Spark通讯架构 脚本探究:
概述
Spark 内核泛指 Spark 的核心运行机制,包括 Spark 核心组件的运行机制、Spark 任务调度机制、Spark 内存管理机制、Spark 核心功能的运行原理。
核心组件
Driver
Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作。Driver 在 Spark 作业执行时主要负责:
将用户程序转化为任务(job);
在 Executor 之间调度任务(task);
跟踪 Executor 的执行情况;
通过 UI 展示查询运行情况;
Executor
Spark Executor 节点是一个 JVM 进程,负责在 Spark 作业中运行具体任务,任务彼此之间相互独立。Spark 应用启动时, Executor 节点被同时启动, 并且始终伴随着整个 Spark 应用的生命周期而存在。如果有 Executor 节点发生了故障或崩溃,Spark 应用也可以继续执行, 会将出错节点上的任务调度到其他 Executor 节点上继续运行。
Executor 有两个核心功能:
负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程;
它们通过自身的块管理器( Block Manager)为用户程序中要求缓存的 RDD提供内存式存储。RDD 是直接缓存在 Executor 进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
运行流程
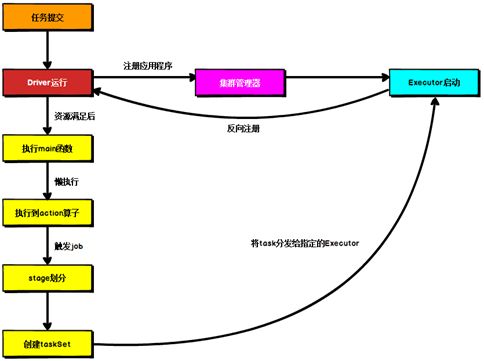
Spark 通用运行流程, 不论 Spark 以何种模式进行部署, 任务提交后, 都会先启动 Driver 进程,随后 Driver 进程向集群管理器注册应用程序,之后集群管理器根据此任务的配置文件分配 Executor 并启动,当 Driver 所需的资源全部满足后,
Driver 开始执行 main 函数, Spark 查询为懒执行, 当执行到 action 算子时开始反向推算,根据宽依赖进行 stage 的划分,随后每一个 stage 对应一个 taskset,taskset 中有多个 task,根据本地化原则, task 会被分发到指定的 Executor 去执行,在任务执行的过程中, Executor 也会不断与 Driver 进行通信,报告任务运行情况。
部署模式
Standalone
Standalone 集群有四个重要组成部分, 分别是:
Driver: 是一个进程,我们编写的 Spark 应用程序就运行在 Driver 上, 由Driver 进程执行;
Master:是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责;
Worker:是一个进程,一个 Worker 运行在集群中的一台服务器上,主要负责两个职责,一个是用自己的内存存储 RDD 的某个或某些 partition;另一个是启动其他进程和线程(Executor) ,对 RDD 上的 partition 进行并行的处理和计算。
Executor:是一个进程, 一个 Worker 上可以运行多个 Executor, Executor 通过启动多个线程( task)来执行对 RDD 的 partition 进行并行计算,也就是执行我们对 RDD 定义的例如 map、flatMap、reduce 等算子操作。
Standalone Client
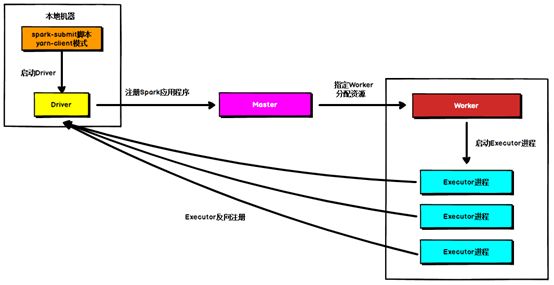
Standalone Client 模式下,Driver 在任务提交的本地机器上运行,Driver 启动后向 Master 注册应用程序,Master 根据 submit 脚本的资源需求找到内部资源至少可以启动一个 Executor 的所有 Worker,然后在这些 Worker 之间分配 Executor,Worker 上的 Executor 启动后会向 Driver 反向注册,所有的 Executor 注册完成后,Driver 开始执行 main 函数,之后执行到 Action 算子时,开始划分 stage,每个 stage 生成对应的 taskSet,之后将 task 分发到各个 Executor 上执行。
Standalone Cluster
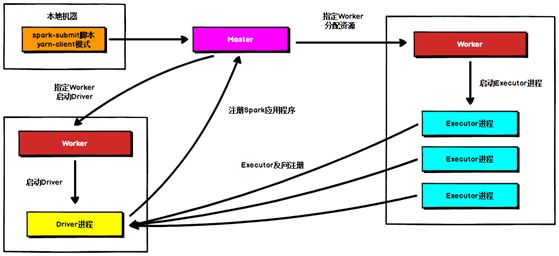
Standalone Cluster 模式下,任务提交后,Master 会找到一个 Worker 启动 Driver进程, Driver 启动后向 Master 注册应用程序, Master 根据 submit 脚本的资源需求找到内部资源至少可以启动一个 Executor 的所有 Worker,然后在这些 Worker 之间分配 Executor,Worker 上的 Executor 启动后会向 Driver 反向注册,所有的 Executor 注册完成后,Driver 开始执行 main 函数,之后执行到 Action 算子时,开始划分 stage,每个 stage 生成对应的 taskSet,之后将 task 分发到各个 Executor 上执行。
注意, Standalone 的两种模式下( client/Cluster) , Master 在接到 Driver 注册
Spark 应用程序的请求后,会获取其所管理的剩余资源能够启动一个 Executor 的所有 Worker, 然后在这些 Worker 之间分发 Executor, 此时的分发只考虑 Worker 上的资源是否足够使用,直到当前应用程序所需的所有 Executor 都分配完毕, Executor 反向注册完毕后,Driver 开始执行 main 程序。
YARN Client

在 YARN Client 模式下,Driver 在任务提交的本地机器上运行,Driver 启动后会和 ResourceManager 通讯申请启动 ApplicationMaster, 随后 ResourceManager 分配 container , 在 合 适 的 NodeManager 上启动 ApplicationMaster ,此时的
ApplicationMaster 的功能相当于一个 ExecutorLaucher, 只负责向 ResourceManager 申请 Executor 内存。
ResourceManager 接到 ApplicationMaster 的资源申请后会分配 container,然后ApplicationMaster 在资源分配指定的 NodeManager 上启动 Executor 进程, Executor 进程启动后会向 Driver 反向注册, Executor 全部注册完成后 Driver 开始执行 main 函数,之后执行到 Action 算子时,触发一个 job,并根据宽依赖开始划分 stage,每个 stage 生成对应的 taskSet,之后将 task 分发到各个 Executor 上执行。
YARN Cluster
在 YARN Cluster 模式下, 任务提交后会和 ResourceManager 通讯申请启动ApplicationMaster, 随后 ResourceManager 分配 container,在合适的 NodeManager上启动 ApplicationMaster,此时的 ApplicationMaster 就是 Driver。
Driver 启动后向 ResourceManager 申请 Executor 内存, ResourceManager 接到ApplicationMaster 的资源申请后会分配 container,然后在合适的 NodeManager 上启动 Executor 进程,Executor 进程启动后会向 Driver 反向注册, Executor 全部注册完成后 Driver 开始执行 main 函数,之后执行到 Action 算子时,触发一个 job,并根据宽依赖开始划分 stage,每个 stage 生成对应的 taskSet,之后将 task 分发到各个Executor 上执行。
通讯架构
Spark2.x 版本使用 Netty 通讯框架作为内部通讯组件。spark 基于 netty 新的 rpc框架借鉴了 Akka 的中的设计, 它是基于Actor 模型。
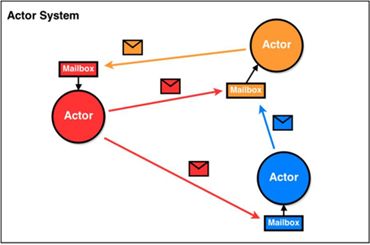
Scala里面处理通信采用Actor架构,Actor架构其实就是一个邮局模型, AKKA为给予Actor模型的工程实现。Akka不同版本之间无法通信,存在兼容性问题。用户使用Akka与Spark中的Akka存在冲突。Spark对Akka没有自身维护,需要新功能时只能等待新版本,比较牵制Spark发展。因此在Spark2中已经抛弃了Akka。
Spark早期版本中采用Akka作为内部通信部件。
Spark1.3中引入Netty通信框架,为了解决Shuffle的大数据传输问题使用
Spark1.6中Akka和Netty可以配置使用。Netty完全实现了Akka在Spark中的功能。
Spark2系列中,Spark抛弃Akka,使用Netty。
Spark 通讯框架中各个组件( Client/Master/Worker)可以认为是一个个独立的实体,各个实体之间通过消息来进行通信。具体各个组件之间的关系图如下:
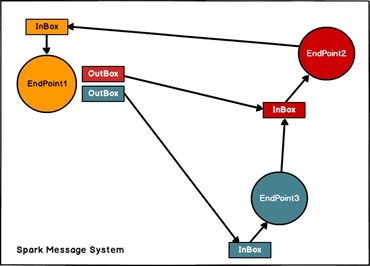
Endpoint( Client/Master/Worker)有 1 个 InBox 和 N 个 OutBox( N>=1,N 取决于当前 Endpoint 与多少其他的 Endpoint 进行通信, 一个与其通讯的其他 Endpoint 对应一个 OutBox), Endpoint 接收到的消息被写入 InBox, 发送出去的消息写入OutBox 并被发送到其他 Endpoint 的 InBox 中。

1) RpcEndpoint:RPC 端点,Spark 针对每个节点( Client/Master/Worker)都称之为一个 Rpc 端点,且都实现 RpcEndpoint 接口,内部根据不同端点的需求,设计不同的消息和不同的业务处理,如果需要发送(询问)则调用 Dispatcher;
2) RpcEnv: RPC 上下文环境, 每个 RPC 端点运行时依赖的上下文环境称为RpcEnv;
3) Dispatcher:消息分发器,针对于 RPC 端点需要发送消息或者从远程 RPC 接收到的消息,分发至对应的指令收件箱/发件箱。如果指令接收方是自己则存入收件箱,如果指令接收方不是自己,则放入发件箱;
4) Inbox:指令消息收件箱,一个本地 RpcEndpoint 对应一个收件箱,Dispatcher 在每次向 Inbox 存入消息时, 都将对应 EndpointData 加入内部 ReceiverQueue 中, 另外 Dispatcher 创建时会启动一个单独线程进行轮询 ReceiverQueue,进行收件箱消息消费;
5) RpcEndpointRef:RpcEndpointRef 是对远程 RpcEndpoint 的一个引用。当我们需要向一个具体的 RpcEndpoint 发送消息时,一般我们需要获取到该 RpcEndpoint 的引用,然后通过该应用发送消息。
6) OutBox : 指令消息发件箱 , 对于当前 RpcEndpoint 来说 , 一个目标RpcEndpoint 对应一个发件箱, 如果向多个目标 RpcEndpoint 发送信息, 则有多个OutBox。当消息放入 Outbox 后,紧接着通过 TransportClient 将消息发送出去。消息放入发件箱以及发送过程是在同一个线程中进行;
7) RpcAddress: 表示远程的 RpcEndpointRef 的地址, Host + Port。
8) TransportClient:Netty 通信客户端,一个 OutBox 对应一个 TransportClient,TransportClient 不断轮询 OutBox,根据 OutBox 消息的 receiver 信息,请求对应的远程 TransportServer;
9) TransportServer : Netty通信服务端 , 一 个 RpcEndpoint 对应一个TransportServer,接受远程消息后调用Dispatcher 分发消息至对应收发件箱;
RpcEndPoint就代表一个通信端点, 一个端点就有一个inbox, 一个 transportServer 一个 Dispatcher, 根据你通信的其他端点的数目,就有多个Outbox, 一个outbox有一个 transportClient, transportClient主要负责和 transportServer来通信。
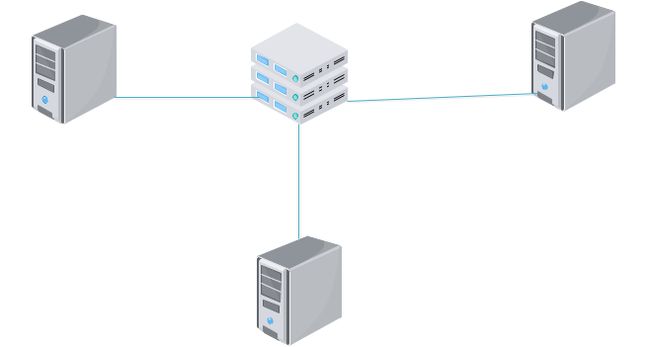
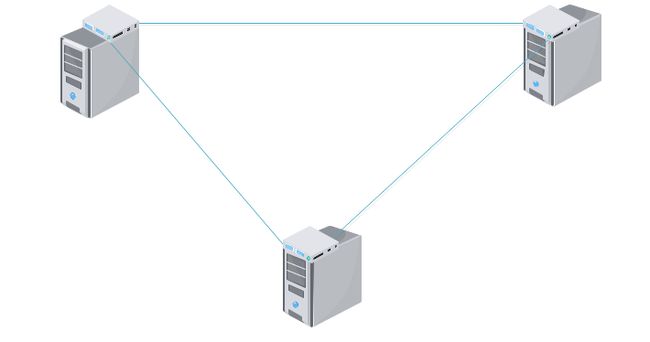
在我们的传统认知中,多个端点要通信,中间要有一个节点类似于总的路由,节点之间的通信靠中间的“路由”,而 Spark没有中间的这个“路由”,如果中间的“路由”存在一定会存在瓶颈问题。Spark很巧妙的把中间的“路由”拆分到各个节点上。
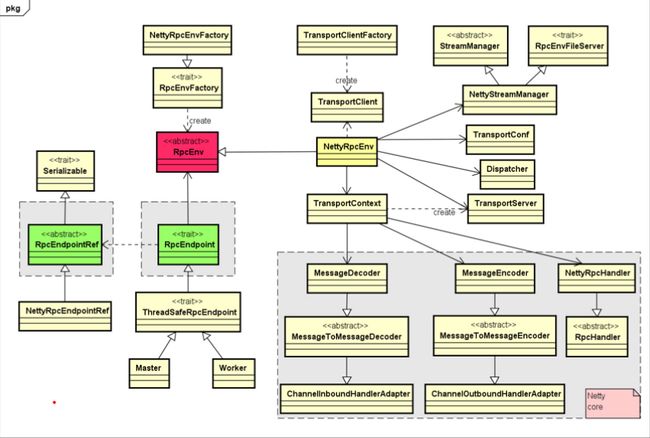
高层视图

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
private[spark] trait RpcEndpoint {
val rpcEnv: RpcEnv
....
}
def receive: PartialFunction[Any, Unit] = {
case _ => throw new SparkException(self + " does not implement 'receive'")
}
def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case _ => context.sendFailure(new SparkException(self + " won't reply anything"))
}
def onStart(): Unit = {
}
|
RpcEndpoint 注意三个方法,
1、receive 改方法被子类实现,用于接收其他节点发送的消息。
2、receiveAndReply 该方法被子类实现,用于接收并回复其他节点发送的消息。
3、onStart 该方法被子类实现,该方法在端口启动的时候自动调用。
我们查看以下RpcEnv的实现发现实现是NettyRpcEnv
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
|
private[netty] class NettyRpcEnv(
val conf: SparkConf,
javaSerializerInstance: JavaSerializerInstance,
host: String,
securityManager: SecurityManager) extends RpcEnv(conf) with Logging {
private[netty] val transportConf = SparkTransportConf.fromSparkConf(
conf.clone.set("spark.rpc.io.numConnectionsPerPeer", "1"),
"rpc",
conf.getInt("spark.rpc.io.threads", 0))
private val dispatcher: Dispatcher = new Dispatcher(this)
private val streamManager = new NettyStreamManager(this)
private val transportContext = new TransportContext(transportConf,
new NettyRpcHandler(dispatcher, this, streamManager))
private def createClientBootstraps(): java.util.List[TransportClientBootstrap] = {
if (securityManager.isAuthenticationEnabled()) {
java.util.Arrays.asList(new SaslClientBootstrap(transportConf, "", securityManager,
securityManager.isSaslEncryptionEnabled()))
} else {
java.util.Collections.emptyList[TransportClientBootstrap]
}
}
private val clientFactory = transportContext.createClientFactory(createClientBootstraps())
@volatile private var fileDownloadFactory: TransportClientFactory = _
val timeoutScheduler = ThreadUtils.newDaemonSingleThreadScheduledExecutor("netty-rpc-env-timeout")
private[netty] val clientConnectionExecutor = ThreadUtils.newDaemonCachedThreadPool(
"netty-rpc-connection",
conf.getInt("spark.rpc.connect.threads", 64))
@volatile private var server: TransportServer = _
private val stopped = new AtomicBoolean(false)
private val outboxes = new ConcurrentHashMap[RpcAddress, Outbox]()
private[netty] def removeOutbox(address: RpcAddress): Unit = {
val outbox = outboxes.remove(address)
if (outbox != null) {
outbox.stop()
}
}
def startServer(bindAddress: String, port: Int): Unit = {
val bootstraps: java.util.List[TransportServerBootstrap] =
if (securityManager.isAuthenticationEnabled()) {
java.util.Arrays.asList(new SaslServerBootstrap(transportConf, securityManager))
} else {
java.util.Collections.emptyList()
}
server = transportContext.createServer(bindAddress, port, bootstraps)
dispatcher.registerRpcEndpoint(
RpcEndpointVerifier.NAME, new RpcEndpointVerifier(this, dispatcher))
}
@Nullable
override lazy val address: RpcAddress = {
if (server != null) RpcAddress(host, server.getPort()) else null
}
override def setupEndpoint(name: String, endpoint: RpcEndpoint): RpcEndpointRef = {
dispatcher.registerRpcEndpoint(name, endpoint)
}
....
|
我们似乎没有看到Inbox在哪里点击Dispatcher
1
2
3
4
5
6
|
private class EndpointData(
val name: String,
val endpoint: RpcEndpoint,
val ref: NettyRpcEndpointRef) {
val inbox = new Inbox(ref, endpoint)
}
|
启动脚本
start-all.sh
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# Start all spark daemons.
# Starts the master on this node.
# Starts a worker on each node specified in conf/slaves
if [ -z "${SPARK_HOME}" ]; then #如果没有发现Spark环境变量
export SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)" # 获得当前的目录把当前目录设置为SPARK_HOME
fi
# Load the Spark configuration
. "${SPARK_HOME}/sbin/spark-config.sh" #加载 spark-config.sh配置
# Start Master
"${SPARK_HOME}/sbin"/start-master.sh
# Start Workers
"${SPARK_HOME}/sbin"/start-slaves.sh
|
spark-config.sh
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# included in all the spark scripts with source command
# should not be executable directly
# also should not be passed any arguments, since we need original $*
# symlink and absolute path should rely on SPARK_HOME to resolve
if [ -z "${SPARK_HOME}" ]; then
export SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
export SPARK_CONF_DIR="${SPARK_CONF_DIR:-"${SPARK_HOME}/conf"}" #设置 SPARK_CONF_DIR 目录
# Add the PySpark classes to the PYTHONPATH:
if [ -z "${PYSPARK_PYTHONPATH_SET}" ]; then
export PYTHONPATH="${SPARK_HOME}/python:${PYTHONPATH}"
export PYTHONPATH="${SPARK_HOME}/python/lib/py4j-0.10.4-src.zip:${PYTHONPATH}"
export PYSPARK_PYTHONPATH_SET=1
fi
export JAVA_HOME=/opt/module/jdk1.8.0_162
|
start-master.sh
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# Starts the master on the machine this script is executed on.
if [ -z "${SPARK_HOME}" ]; then
export SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
# NOTE: This exact class name is matched downstream by SparkSubmit.
# Any changes need to be reflected there.
CLASS="org.apache.spark.deploy.master.Master" #调用Master
if [[ "$@" = *--help ]] || [[ "$@" = *-h ]]; then
echo "Usage: ./sbin/start-master.sh [options]"
pattern="Usage:"
pattern+="\|Using Spark's default log4j profile:"
pattern+="\|Registered signal handlers for"
"${SPARK_HOME}"/bin/spark-class $CLASS --help 2>&1 | grep -v "$pattern" 1>&2
exit 1
fi
ORIGINAL_ARGS="$@"
. "${SPARK_HOME}/sbin/spark-config.sh"
. "${SPARK_HOME}/bin/load-spark-env.sh" #加载环境变量
if [ "$SPARK_MASTER_PORT" = "" ]; then # 如果没有端口 默认7077
SPARK_MASTER_PORT=7077
fi
if [ "$SPARK_MASTER_HOST" = "" ]; then
case `uname` in
(SunOS) # 如果没有设置HOST 则把/usr/sbin/check-hostname作为主机名
SPARK_MASTER_HOST="`/usr/sbin/check-hostname | awk '{print $NF}'`"
;;
(*)
SPARK_MASTER_HOST="`hostname -f`"
;;
esac
fi
if [ "$SPARK_MASTER_WEBUI_PORT" = "" ]; then
SPARK_MASTER_WEBUI_PORT=8080
fi
"${SPARK_HOME}/sbin"/spark-daemon.sh start $CLASS 1 \
--host $SPARK_MASTER_HOST --port $SPARK_MASTER_PORT --webui-port $SPARK_MASTER_WEBUI_PORT \
$ORIGINAL_ARGS
|
1
2
3
4
5
6
7
8
9
10
11
|
def main(argStrings: Array[String]) {
Utils.initDaemon(log)
val conf = new SparkConf
val args = new MasterArguments(argStrings, conf)
val (rpcEnv, _, _) = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, conf)
rpcEnv.awaitTermination()
}
|
start-slaves.sh
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
# Starts a slave instance on each machine specified in the conf/slaves file.
if [ -z "${SPARK_HOME}" ]; then
export SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)" #获取当前的目录
fi
. "${SPARK_HOME}/sbin/spark-config.sh"
. "${SPARK_HOME}/bin/load-spark-env.sh" #加载配置
# Find the port number for the master
if [ "$SPARK_MASTER_PORT" = "" ]; then
SPARK_MASTER_PORT=7077
fi
if [ "$SPARK_MASTER_HOST" = "" ]; then
case `uname` in
(SunOS)
SPARK_MASTER_HOST="`/usr/sbin/check-hostname | awk '{print $NF}'`"
;;
(*)
SPARK_MASTER_HOST="`hostname -f`"
;;
esac
fi
# Launch the slaves 调用了start-slave.sh
"${SPARK_HOME}/sbin/slaves.sh" cd "${SPARK_HOME}" \; "${SPARK_HOME}/sbin/start-slave.sh" "spark://$SPARK_MASTER_HOST:$SPARK_MASTER_PORT"
|
start-slave.sh
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
# Starts a slave on the machine this script is executed on.
#
# Environment Variables
#
# SPARK_WORKER_INSTANCES The number of worker instances to run on this
# slave. Default is 1.
# SPARK_WORKER_PORT The base port number for the first worker. If set,
# subsequent workers will increment this number. If
# unset, Spark will find a valid port number, but
# with no guarantee of a predictable pattern.
# SPARK_WORKER_WEBUI_PORT The base port for the web interface of the first
# worker. Subsequent workers will increment this
# number. Default is 8081.
if [ -z "${SPARK_HOME}" ]; then
export SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
# NOTE: This exact class name is matched downstream by SparkSubmit.
# Any changes need to be reflected there.
CLASS="org.apache.spark.deploy.worker.Worker"
if [[ $# -lt 1 ]] || [[ "$@" = *--help ]] || [[ "$@" = *-h ]]; then
echo "Usage: ./sbin/start-slave.sh [options] "
pattern="Usage:"
pattern+="\|Using Spark's default log4j profile:"
pattern+="\|Registered signal handlers for"
"${SPARK_HOME}"/bin/spark-class $CLASS --help 2>&1 | grep -v "$pattern" 1>&2
exit 1
fi
. "${SPARK_HOME}/sbin/spark-config.sh"
. "${SPARK_HOME}/bin/load-spark-env.sh"
# First argument should be the master; we need to store it aside because we may
# need to insert arguments between it and the other arguments
MASTER=$1
shift
# Determine desired worker port
if [ "$SPARK_WORKER_WEBUI_PORT" = "" ]; then
SPARK_WORKER_WEBUI_PORT=8081
fi
# Start up the appropriate number of workers on this machine.
# quick local function to start a worker
function start_instance {
WORKER_NUM=$1
shift
if [ "$SPARK_WORKER_PORT" = "" ]; then
PORT_FLAG=
PORT_NUM=
else
PORT_FLAG="--port"
PORT_NUM=$(( $SPARK_WORKER_PORT + $WORKER_NUM - 1 ))
fi
WEBUI_PORT=$(( $SPARK_WORKER_WEBUI_PORT + $WORKER_NUM - 1 ))
#调用org.apache.spark.deploy.worker.Worker
"${SPARK_HOME}/sbin"/spark-daemon.sh start $CLASS $WORKER_NUM \
--webui-port "$WEBUI_PORT" $PORT_FLAG $PORT_NUM $MASTER "$@"
}
if [ "$SPARK_WORKER_INSTANCES" = "" ]; then
start_instance 1 "$@"
else
for ((i=0; i<$SPARK_WORKER_INSTANCES; i++)); do
start_instance $(( 1 + $i )) "$@"
done
fi
|
workerMain方法
1
2
3
4
5
6
7
8
|
def main(argStrings: Array[String]) {
Utils.initDaemon(log)
val conf = new SparkConf
val args = new WorkerArguments(argStrings, conf)
val rpcEnv = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, args.cores,
args.memory, args.masters, args.workDir, conf = conf)
rpcEnv.awaitTermination()
}
|
任务提交
spark-submit
1
2
3
4
5
6
7
8
|
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
# disable randomized hash for string in Python 3.3+
export PYTHONHASHSEED=0
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
|
spark-class
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
. "${SPARK_HOME}"/bin/load-spark-env.sh
# Find the java binary
if [ -n "${JAVA_HOME}" ]; then
RUNNER="${JAVA_HOME}/bin/java"
else
if [ "$(command -v java)" ]; then
RUNNER="java"
else
echo "JAVA_HOME is not set" >&2
exit 1
fi
fi
# Find Spark jars.
if [ -d "${SPARK_HOME}/jars" ]; then
SPARK_JARS_DIR="${SPARK_HOME}/jars"
else
SPARK_JARS_DIR="${SPARK_HOME}/assembly/target/scala-$SPARK_SCALA_VERSION/jars"
fi
if [ ! -d "$SPARK_JARS_DIR" ] && [ -z "$SPARK_TESTING$SPARK_SQL_TESTING" ]; then
echo "Failed to find Spark jars directory ($SPARK_JARS_DIR)." 1>&2
echo "You need to build Spark with the target \"package\" before running this program." 1>&2
exit 1
else
LAUNCH_CLASSPATH="$SPARK_JARS_DIR/*"
fi
# Add the launcher build dir to the classpath if requested.
if [ -n "$SPARK_PREPEND_CLASSES" ]; then
LAUNCH_CLASSPATH="${SPARK_HOME}/launcher/target/scala-$SPARK_SCALA_VERSION/classes:$LAUNCH_CLASSPATH"
fi
# For tests
if [[ -n "$SPARK_TESTING" ]]; then
unset YARN_CONF_DIR
unset HADOOP_CONF_DIR
fi
# The launcher library will print arguments separated by a NULL character, to allow arguments with
# characters that would be otherwise interpreted by the shell. Read that in a while loop, populating
# an array that will be used to exec the final command.
#
# The exit code of the launcher is appended to the output, so the parent shell removes it from the
# command array and checks the value to see if the launcher succeeded.
build_command() {
"$RUNNER" -Xmx128m -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@"
printf "%d\0" $?
}
CMD=()
while IFS= read -d '' -r ARG; do
CMD+=("$ARG")
done < <(build_command "$@")
COUNT=${#CMD[@]}
LAST=$((COUNT - 1))
LAUNCHER_EXIT_CODE=${CMD[$LAST]}
# Certain JVM failures result in errors being printed to stdout (instead of stderr), which causes
# the code that parses the output of the launcher to get confused. In those cases, check if the
# exit code is an integer, and if it's not, handle it as a special error case.
if ! [[ $LAUNCHER_EXIT_CODE =~ ^[0-9]+$ ]]; then
echo "${CMD[@]}" | head -n-1 1>&2
exit 1
fi
if [ $LAUNCHER_EXIT_CODE != 0 ]; then
exit $LAUNCHER_EXIT_CODE
fi
CMD=("${CMD[@]:0:$LAST}")
exec "${CMD[@]}"
|
查看SparkSubmit
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
object SparkSubmit {
private val YARN = 1
private val STANDALONE = 2
private val MESOS = 4
private val LOCAL = 8
private val ALL_CLUSTER_MGRS = YARN | STANDALONE | MESOS | LOCAL
private val CLIENT = 1
private val CLUSTER = 2
private val ALL_DEPLOY_MODES = CLIENT | CLUSTER
private val SPARK_SHELL = "spark-shell"
private val PYSPARK_SHELL = "pyspark-shell"
private val SPARKR_SHELL = "sparkr-shell"
private val SPARKR_PACKAGE_ARCHIVE = "sparkr.zip"
private val R_PACKAGE_ARCHIVE = "rpkg.zip"
private val CLASS_NOT_FOUND_EXIT_STATUS = 101
private[spark] var exitFn: Int => Unit = (exitCode: Int) => System.exit(exitCode)
private[spark] var printStream: PrintStream = System.err
private[spark] def printWarning(str: String): Unit = printStream.println("Warning: " + str)
private[spark] def printErrorAndExit(str: String): Unit = {
printStream.println("Error: " + str)
printStream.println("Run with --help for usage help or --verbose for debug output")
exitFn(1)
}
private[spark] def printVersionAndExit(): Unit = {
printStream.println("""Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version %s
/_/
""".format(SPARK_VERSION))
printStream.println("Using Scala %s, %s, %s".format(
Properties.versionString, Properties.javaVmName, Properties.javaVersion))
printStream.println("Branch %s".format(SPARK_BRANCH))
printStream.println("Compiled by user %s on %s".format(SPARK_BUILD_USER, SPARK_BUILD_DATE))
printStream.println("Revision %s".format(SPARK_REVISION))
printStream.println("Url %s".format(SPARK_REPO_URL))
printStream.println("Type --help for more information.")
exitFn(0)
}
def main(args: Array[String]): Unit = {
val appArgs = new SparkSubmitArguments(args)
if (appArgs.verbose) {
printStream.println(appArgs)
}
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}
|
spark-shell
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
# Shell script for starting the Spark Shell REPL
cygwin=false
case "$(uname)" in
CYGWIN*) cygwin=true;;
esac
# Enter posix mode for bash
set -o posix
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
export _SPARK_CMD_USAGE="Usage: ./bin/spark-shell [options]"
# SPARK-4161: scala does not assume use of the java classpath,
# so we need to add the "-Dscala.usejavacp=true" flag manually. We
# do this specifically for the Spark shell because the scala REPL
# has its own class loader, and any additional classpath specified
# through spark.driver.extraClassPath is not automatically propagated.
SPARK_SUBMIT_OPTS="$SPARK_SUBMIT_OPTS -Dscala.usejavacp=true"
function main() {
if $cygwin; then
# Workaround for issue involving JLine and Cygwin
# (see http://sourceforge.net/p/jline/bugs/40/).
# If you're using the Mintty terminal emulator in Cygwin, may need to set the
# "Backspace sends ^H" setting in "Keys" section of the Mintty options
# (see https://github.com/sbt/sbt/issues/562).
stty -icanon min 1 -echo > /dev/null 2>&1
export SPARK_SUBMIT_OPTS="$SPARK_SUBMIT_OPTS -Djline.terminal=unix"
"${SPARK_HOME}"/bin/spark-submit --class org.apache.spark.repl.Main --name "Spark shell" "$@"
stty icanon echo > /dev/null 2>&1
else
export SPARK_SUBMIT_OPTS
"${SPARK_HOME}"/bin/spark-submit --class org.apache.spark.repl.Main --name "Spark shell" "$@"
fi
}
# Copy restore-TTY-on-exit functions from Scala script so spark-shell exits properly even in
# binary distribution of Spark where Scala is not installed
exit_status=127
saved_stty=""
# restore stty settings (echo in particular)
function restoreSttySettings() {
stty $saved_stty
saved_stty=""
}
function onExit() {
if [[ "$saved_stty" != "" ]]; then
restoreSttySettings
fi
exit $exit_status
}
# to reenable echo if we are interrupted before completing.
trap onExit INT
# save terminal settings
saved_stty=$(stty -g 2>/dev/null)
# clear on error so we don't later try to restore them
if [[ ! $? ]]; then
saved_stty=""
fi
main "$@" #调用的main函数 最终执行的依旧是spark-submi
# record the exit status lest it be overwritten:
# then reenable echo and propagate the code.
exit_status=$?
onExit
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
|
package org.apache.spark.repl
object Main extends Logging {
initializeLogIfNecessary(true)
Signaling.cancelOnInterrupt()
val conf = new SparkConf()
val rootDir = conf.getOption("spark.repl.classdir").getOrElse(Utils.getLocalDir(conf))
val outputDir = Utils.createTempDir(root = rootDir, namePrefix = "repl")
var sparkContext: SparkContext = _
var sparkSession: SparkSession = _
var interp: SparkILoop = _
private var hasErrors = false
private def scalaOptionError(msg: String): Unit = {
hasErrors = true
Console.err.println(msg)
}
def main(args: Array[String]) {
doMain(args, new SparkILoop)
}
private[repl] def doMain(args: Array[String], _interp: SparkILoop): Unit = {
interp = _interp
val jars = Utils.getUserJars(conf, isShell = true).mkString(File.pathSeparator)
val interpArguments = List(
"-Yrepl-class-based",
"-Yrepl-outdir", s"${outputDir.getAbsolutePath}",
"-classpath", jars
) ++ args.toList
val settings = new GenericRunnerSettings(scalaOptionError)
settings.processArguments(interpArguments, true)
if (!hasErrors) {
interp.process(settings)
Option(sparkContext).map(_.stop)
}
}
def createSparkSession(): SparkSession = {
val execUri = System.getenv("SPARK_EXECUTOR_URI")
conf.setIfMissing("spark.app.name", "Spark shell")
conf.set("spark.repl.class.outputDir", outputDir.getAbsolutePath())
if (execUri != null) {
conf.set("spark.executor.uri", execUri)
}
if (System.getenv("SPARK_HOME") != null) {
conf.setSparkHome(System.getenv("SPARK_HOME"))
}
val builder = SparkSession.builder.config(conf)
if (conf.get(CATALOG_IMPLEMENTATION.key, "hive").toLowerCase == "hive") {
if (SparkSession.hiveClassesArePresent) {
sparkSession = builder.enableHiveSupport().getOrCreate()
logInfo("Created Spark session with Hive support")
} else {
builder.config(CATALOG_IMPLEMENTATION.key, "in-memory")
sparkSession = builder.getOrCreate()
logInfo("Created Spark session")
}
} else {
sparkSession = builder.getOrCreate()
logInfo("Created Spark session")
}
sparkContext = sparkSession.sparkContext
sparkSession
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
|
private[repl] trait SparkILoopInit {
self: SparkILoop =>
def printWelcome() {
echo("""Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version %s
/_/
""".format(SPARK_VERSION))
import Properties._
val welcomeMsg = "Using Scala %s (%s, Java %s)".format(
versionString, javaVmName, javaVersion)
echo(welcomeMsg)
echo("Type in expressions to have them evaluated.")
echo("Type :help for more information.")
}
protected def asyncMessage(msg: String) {
if (isReplInfo || isReplPower)
echoAndRefresh(msg)
}
private val initLock = new java.util.concurrent.locks.ReentrantLock()
private val initCompilerCondition = initLock.newCondition()
private val initLoopCondition = initLock.newCondition()
private val initStart = System.nanoTime
private def withLock[T](body: => T): T = {
initLock.lock()
try body
finally initLock.unlock()
}
@volatile private var initIsComplete = false
@volatile private var initError: String = null
private def elapsed() = "%.3f".format((System.nanoTime - initStart).toDouble / 1000000000L)
protected def initializedCallback() = withLock(initCompilerCondition.signal())
protected def createAsyncListener() = {
io.spawn {
withLock(initCompilerCondition.await())
asyncMessage("[info] compiler init time: " + elapsed() + " s.")
postInitialization()
}
}
protected def awaitInitialized(): Boolean = {
if (!initIsComplete)
withLock { while (!initIsComplete) initLoopCondition.await() }
if (initError != null) {
println("""
|Failed to initialize the REPL due to an unexpected error.
|This is a bug, please, report it along with the error diagnostics printed below.
|%s.""".stripMargin.format(initError)
)
false
} else true
}
protected def postInitThunks = List[Option[() => Unit]](
Some(intp.setContextClassLoader _),
if (isReplPower) Some(() => enablePowerMode(true)) else None
).flatten
protected def postInitialization() {
try {
postInitThunks foreach (f => addThunk(f()))
runThunks()
} catch {
case ex: Throwable =>
initError = stackTraceString(ex)
throw ex
} finally {
initIsComplete = true
if (isAsync) {
asyncMessage("[info] total init time: " + elapsed() + " s.")
withLock(initLoopCondition.signal())
}
}
}
def initializeSpark() {
intp.beQuietDuring {
command("""
@transient val spark = org.apache.spark.repl.Main.interp.createSparkSession()
@transient val sc = {
val _sc = spark.sparkContext
if (_sc.getConf.getBoolean("spark.ui.reverseProxy", false)) {
val proxyUrl = _sc.getConf.get("spark.ui.reverseProxyUrl", null)
if (proxyUrl != null) {
println(s"Spark Context Web UI is available at ${proxyUrl}/proxy/${_sc.applicationId}")
} else {
println(s"Spark Context Web UI is available at Spark Master Public URL")
}
} else {
_sc.uiWebUrl.foreach {
webUrl => println(s"Spark context Web UI available at ${webUrl}")
}
}
println("Spark context available as 'sc' " +
s"(master = ${_sc.master}, app id = ${_sc.applicationId}).")
println("Spark session available as 'spark'.")
_sc
}
""")
command("import org.apache.spark.SparkContext._")
command("import spark.implicits._")
command("import spark.sql")
command("import org.apache.spark.sql.functions._")
}
}
private var pendingThunks: List[() => Unit] = Nil
protected def addThunk(body: => Unit) = synchronized {
pendingThunks :+= (() => body)
}
protected def runThunks(): Unit = synchronized {
if (pendingThunks.nonEmpty)
logDebug("Clearing " + pendingThunks.size + " thunks.")
while (pendingThunks.nonEmpty) {
val thunk = pendingThunks.head
pendingThunks = pendingThunks.tail
thunk()
}
}
}
|