python应用:使用jupyter做数据分析与挖掘
最近在用anaconda自带的编辑器jupyter恶补数据分析,发现还蛮好用的。当在这里做做记录和学习总结,持续更新,希望大家讨论一二:

关于jupyter的快捷键这是我用的最多的几个。
ESC进入命令模式:
- Shift-Enter : 运行本单元,选中下个单元
- Ctrl-Enter : 运行本单元
- 1 : 设定 1 级标题
- A : 在上方插入新单元
- B : 在下方插入新单元
- D,D : 删除选中的单元
- Shift-M : 合并选中的单元
编辑模式就没什么好说的了,很普通。
操作就是直接在anaconda中打开jupyter输入代码即可。
(以下代码均可以直接使用,唯一需要修改的就是导入本地的excel表格那一行,建议直接放在桌面 :
位置:右键-属性-位置 复制 把“\”换成“/”即可)
一:数据关系
1.统计量分析
即最简单的标准差,数量,平均值,范围,变异系数(标准差/平均值)等数值的计算
# 回稳率统计
from __future__ import print_function #用于代码兼容
import pandas as pd #pandas 导入pandas库
rates = '' #输入数据(excel表格)所在位置
data = pd.read_excel(rates) #读取数据
statistics = data.describe() #保存基本统计量
statistics.loc['range'] = statistics.loc['max']-statistics.loc['min'] #极差
statistics.loc['var'] = statistics.loc['std']/statistics.loc['mean'] #变异系数
statistics.loc['dis'] = statistics.loc['75%']-statistics.loc['25%'] #四分位数间距
print(statistics)输出结果如下:

2.异常值分析
异常值即数据中存在不合理数据需要进行剔除,即箱模型上下界的数据,
代码如下:
import pandas as pd
example2 = 'C:/Users/chinaunicom/Desktop/例子2.xls' #导入数据,文件在桌面
data = pd.read_excel(example2, index_col = u'日期') #读取数据,指定“日期”列为索引列
import matplotlib.pyplot as plt #导入图像库
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.figure() #建立图像
p = data.boxplot(return_type='dict') #画箱线图,直接使用DataFrame的方法
x = p['fliers'][0].get_xdata() # 'flies'即为异常值的标签
y = p['fliers'][0].get_ydata()
y.sort() #从小到大排序,该方法直接改变原对象
#用annotate添加注释
#其中有些相近的点,注解会出现重叠,难以看清,需要一些技巧来控制。
#以下参数都是经过调试的,需要具体问题具体调试。
for i in range(len(x)):
if i>0:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.08,y[i]))
plt.show() #展示箱线图输入结果如下(箱模型):

上下界有7个数据需要进行剔除
3.贡献度分析
贡献度分析又称为帕累托分析,2/8定律。例如:对一个公司来讲,80%的利率来自于20%的最畅销产品,其他80%只产生20%的利润,如某个餐厅不同菜品的盈利贡献:

代码如下:
#-*- coding: utf-8 -*-
#菜品盈利数据 帕累托图
from __future__ import print_function
import pandas as pd
#初始化参数
dish_profit ='C:/Users/chinaunicom/Desktop/catering_dish_profit.xls' #餐饮菜品盈利数据
data = pd.read_excel(dish_profit, index_col = u'菜品名')
data = data[u'盈利'].copy()
data.sort_index(ascending = False)
import matplotlib.pyplot as plt #导入图像库
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.figure()
data.plot(kind='bar')
plt.ylabel(u'盈利(元)')
p = 1.0*data.cumsum()/data.sum()
p.plot(color = 'r', secondary_y = True, style = '-o',linewidth = 2)
plt.annotate(format(p[6], '.4%'), xy = (6, p[6]), xytext=(6*0.9, p[6]*0.9), arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=.2")) #添加注释,即85%处的标记。这里包括了指定箭头样式。
plt.ylabel(u'盈利(比例)')
plt.show()
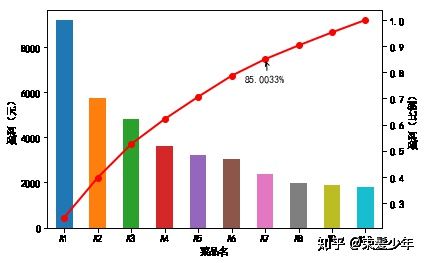
菜品名和盈利比例
4 相关性分析:
pearson:
相关性最主要的指标就是r
r<=0.3 不存在线性相关
0.3 r>0.8为高度线性相关 spearman秩相关: 两个变量具有严格单调的函数关系,就完全spearman相关,用r*2表示,0<=r*2<=1. 举例: 分析菜品销量之间的相关性可以得到不同菜品的联系,如互补菜品或者没有关系,为原材料采购提供参考 代码: #-*- coding: utf-8 -*- 结果如下: 百合酱蒸凤爪与其他菜品的相关性 1.数据缺失值进行插补 拉格朗日插值法: 代码如下: 插入缺失值4156.86 2.数据规范化 将数据按照比例进行缩放,是之落到一个特定的区域,如工资映射到[-1,1]或者[0,1] (1)最小-最大规范化:离查差标准化 公式如下:x*= x-min/max-min (2)零-均值规范化:标准差标准化 x*=x-x(平均值)/σ 是使用最多的数据标准化的方法 (3)小数定标志规范化 取决于属性绝对值的最大值 举例: 代码如下: #-*- coding: utf-8 -*- #数据规范化 输出结果如下: 3.连续属性离散化 将连续属性变换成分类属性,即连续属性离散化。 常用方法: (1)等宽法 (2)等频法 (3)基于聚类的分析方法 举例: 对医学中中医证型分别上述三种方法连续属性离散化,代码如下: 输出结果: 1等宽法 :将属性的值域分为具有相同宽度的区间 2等频法:将相同数量的记录放进每个区间 3 基于k-means一维聚类 4.属性构造 即利用已有的属性构造新的属性,如进行防窃漏电诊断建模时,已有属性包括供入电量和供出电量(即各大用户的用电之和理论上相等),但如果存在窃电行为,会使得供入电量明显大于供出电量,我们构造属性如下: 线损率 = (供入电量-供出电量)/供入电量 X100% 一般在3%-15%,如果超过该范围,则很可能存在漏电行为 代码如下: 输入如下: 其实用excel更容易,主要是构造属性的思维 有朋友说要原本文件的excel,那就分享一下... 链接:https://pan.baidu.com/s/1m92g8n5UdVBfuf70zCwtIw 提取码:90zo
#餐饮销量数据相关性分析
from __future__ import print_function
import pandas as pd
catering_sale = '../data/catering_sale_all.xls' #餐饮数据,含有其他属性
data = pd.read_excel(catering_sale, index_col = u'日期') #读取数据,指定“日期”列为索引列
data.corr() #相关系数矩阵,即给出了任意两款菜式之间的相关系数
data.corr()[u'百合酱蒸凤爪'] #只显示“百合酱蒸凤爪”与其他菜式的相关系数
data[u'百合酱蒸凤爪'].corr(data[u'翡翠蒸香茜饺']) #计算“百合酱蒸凤爪”与“翡翠蒸香茜饺”的相关系数
二:数据关系

#拉格朗日插值代码
import pandas as pd #导入数据分析库Pandas
from scipy.interpolate import lagrange #导入拉格朗日插值函数
inputfile = 'C:/Users/chinaunicom/Desktop/catering_sale.xls'
outputfile = 'C:/Users/chinaunicom/Desktop/catering.xls'
data = pd.read_excel(inputfile) #读入数据
data[u'销量'][(data[u'销量'] < 400) | (data[u'销量'] > 5000)] = None #过滤异常值,将其变为空值
#自定义列向量插值函数
#s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
def ployinterp_column(s, n, k=5):
y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] #取数
y = y[y.notnull()] #剔除空值
return lagrange(y.index, list(y))(n) #插值并返回插值结果
#逐个元素判断是否需要插值
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]: #如果为空即插值。
data[i][j] = ployinterp_column(data[i], j)
data.to_excel(outputfile) #输出结果,写入文件
x=x/10**k
import pandas as pd
import numpy as np
datafile = '../data/normalization_data.xls' #参数初始化
data = pd.read_excel(datafile, header = None) #读取数据
print((data - data.min())/(data.max() - data.min())) #最小-最大规范化
print((data - data.mean())/data.std()) #零-均值规范化
print(data/10**np.ceil(np.log10(data.abs().max()))) #小数定标规范化

#-*- coding: utf-8 -*-
#数据规范化
import pandas as pd
datafile = 'C:/Users/chinaunicom/Desktop/discretization_data.xls' #参数初始化
data = pd.read_excel(datafile) #读取数据
data = data[u'肝气郁结证型系数'].copy()
k = 4
d1 = pd.cut(data, k, labels = range(k)) #等宽离散化,各个类比依次命名为0,1,2,3
#等频率离散化
w = [1.0*i/k for i in range(k+1)]
w = data.describe(percentiles = w)[4:4+k+1] #使用describe函数自动计算分位数
w[0] = w[0]*(1-1e-10)
d2 = pd.cut(data, w, labels = range(k))
#一维聚类
from sklearn.cluster import KMeans #引入KMeans
kmodel = KMeans(n_clusters = k, n_jobs = 4) #建立模型,n_jobs是并行数,一般等于CPU数较好
kmodel.fit(data.values.reshape((len(data), 1))) #训练模型
c = pd.DataFrame(kmodel.cluster_centers_).sort_values(0) #输出聚类中心,并且排序(默认是随机序的)
w = c.rolling(2).mean().iloc[1:]#相比两项求中点,作为边界线
w = [0] + list(w[0]) + [data.max()] #把首末边界点加上
d3 = pd.cut(data, w, labels = range(k))
def cluster_plot(d, k): #自定义作图函数来显示聚类结果
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.figure(figsize = (8, 3))
for j in range(0, k):
plt.plot(data[d==j], [j for i in d[d==j]], 'o')
plt.ylim(-0.5, k-0.5)
return plt
cluster_plot(d1, k).show()
cluster_plot(d2, k).show()
cluster_plot(d3, k).show()



#折损率构造
import pandas as pd
#参数初始化
#文件输入路径
inputfile = "C:/Users/chinaunicom/Desktop/electricity_data.xls"
#文件输出路径
outputfile = "C:/Users/chinaunicom/Desktop/electricity_rate.xls"
# 读取数据
data = pd.read_excel(inputfile)
data[u'折损率'] = (data[u'供入电量']-data[u'供出电量'])/data[u'供入电量']
data.to_excel(outputfile,index = False)