Python之填充数据槽(二)
在之前的ipynb中,我们研究了这样的数据槽的填充方法,如:
1. Imputation methods - mean, median imputation
2. Interpolation methods - basic (linear, cubic, polynomial, spline)
3. Smoothing and filtering methods - moving average链式方程的多重推定(MICE)。
MICE是在对数据遗漏产生机制有一定假设的情况下,用于替换数据集缺失值的一种多重填充(推算)方法。
随机缺失(MAR)数据。
数据完全缺失是随机的(MCAR)。
与 "完整 "数据集的单一归因相比,使用多重归因可以解释现有的统计不确定性。一般来说,单项推算的局限性在于,由于这些方法找到的是最可能的数值,因此它们产生的记录不能准确反映基线数据的分布。此外,链式方程方法非常灵活,可以处理不同类型的变量(如连续或二进制)。
例如,考虑极端的情况,我们用一个平均值来代替遗漏值。事实上,我们会期望在填写跳过后的数据中看到一些变化:极端值、排放和记录不完全符合原始数据的 "模式"。所有的数据集都包含一些噪声,用平均值填充跳过并不试图模拟这种噪声。这就会导致所产生的估计值出现偏差,最终导致所产生的模型在准备阶段和质量控制阶段的准确性下降。
MICE算法的工作原理如下:在运行多个回归模型时,根据观察到的(未遗漏的)值,有条件地模拟每个遗漏值,这样可以考虑到基本的数据分布,消除偏移。
该算法包括三个步骤:
1.推算:我们填补数据的遗漏。在这种情况下,最好的方法是马尔科夫链蒙特卡洛(MCMC)模拟。
2. 分析:从推算数据中分析所研究的模型与各数据集。
3.汇集:将分析结果整合成最终结果。
算法的工作方案
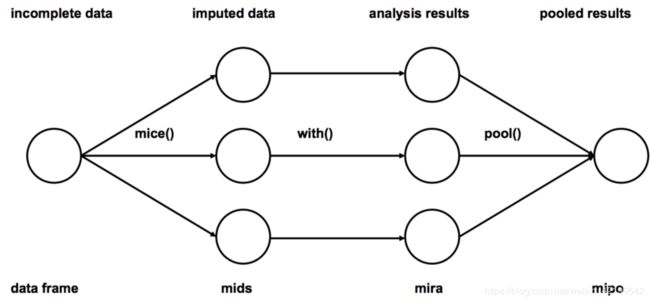
示例
import numpy as np
import pandas as pd输入数据:
data_without_nan = pd.read_csv(r'data\regdat1.csv', sep=';', index_col='DATE')随机插入的数据。
data = pd.read_csv(r'data\regdat1_with_nan.csv', sep=';', index_col='DATE')
data.head()
data.info()在数据中,我们看到了大量的遗漏值。让我们用fancyimpute fancyimpute包中的MICE方法来填充它们。
注意 在安装fancyimpute之前(pip install fancyimpute)更新所有包(pip, scipy, numpy, six, tensorflow)
from fancyimpute import IterativeImputer as MICE
df_complete = data.copy()
for column in data:
data_train_numeric = data[[column]].select_dtypes(include=[np.float]).as_matrix()
data_complete = MICE().fit_transform(data_train_numeric)
df_complete[column + '_complete'] = data_complete
df_complete[column + '_interpolated'] = data[column].interpolate(method='linear')df_complete.head()让我们利用MICE和简单的线性插值来估计数据中的通道填充质量。
from sklearn.metrics import r2_score
for column in data_without_nan:
r2_value_mice = r2_score(data_without_nan[column], df_complete[column + '_complete'])
print(column, 'data imputation has r2 score by MICE', r2_value_mice)
r2_value_interp = r2_score(data_without_nan[column], df_complete[column + '_interpolated'])
print(column, 'data imputation has r2 score by linear interpolation', r2_value_interp)
可以看出,在3种情况中,有2种情况下,MICE数据中的填充通道质量不如插值。
在一个真实的项目中,它绝对是类似的,在测试了大量的方法来填补遗漏的值后,停止在线性插值,作为最小的计算成本,但在同一时间给出了一个可接受的结果质量,填补数据中的通道(评估图形和模型的质量建立在数据的基础上,填补通道)。
接下来是...
我们将在以下主题中考虑平滑和过滤。
基于模型的方法----如果还有时间的话;
用ML方法填充通证,以及使用多任务学习(将带通证的数据直接提交给模型,填充通证与主任务同时进行),应该在你之前的课程中已经有过。
用于自学
fancyimpute包和其他方法来填补遗漏的值,例如。
KNN:最近邻推算,其中使用均值平方差对两行都有观测数据的特征进行加权。
SoftImpute:通过迭代软阈值的SVD分解矩阵。受R的softImpute包的启发,该包基于Mazumder等人的Spectral Regularization Algorithms for Learning Large Incomplete Matrices。
迭代SVD:通过迭代低阶SVD分解完成矩阵。应该类似于SVDimpute从缺失值估计方法的DNA微阵列由Troyanskaya等人。
MatrixFactorization:将不完全矩阵直接分解成低阶U和V,对U的元素进行L1稀疏性惩罚,对V的元素进行L2惩罚,用梯度下降法求解。
NuclearNormMinimization:Emmanuel Candes和Benjamin Recht使用cvxpy对精确矩阵完成的简单实现。对于大型矩阵来说太慢了。