继承org.apache.hadoop.mapreduce包中的Reducer类并重写reduce方法。map函数接受一个
关于MapReduce的详细处理流程
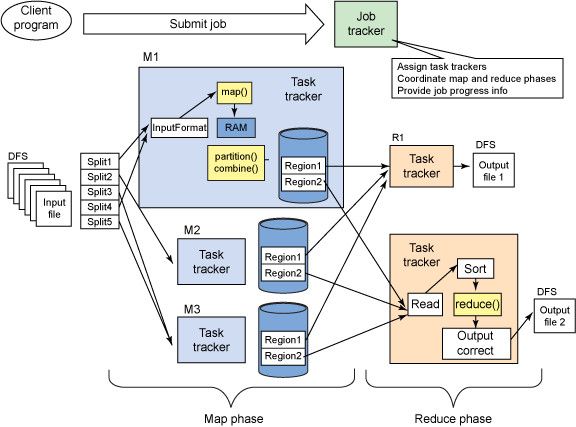
参考:MapReduce原理与设计思想; MapReduce框架详解;详解Hadoop核心架构;
Hadoop 调度机制
Hadoop集群中,服务器按用途分为 Master 节点和 Worker 节点:
- Master:任务拆分和任务分配,含有 JobTracker(安排MapReduce运算层任务)和 NameNode(管理HDFS数据层存储)程序
- Worker:任务执行,含有 TaskTracker(接受JobTracker调度,执行MapReduce运算层任务)和 DataNode(执行数据读写操作、执行副本策略)程序
在MapReduce运算层上,Master服务器负责分配运算任务,JobTracker程序将Map和Reduce程序的执行工作指派给Worker服务器上的TaskTracker程序,由TaskTracker负责执行Map和Reduce工作,并将运算结果返回给JobTracker。
注意,Master节点也可以有TaskTracker和DataNode程序,即Master服务器可以在本地端扮演Worker角色。此外,map任务的分配考虑数据本地化(Data Local),reduce任务的分配并不考虑。
MapReduce执行流程
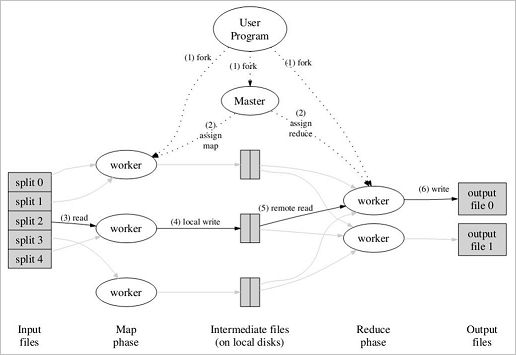
整个过程,具体参考:Hadoop-分布式计算平台初探。Map/Reduce框架和分布式文件系统运行在一组相同的节点上,Master节点负责任务的调度和监控、重新执行已失败的任务,Worker节点负责任务的执行。输入数据来自底层分布式文件系统,中间数据放在本地文件系统,最终输出数据写入底层分布式文件系统。注意 Map/Reduce作业 和 map/reduce函数 的区别:
- Map作业处理一个输入文件数据的分片,可能需要调用多次map函数来处理每个输入的键值对,一个Map作业对应一个文件分片;
- Reduce作业处理一个分区的中间键值对,需要对每个不同的键调用一次reduce函数,一个Reduce作业最终对应一个输出文件;
map函数:接受一个键值对(key-value pair),产生一组中间键值对
各个map函数对所划分的数据并行处理,从不同的输入数据产生不同的中间结果输出。
map(String key, String value):
// key: document name, value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce函数:接受一个键以及相关的一组值,将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)
各个reduce函数各自并行计算,各自负责处理不同的中间结果数据集合。在reduce处理前,必须等所有的map函数完成,因此在进入reduce前需要有一个同步障(barrier)负责map节点执行的同步控制,这个阶段也负责对map的中间结果数据进行收集整理(aggregation & shuffle)处理,以便reduce更有效地计算最终结果。最终汇总所有reduce的输出结果即可获得最终结果。
reduce(String key, Iterator values):
// key: a word, values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
在map处理完成、进入reduce处理之前,中间结果数据会经过 Partitioner(划分)和 Combiner(合并)的处理:
- Partitioner:一个reducer节点所处理的数据可能来自多个map节点,因此map节点输出的中间结果需使用一定的策略进行划分处理,保证相关数据发送到同一个reducer节点,可以理解为GroupByKey
- Combiner:为减少数据通信开销,中间结果数据进入reduce节点前需要进行合并处理,把具有同样主键的数据合并到一起,避免重复传送
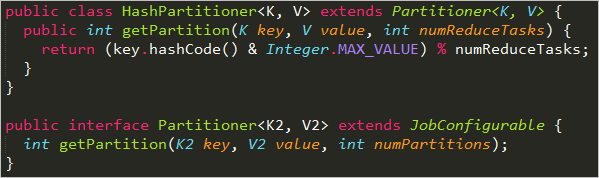
关于Partitioner,利用了负载均衡的思想,对进入到Reduce的键值对根据key值计算hash再对Reduce个数进行求余进行分组到Reduce。在MapReduce中,默认的partitioner是HashPartitioner类,通过方法 getPartition()获取分区值。若要实现自定义的分区函数,重写getPartition()方法即可。对Partitioner的深入理解,有兴趣可以参见:Hadoop中Partition深度解析
关于Combiner,号称本地的Reduce,Reduce最终的输入是Combiner的输出。
一个问题,Partitioner和Combiner执行顺序问题,理论上 Partitioner ---> Combiner,不过 Combiner ---> Partitioner 性能要更优。
此外,可以再结合官方给出的示意图,理解 Map - Reduce 过程:
关于Shuffle过程
通常map task和reduce task在不同的DataNode上执行,主要的开销:网络传输和磁盘IO
Shuffle过程是MapReduce的核心,负责数据从map task输出到reduce task输入,把map task的输出结果有效地传送到reduce端。
- 完整地从map端拉取数据到reduce端
- 跨节点拉取数据时,尽可能地减少对带宽的不必要消耗
- 减少磁盘IO对task执行的影响
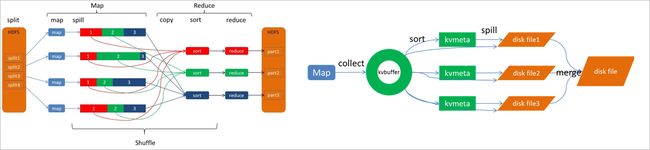
Shuffle过程横跨map端和reduce端,分为两个阶段:Map端的shuffle阶段(广义Shuffle) 和 Reduce端的Shuffle阶段
- Map端:包括map阶段、Spill过程(输出、sort、溢写、merge)
- Reduce端:包括copy、sort、merge过程、reduce阶段
(1)Shuffle - map端
每个map task都有一个环形内存缓冲区(kvbuffer,默认100MB)(环形,有效利用内存空间),作用是批量收集map结果,减少磁盘IO读写的影响,每个map task的执行结果key/value对和Partition的结果都会被写入缓冲区(可以简单理解为以三元组
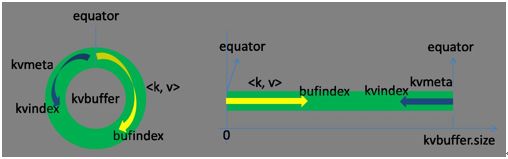
对于环形缓冲区和Partitioner操作,涉及源文件 MapTask.java 的内部类 MapOutputBuffer,该类主要用于:(1)缓冲map输出数据;(2)数据局部排序;
环形缓冲区存储两种数据:
- K/V数据:kv,map task的输出键值对,存储方向是向上增长
- 索引数据:kvmeta,键值对在环形缓冲区的索引,存储方向是向下增长,每个meta信息 =
数据区域和索引区域在缓冲区是相邻但不重叠的两个部分,以equator为分界点,初始 equator=0,每执行一次spill过程,更新equator。
在MapOutputBuffer中meta的存储信息如下:
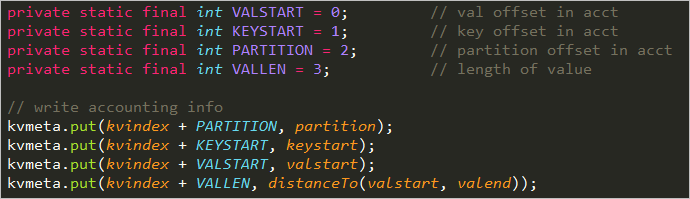
若有兴趣深入理解MapOutputBuffer,具体参见:Map输出数据的处理类MapOutputBuffer分析; MapOutputBuffer理解的三重境界;
亦可参见:腾讯大数据之TDW计算引擎解析—Shuffle,针对 Shuffle 过程作了详细解释,包括 k-v-p 信息的存储问题。
当缓冲区快满(80%)时需要将缓冲区数据以一个临时文件的方式存放到磁盘(spill to disk),当整个map task执行结束后再对磁盘中由这个map task产生的所有临时文件合并,生成最终的正式输出文件(分区且排序),然后等待reduce task来拉数据。注意,只要设置了combiner,在map端会执行两次combiner:
- 第一次是在 spill 阶段,该过程在内存中执行,针对这80M的内存缓冲区执行sort和combiner,partitioner在写入内存缓冲区之前已经执行
- 第二次是在 merge 阶段,该过程在disk中进行,针对disk中的多个溢写文件执行combiner合并成一个文件
在map阶段执行sort(在spill阶段对key排序,对相同key的value排序)和combiner(对相同key的value合并)操作的必要性:
- 尽量减少每次写入磁盘的数据量
- 尽量减少在复制阶段网络传输的数据量
注意,为了减少数据通量,此处也可以执行数据压缩操作。在Java中,对输出数据压缩设置:
// map端输出压缩
conf.SetBoolean("mapred.compress.map.output", true)
// reduce端输出压缩
conf.SetBoolean("mapred.output.compress", true)
// reduce端输出压缩使用的类
conf.SetClass("mapred.output.compression.codec", GzipCodex.class, CompressionCodec.class)
关于spill过程,执行者是SortAndSpill,包括输出、排序、溢写、合并阶段。
- 输出:collect,map task结果输出到环形缓冲区中,collect()方法会调用 getPartition() 方法
- 排序:sort,把kvbuffer中数据按partition和key两个关键字排序,移动的只是索引数据,结果是kvmeta中的数据按partition为单位分区聚集,同一partition内按key有序
- 溢写:spill,溢写内容输出到文件,分区在文件中的位置用三元组
的形式索引 - 合并:merge(combine),合并该map task输出的所有溢写文件,一个map task最终对应一个中间输出文件
有兴趣可参考:Map阶段分析之spill过程;
(2)Shuffle - reduce端
在reduce task执行之前,reduce端的工作就是不断地拉取当前job里每个map task的最终结果,然后对从不同地方拉取过来的数据不断地做merge(实质是归并排序),最终形成一个文件作为reduce task的输入文件。关于reducer进程的启动,当正在运行+已完成的map task达到一定比例后由JobTracker分配运行reduce task。注意,只要设置了combiner,在reduce端会执行两次combiner:
- 第一次是在内存缓冲区到disk的 merge 阶段(内存-->磁盘):当内存中的数据量到达一定阈值,启动内存到磁盘的merge,将内存数据溢写到disk中
- 第二次是在disk中的 merge 阶段(磁盘-->磁盘):将disk中的多个溢写文件执行combiner合并成一个文件
注意,在内存缓冲区中并不执行merge操作(内存-->内存)。最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。每一个reducer对应一个输出文件到HDFS,多个reducer的输出文件不执行合并操作,每个输出文件以Reducer number为标识。
对于Shuffle过程的深入理解参见:MapReduce - Shuffle,文中结合上图对Shuffle过程拆分,对具体地细节作出了详细解释,文末的评论也不错,有值得借鉴的地方。其他关于MapReduce的信息参见:讲座总结|解读大数据世界中MapReduce的前世今生; MapReduce的一点理解;
参考
- Apache™ Hadoop® 官网;
- Hadoop - 初识MapReduce - Edison Chou;以及 Hadoop - MapReduce中的排序和分组;Hadoop - Shuffle过程那点事儿;
Spark
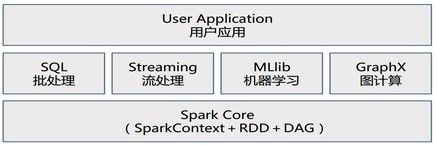
Spark是一个生态系统,内核由Scala语言开发,为批处理(Spark Core)、交互式(Spark SQL)、流式处理(Spark Streaming)、机器学习(MLlib)、图计算(GraphX)提供了一个更快、更通用的统一的数据处理平台(One Stack rule them all),是类Hadoop MapReduce的通用并行框架。
- Spark Core:基本引擎,提供内存计算框架、提供Cache机制支持数据共享和迭代计算,用于大规模并行和分布式数据处理
- 采用线程池模型减少Task启动开稍
- 采用容错的、高可伸缩性的Akka作为通讯框架
- Spark SQL:支持SQL或者Hive查询语言来查询数据
Spark 被标榜为:"快如闪电的集群计算"
- 开源分布式计算系统
- 基于内存处理的大数据并行计算框架
- 数据处理的实时性,高容错性,高可伸缩性,负载均衡
- 统一的编程模型:高效支持整合批量处理和交互式流分析
Spark 生态系统名称:伯克利数据分析栈(BDAS)

关于官网对 Spark 的介绍:
Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
Apache Spark™ is a fast and general engine for large-scale data processing.
- Speed:Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
- Ease of Use:Write applications quickly in Java, Scala, Python, R.
- Generality:Combine SQL, streaming, and complex analytics.
- Runs Everywhere:Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and S3.
Spark 最核心设计:
- RDD:海量数据存储,内存或磁盘存储;
Spark 专用名词预热:
- Application:Spark 应用程序,包含一个 Driver 程序和分布在集群中多个节点上运行的若干 Executor 代码
- Operation:作用于 RDD 的各种操作分为 Transformation 和 Action
- Job:作业,SparkContext 提交的具体 Action 操作,一个 Job 包含多个 RDD 及作用于相应 RDD 上的各种 Operation,常与Action对应
- Stage:每个 Job 会被拆分很多组任务,每组任务被称为 Stage,也称TaskSet,即一个作业包含多个阶段
- Partition:数据分区,一个 RDD 中的数据可以分成多个不同的区
- DAG:Directed Acycle graph, 有向无环图,反映 RDD 之间的依赖关系
- Caching Managenment:缓存管理,对 RDD 的中间计算结果进行缓存管理以加快整体的处理速度
Driver in Application ---> Job(RDDs with Operations) ---> Stage ---> Task
RDD 相关术语:
- batch interval:时间片或微批间隔,一个时间片的数据由 Spark Engine 封装成一个RDD实例
- batch data:批数据,将实时流数据以时间片为单位分批
- window length:窗口长度,必须是 batch interval 的整数倍
- window slide interval:窗口滑动间隔,必须是 batch interval 的整数倍
关于 Spark 处理速度为什么比 (Hadoop)MapReduce 快?
- MapReduce 中间结果在 HDFS 上,Spark 中间结果在内存,迭代运算效率高
- MapReduce 排序耗时,Spark 可以避免不必要的排序开销
- Spark 能够将要执行的一系列操作做成一张有向无环图(DAG),然后进行优化
此外,Spark 性能优势
- 采用事件驱动的类库 AKKA 启动任务,通过线程池来避免启动任务的开销
- 通用性更好,支持 map、reduce、filter、join 等算子
AKKA,分布式应用框架,JAVA虚拟机JVM平台上构建高并发、分布式和容错应用的工具包和运行时,由 Scala 编写的库,提供 Scala和JAVA 的开发接口。
- 并发处理方法基于Actor模型
- 唯一通信机制是消息传递
RDD
Resilient Distributed Dataset,弹性分布式数据集,RDD 是基于内存的、只读的、分区存储的可重算的元素集合,支持粗粒度转换(即:在大量记录上执行相同的单个操作)。RDD.class 是 Spark 进行数据分发和计算的基础抽象类,RDD 是 Spark 中的抽象数据结构类型,任何数据在 Spark 中都被表示为 RDD。
RDD是一等公民。Spark最核心的模块和类,Spark中的一切都是基于RDD的。
RDD 来源
- 并行化驱动程序中已存在的内存集合 或 引用一个外部存储系统已存在的数据集
- 通过转换操作来自于其他 RDD
此外,可以使 Spark 持久化一个 RDD 到内存中,使其在并行操作中被有效的重用,RDDs 也可以自动从节点故障中恢复(基于 Lineage 血缘继承关系)。
基于 RDD 的操作类型
- Transformation(转换):具体指RDD中元素的映射和转换(RDD-to-RDD),常用操作有map、filter等
- Action(动作):提交Spark作业,启动计算操作,并产生最终结果(向用户程序返回或者写入文件系统)
转换是延迟执行的,通过转换生成一个新的RDD时候并不会立即执行(只记录Lineage,不会加载数据),只有等到 Action 时,才触发操作(根据Lineage完成所有的转换)。
操作类型区别:返回结果为RDD的API是转换,返回结果不为RDD的API是动作。
常用算子清单

关于相关算子的初识:Spark RDD API 详解
依赖关系:窄依赖,父RDD的每个分区都只被子RDD的一个分区所使用;宽依赖,父RDD的分区被多个子RDD的分区所依赖。
- 窄依赖可以在某个计算节点上直接通过计算父RDD的某块数据得到子RDD对应的某块数据;
- 数据丢失时,窄依赖只需要重新计算丢失的那一块数据来恢复;
SparkConf
运行配置,一组 K-V 属性对。SparkConf 用于指定 Application 名称、master URL、任务相关参数、调优配置等。构建 SparkContext 时可以传入 Spark 相关配置,即以 SparkConf 为参实例化 SparkContext 对象。
SparkContext
运行上下文。Spark 集群的执行单位是 Application,提交的任何任务都会产生一个 Application,一个Application只会关联上一个Spark上下文。SparkContext 是 Spark 程序所有功能的唯一入口,类似 main() 函数。
关于共享变量
Spark 提供两种类型的共享变量(Shared varialbes),提升集群环境中的 Spark 程序运行效率。
- 广播变量:Broadcast Variables,Spark 向 Slave Nodes 进行广播,节点上的 RDD 操作可以快速访问 Broadcast Variables 值,而每台机器节点上缓存只读变量而不需要为各个任务发送该变量的拷贝;
- 累加变量:Accumulators,只有在使用相关操作时才会添加累加器(支持一个只能做加法的变量,如计数器和求和),可以很好地支持并行;
Spark Streaming
构建在 Spark 上的流数据处理框架组件,基于微批量的方式计算和处理实时的流数据,高效、高吞吐量、可容错、可扩展。
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams,
which makes it easy to build scalable fault-tolerant streaming applications.
- Ease of use:Build applications through high-level operators.
- Fault Tolerance:Stateful exactly-once semantics out of the box.
- Spark Integration:Combine streaming with batch and interactive queries.
基本原理是将输入数据流以时间片(秒级)为单位进行拆分成 micro batches,将 Spark 批处理编程模型应用到流用例中,然后以类似批处理的方式处理时间片数据。

图中的 Spark Engine 批处理引擎是 Spark Core。
Spark Streaming 提供一个高层次的抽象叫做离散流(Discretized Stream,DStream),代表持续的数据流(即一系列持续的RDDs)。DStream 中的每个 RDD 都是按一小段时间(Interval)分割开来的数据集,对 DStream 的任何操作都会转化成对底层 RDDs 的操作(将 Spark Streaming 中对 DStream 的操作变为针对 Spark 中 RDD 的操作)。
sc.foreachRDD { rdd =>
rdd.foreachPartition { partition =>
partition.foreach ( record =>
send(record)
)
}
}
Spark 的 StreamingContext 设置完毕后,启动执行:
sc.start() // 启动计算
sc.awaitTermination() // 等待计算完成
具体参考:Spark Streaming初探
此外,Spark Streaming 还支持窗口操作,具体地:
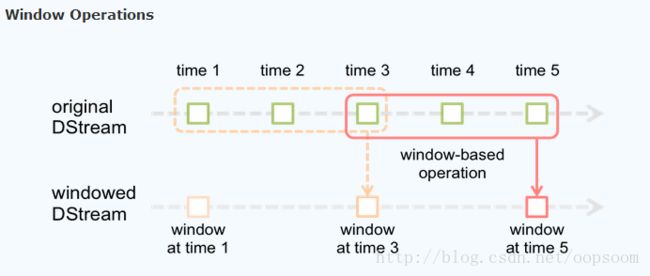
实际应用场景中,企业常用于从Kafka中接收数据做实时统计。
Spark SQL
Spark SQL 的前身是 Shark(Hive on Spark)。
结构化数据处理和查询、提供交互式分析,以 DataFrame(原名 SchemaRDD)形式。DataFrame 是一种以RDD为基础的分布式数据集,是带有 schema 元信息的RDD,即 DataFrame 所表示的二维表数据集的每一列都带有名称和类型。
Spark 容错机制
分布式数据集的容错性通过两种方式实现:设置数据检查点(Checkpoint Data) 和 记录数据的更新(Logging the Updates)。
Spark容错机制通过 Lineage(主) - CheckPoint(辅) 实现
- Lineage:粗粒度的记录更新操作
- Checkpoint:通过冗余数据缓存数据
RDD会维护创建RDDs的一系列转换记录的相关信息,即:Lineage(RDD的血缘关系),这是Spark高效容错机制的基础,用于恢复出错或丢失的分区。
RDD 之于 分区,文件 之于 文件块
若依赖关系链 Lineage 过长时,使用 Checkpoint 检查点机制,切断血缘关系、将数据持久化,避免容错成本过高。
Spark 调度机制
Spark 应用提交后经过一系列的转换,最后成为 Task 在每个节点上执行。相关概念理解:
- Client:客户端(Driver端)进程,负责提交作业到Master。
- Master:主控节点,负责接收Client提交的作业,管理Worker,并命令Worker启动分配Driver的资源和启动Executor的资源
- Worker:集群中任何可以运行Application代码的节点,也可以看作是Slaver节点上的守护进程,负责管理本节点的资源,定期向Master汇报心跳,接收Master的命令,启动Driver和Executor,是Master和Executor之间的桥梁
- Driver:用户侧逻辑处理,运行main()函数并创建SparkContext(准备Spark应用程序运行环境、负责与ClusterManager通信进行资源申请、任务分配和监控
- Executor:Slaver节点上的后台执行进程,即真正执行作业的地方,并将将数据保存到内存或者磁盘。一个集群一般包含多个Executor,每个Executor接收Driver的命令Launch Task,一个Executor可以执行一到多个Task(每个Executor拥有一定数量的"slots",可以执行指派给它的Task)
- Task:运行在Executor上的工作单元,每个Task占用父Executor的一个slot (core)
- Cluster Manager:在集群上获取资源的外部服务,目前
- Standalone:Spark原生的资源管理,由 Master 负责资源分配
- Hadoop Yarn:由Yarn中的 ResourceManager 负责资源分配
Spark运行的基本流程如下图:
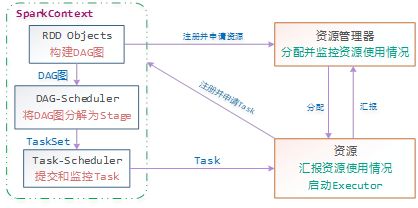
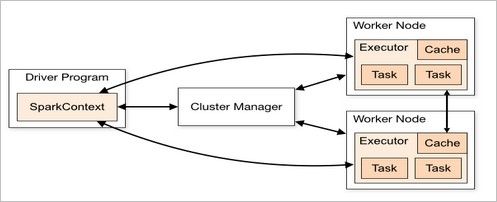
一个Spark作业运行时包括一个Driver进程,也是作业的主进程,负责作业的解析、生成Stage并调度Task到Executor上。包括:
- DAGScheduler:实现将Spark作业分解成一到多个Stage,每个Stage根据RDD的Partition个数决定Task的个数,然后生成相应的TaskSet放到TaskScheduler中
- TaskScheduler:维护所有的TaskSet,实现Task分配到Executor上执行并维护Task的运行状态
每一个 Spark 应用程序,都是由一个驱动程序组成,运行用户的 Main 函数,并且在一个集群上执行各种各样的并行操作:
所有的 Spark 应用程序都离不开 SparkContext 和 Executor 两部分,Executor 负责具体执行任务,运行 Executor 的机器称为 Worker 节点,SparkContext 由用户程序启动,通过资源调度模块和 Executor 通信。SparkContext 和 Executor 这两部分的核心代码实现在各种运行模式中都是公用的,在它们之上,根据运行部署模式的不同,包装了不同调度模块以及相关的适配代码。具体来说,以 SparkContext 为程序运行的总入口,在 SparkContext 的初始化过程中,Spark 会分别创建 DAGScheduler(作业调度)和 TaskScheduler(任务调度)两个调度模块。其中,作业调度模块是基于任务阶段的高层调度模块,它为每个 Spark 作业计算具有依赖关系的多个调度阶段 (通常根据 Shuffle 来划分),然后为每个阶段构建出一组具体的任务 (通常会考虑数据的本地性等),然后以 TaskSets(任务组) 的形式提交给任务调度模块来具体执行。而任务调度模块则负责具体启动任务、监控和汇报任务运行情况。具体地:
关于 Spark 的运行架构和机制,参见:http://www.cnblogs.com/shishanyuan/p/4721326.html
Spark 环境搭建
注意,Spark和Scala的版本兼容问题,Spark 1.x.x 匹配 Scala 2.10.x 及以下,Spark 2.x.x 匹配 Scala 2.11.x 及以上。官网解释如下:
Starting version 2.0, Spark is built with Scala 2.11 by default. Scala 2.10 users should download the Spark source package and build with Scala 2.10 support.
推荐使用 Spark 2。若本机安装的是 Scala 2.10,需要 Building for Scala 2.10:

参考
- Apache SparkTM 官网; Spark - code123.cc;
- Apache Spark, An Engine for Large-Scale Data Processing;
完美的大数据场景:让Hadoop和Spark在同一个团队里面协同运行。
- Hadoop偏重数据存储 (文件管理系统,HDFS离线数据存储),但有自己的数据处理工具MapReduce。
- Spark偏重数据处理,但需依赖分布式文件系统集成运作。
虽然Hadoop提供了MapReduce的数据处理功能,但是Spark的基于Map Reduce算法实现的分布式计算(内存版的MapReduce)的数据处理速度秒杀MapReduce,通用性更好、迭代运算效率更高、容错能力更强。我们应该将Spark看作是Hadoop MapReduce的一个替代品而不是Hadoop的替代品,其意图并非是替代Hadoop,而是为了提供一个管理不同的大数据用例和需求的全面且统一的解决方案。
Storm
Storm是一个开源的分布式实时计算系统,最流行的流计算平台。

关于官网对 Storm 介绍:
Apache Storm is a free and open source distributed realtime computation system. Storm makes it easy to reliably process unbounded streams of data, doing for realtime processing what Hadoop did for batch processing. Storm is simple, can be used with any programming language, and is a lot of fun to use!
- fast:a benchmark clocked it at over a million tuples processed per second per node.
- scalable, fault-tolerant, guarantees your data will be processed, and is easy to set up and operate.
- realtime analytics, online machine learning, continuous computation, distributed RPC, ETL
参考
- Apache Storm 官网;
其他的相关概念:
HBase:面向列、可伸缩的高可靠性、高性能分布式存储系统,构建大规模结构化数据集群
Hive:由 Facebook 主导的基于 Hadoop 的大数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行执行
Zookeeper:由 Google 主导的开源分布式应用程序协调服务
Mesos:分布式环境资源管理平台
Tez:由 Hortonworks 主导的优化 MapReduce 执行引擎,性能更高
Yarn:组件调度系统
BlinkD:在海量数据上运行交互式 SQL 查询的大规模并行查询引擎
Kafka:实时、容错、可扩展的分布式发布-订阅消息系统,用于实时移动数据,详情参见:Kafka - sqh;