Explainable AI 可解释的人工智能----李宏毅教授机器学习课程笔记四
可解释的人工智能
课程视频地址
文章目录
- 1 引言
- 为啥需要可解释呢?
- 模型可解释v.s模型强大
- 2 Local Explanation--Explain the decision
- 思路
- 方法一
- 方法二***
- 梯度方法存在的问题
- Explanation技术也可能被恶意攻击
- 实际例子
- 3 Global Explanation——Explain the whole model
- 思路
- 需要加约束
- 用生成器来替换上面的约束
- 4 Using a model to explain another
- 用线性模型来模拟黑盒
- LIME原理
- LIME步骤***
- 用决策树来模拟黑盒
- 一个方法
1 引言
先大概总结一下~~~~主要是三部分内容:
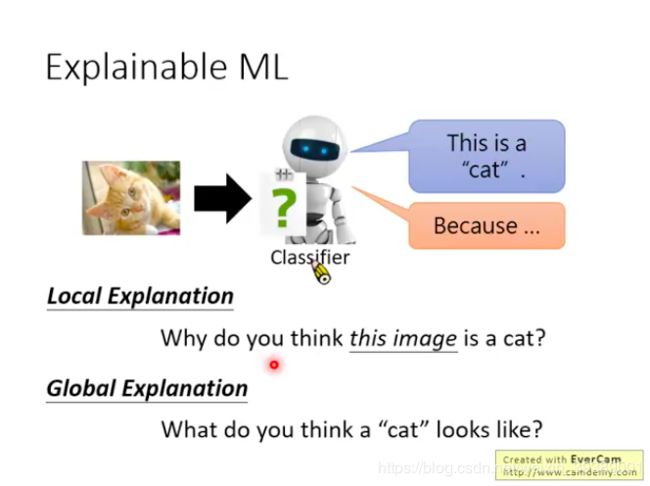
- 1)对输入图像进行分析,解释黑盒的AI模型是通过对输入图像的哪一部分进行判断,从而得到输出结果的。输入图像的哪些区域改变,对输出分类结果的影响较大。------对应下面图中的Local ExplanationWhy do you think this image is a cat?
- 2)对黑盒AI模型进行反推,来解释模型学到的东西。即对于特定的某一类输出(比如狗狗),AI究竟认为什么样的图像就是猫咪,那就把这个图像生成出来解释给你看咯。需要用到生成算法。(我觉得这种挺像人类的学习,就是看了很多狗狗的图片,然后我已经认识什么是狗狗了,但是如果你问我什么是狗狗,我可能很难跟你描述出来,但是我可以按照自己的理解给你画很多张狗狗图片,告诉你这些就是我知道的狗狗啦,反正就大概长这种样子的小动物嘛。)------对应下面图中的Global ExplanationWhat do you think a “cat” looks like?
- 3) 用一种可解释的模型来近似这个难解释的AI模型。AI模型是高度非线性的模型,黑盒,难解释。线性模型是简单的白盒模型,很容易解释,但是表征能力很弱,不能表征复杂问题。决策树如果不是很大的话,是一种容易解释的,表征能力也还不错的模型哦。所以就是两种研究轨迹:用线性模型来近似AI模型的局部,从而可以解释AI模型;用决策树来近似AI模型(需要限制决策树的复杂程度),从而可以解释AI模型。
为啥需要可解释呢?
- 生活中太多地方需要了:比如用ML来判读简历,需要提供为什么选择这个应聘者不选择那个应聘者,是依据这个人的哪些特征,这些信息需要反馈给招聘方。并不是机器学习模型在测试集合的精度越高,就真的越好用,因为不能确定机器到底是不是学到了真正的知识~~~如果并没有学到真正的知识,那在很多实际场合我们是不敢使用的呢。如果能解释的合理,人们才会觉得这个模型可以实用哦。
- 借助可解释性,能获得更好的ML模型。

模型可解释v.s模型强大
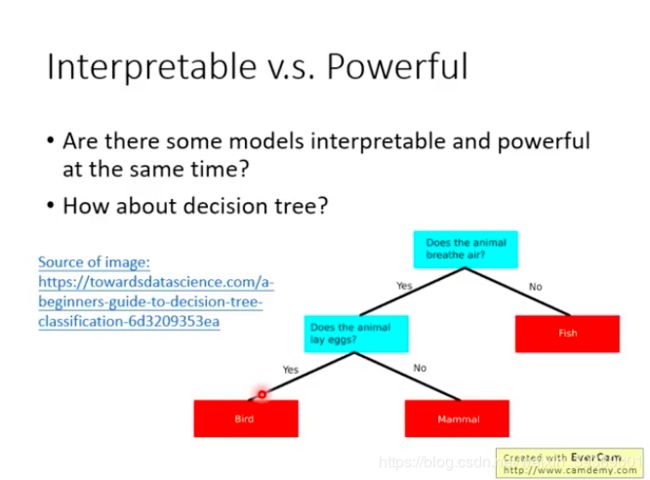
有些模型好解释,但是不够powerful。比如线性模型。
深度学习模型难解释,但是非常powerful。

有没有又好解释又powerful的模型呢?
决策树咯,但是只是简单的决策树好解释,如果决策树很复杂依然难解释。而且现在很多时候用的是决策森林,更加难解释了。

2 Local Explanation–Explain the decision
Why do you think this image is a cat?
思路
把输入拆分成很多的component,改变其中的一个component,看看哪个component的改变会引起模型决策的改变,那么这个component就是重要的component。

方法一
一个简单的方法
把输入图片用一个灰色方块挡住一部分,输入模型进行判断,移动这个灰色方块,最终得到灰色方块挡住哪一部分会导致模型判断错误。比如下图蓝色部分,就是灰色方块挡住这一部分时候,模型判断错误率很高,那么这部分区域就是模型判断的主要依据。
问题:如何选择灰色方块的大小很关键。太小—比如一个一个像素的改变,那方块在哪里应该都不重要,模型都应该不会判错啦;太大—可能改变每个位置都会导致模型判错。。。
为什么选择灰色方块?–也是需要自己来选择的~~~
当你选择不同参数时候,会得到不同的解释结果哦!!!

方法二***
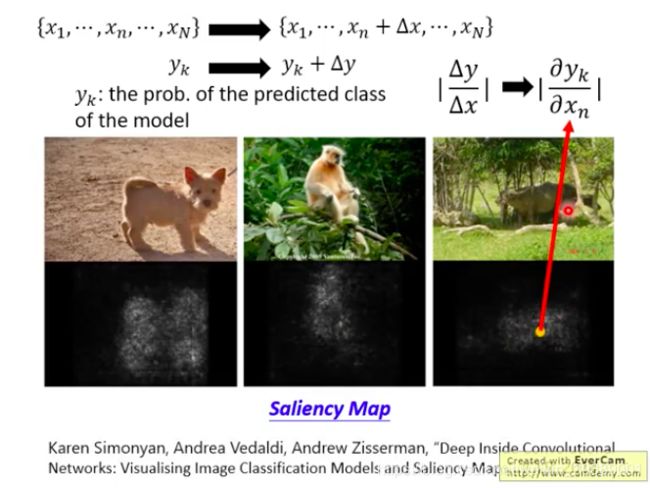
另外一个方法——基于Gradient
对每个pixel进行一个 Δ x \Delta x Δx的扰动,输出 y k y_k yk是预测为类别 k k k的概率,也会有一个 Δ y \Delta y Δy的改变,看看小小的扰动对输出有多大影响。其实就是看偏导数咯。有了每个pixel的偏导数,就可以画一个Saliency Map。每个点的亮度就是偏微分的绝对值,亮度越大说明偏微分的数值越大,也就是越重要的像素位置咯!
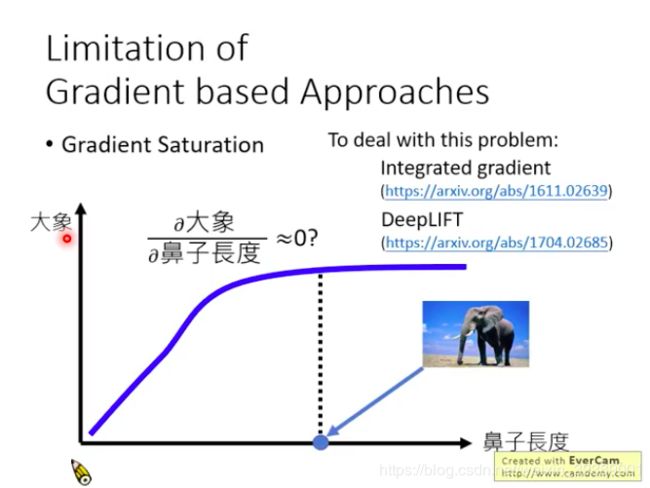
梯度方法存在的问题
梯度可能饱和,比如判断一张图片是不是大象,对于大象鼻子长度这个因素,可能当图片中鼻子长度达到某一个值之后,都会判断为大象了,也就是输出是大象的概率很高而且不怎么改变了,这时输出对鼻子长度求偏导数,结果就很小,那么就可能判断为:鼻子长度对于图片是不是大象的判断是没有很大影响的。显然这一解释是不合理的。两个文献给出了解决办法。
(弹幕说:鼻子再长就判断为蛇了。。。。哈哈哈哈哈哈哈)
我觉得这个很像对抗样本攻击,哪部分做小小的变动可以让输出变动比较大呢~~~
Explanation技术也可能被恶意攻击
本来得到的Saliency map挺好呀,就是目标区域对于判断结果很重要;但是这种解释方法也可能被攻击,比如在图片上进行一些小小的噪声扰动,导致解释的结果就变了呢!

实际例子
一个ML模型 判断是宝可梦还是数码宝贝。
这个模型的Training Accuracy是98.9%
Testing Accuracy是98.4%。
看似很棒
用Saliency Map看了一下-----怎么重要的地方没有落在动物身上耶??


原来。。。宝可梦的图片都是png的,数码宝贝的图片都是jepg的,这个模型学到的是根据背景来判断OMG!

3 Global Explanation——Explain the whole model
What do you think a “cat” looks like?
机器对于某一类别的认知是什么?机器认为的最像某一类别的图片长什么样子?是不是和我们认为的一样呢?
思路
当模型输出某一类别的可能的概率值最大时候,输入长什么样子?
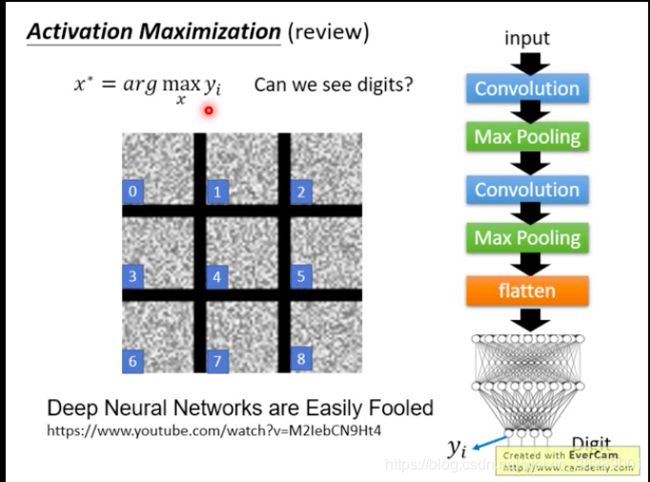
比如一个模型是手写数字识别的,假设 y i y_i yi就是输出是数字5的概率,那么如果我们来解这个优化问题 x ∗ = a r g m a x x y i x^* = arg max _x y_i x∗=argmaxxyi,得到的图片就是模型认为最像5的图片的样子咯?
结果我们得到了一堆噪声。。。这也是因为ML模型很容易被欺骗。。。
需要加约束
需要增加一个约束,使得生成的图片不仅使得 y i y_i yi最大,还要像一个手写数字。比如可以选择下图所示的约束 R ( x ) R(x) R(x),因为手写数字图片应该是大部分地方都没有数值,只有少部分pixel是有值的。这个约束可以自己设计。

像下图这种结果,需要精心设计一些约束,并且要爆调一波参数才能得到的。。。

用生成器来替换上面的约束
首先训练一个图像生成器(可以采用各种生成算法,比如VAE,GAN),能够输入随机的向量 z z z,生成很多类别的图片 x = G ( z ) x=G(z) x=G(z),把这个生成器和待解释图像分类模型串起来,那么原来最大化 y i y_i yi优化 x x x,变成了最大化 y i y_i yi,优化 z z z。可以采用梯度下降的算法,那么就得到了使得某个类别输出最大时候, z z z的值 z ∗ z^* z∗,相应的图片很容易通过 x ∗ = G ( z ∗ ) x^*=G(z^*) x∗=G(z∗)得到了。其实就是把上面加入的约束替换成了一个生成器。生成器能够保证生成的图像是我们想要的很多类型的图像中的某一张图。

注意:这里面的G和分类器都是已有的,固定的。就是调整输入啦~~~
下图是文献中取得的较好的结果,这些生成的图像就是ML模型认为某一个类别的图像应该长什么样子。

4 Using a model to explain another
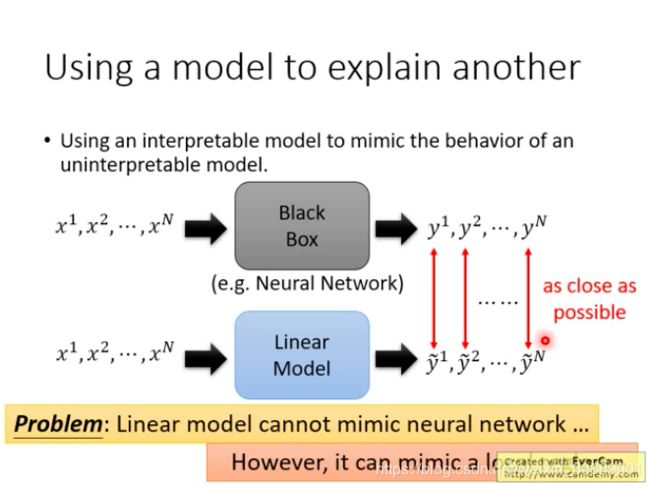
一些模型容易解释,用容易解释的模型来模拟黑盒模型的行为,从而解释黑盒模型。
用线性模型来模拟黑盒
用一个模型模拟黑盒的输入输出
但是线性模型能力不够,无法模拟高非线性的黑盒网络。
不过可以模拟局部特性哦。
LIME原理
很直观,相当于局部线性化
但是如何选择这个附近的大小,会影响最终解释的结果。
有很多参数要调。。。。。。。

LIME步骤***
实施步骤
- 首先选择一张图片,作为要解释的数据点
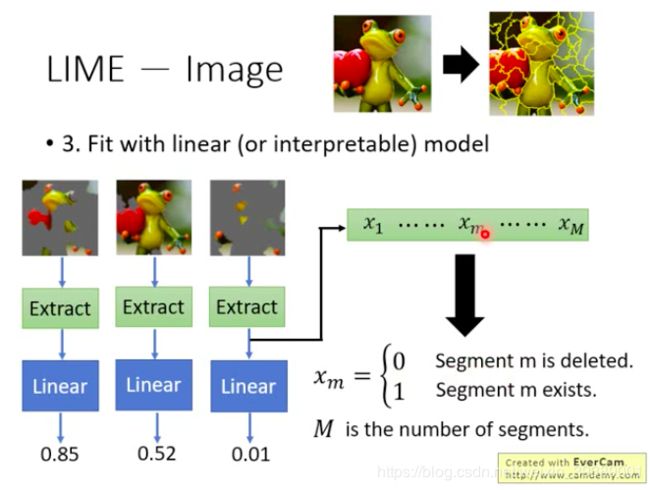
- 然后定义一种nearby并在图片的nearby采样。比如可以把图像进行segmentation,然后随机丢掉一些segment,就认为是这个图片周围的一些点咯。把这些周围的点(随机丢掉了segment的图像)输入我们要分析的黑盒子,得到了输出的结果。

- 用上面得到的输入输出来训练一个线性模型。
注意:
直接用线性模型的话,输入参数量太多,还是要做一些设计。比如把图像先extract成一些低维度的向量,再输入线性模型。
下图给出了一种extract的方法,原来图像的pixel维度很高,extract之后变成了 M M M维的向量,长度 M M M就取决于图像划分成的segment的数量。取值是0或者1,如果这个图像的第 m m m个segment被删除了就取0,否则就是1。
M是要被调整的参数哦~~~
- 对学到的线性模型进行解释。
根据线性模型的权重即可。

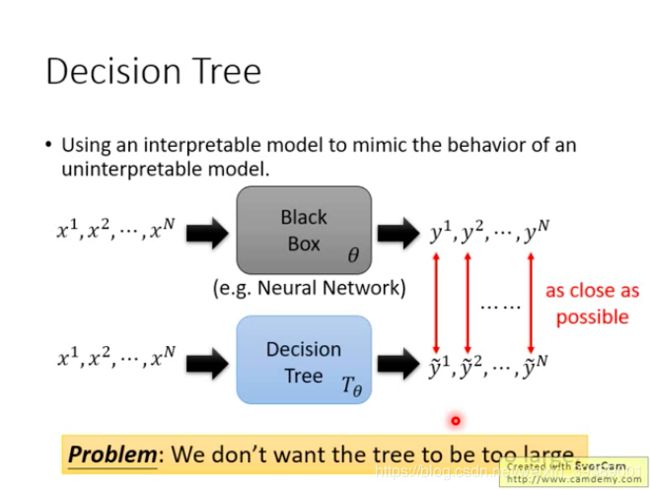
用决策树来模拟黑盒
决策树可能能够完全模拟黑盒,但是会使得决策树很深,也变得很难解释~~~
我们希望能用一个不那么复杂的决策树来模拟黑盒。
用 O ( T θ ) O(T_\theta) O(Tθ)表示决策树的复杂程度,我们希望复杂程度越低越好。复杂程度可以很多定义,比如可以用决策树的平均深度。
一个方法
训练一个网络,这个网络在训练时候就要考虑到它会被一个决策树来模拟。
一般的训练网络,就是最小化loss function L ( θ ) L(\theta) L(θ)
这时候要加上一个约束,就是转化成决策树后,决策树的复杂度越小越好。(tree regularization)
但是第二项不能微分
如何用梯度下降法??
文献训练了另一个神奇的网络,可以输出一个数值,这个数值就是预测决策树的平均深度…
