Python——12306图片验证码
本次爬虫,我们来模拟一下12306的验证码验证
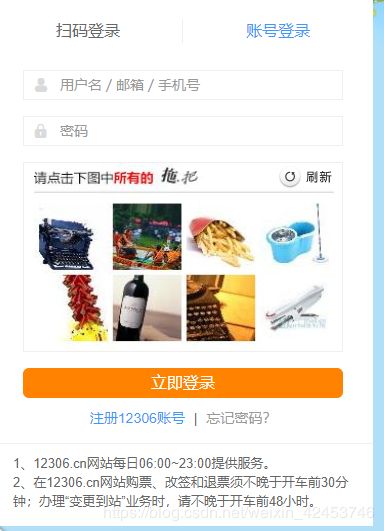
本次练习用到的模块:
- requests
- re
- base64
- urllib3
第一步,按F12查看验证码图片的信息:
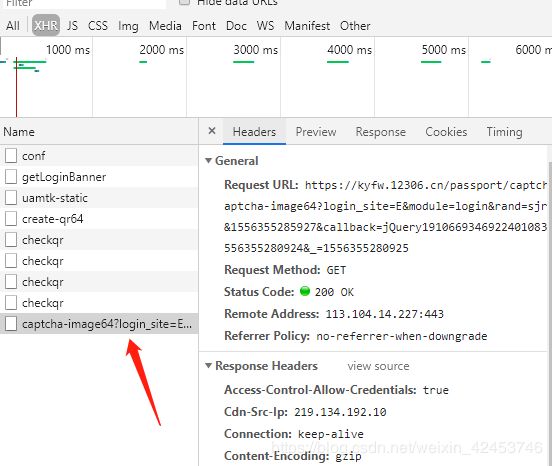
提取URL:https://kyfw.12306.cn/passport/captcha/captcha-image64 (后面的参数不要)
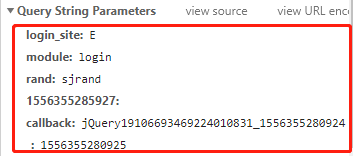
提取requests的params参数内容:
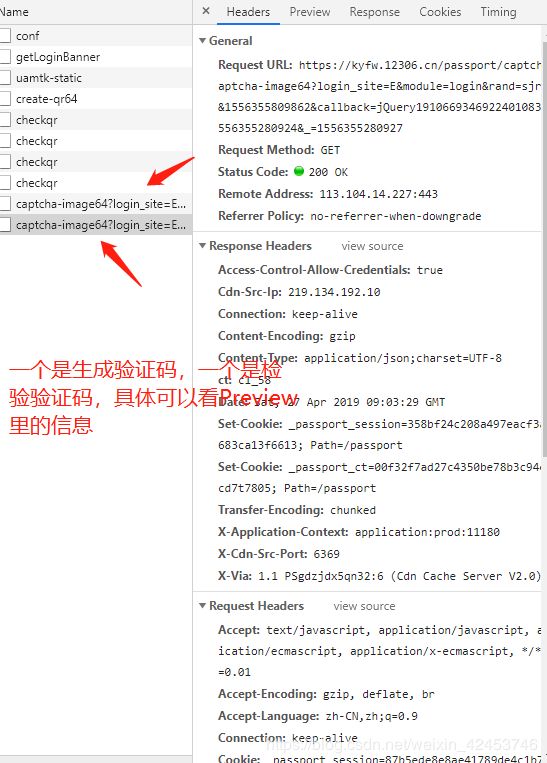
第二步,先获取验证码的图片:
#coding=utf-8
import requests
import re
import urllib3
import base64
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"}
params = {
"login_site": " E",
"module": "login",
"rand": "sjrand",
"1556350688384": "",
"callback": "jQuery1910650727092213933_1556350657738",
"_":" 1556350657741"
}
# 1. 创建
session对象, 设置相关信息
session = requests.Session()
session.headers = headers
session.params = params
# 2. 发送请求, 是session不用管cookies
resp = session.get(url="https://kyfw.12306.cn/passport/captcha/captcha-image64", verify=False)
# 3. 数据处理
b64_image = re.findall(r'{"image":"(.*?)",', resp.text, re.S)[0]
image_data = base64.b64decode(b64_image)
with open(r"ca.jpg", "wb") as f:
f.write(image_data)

第三步,坐标处理:
这是用来获取坐标的函数:
def position_count(args):
"""
1 2 3 4
5 6 7 8
:param args:
:return:
"""
position_dict = {
'1': '49,50',
'2': '106,50',
'3': '174,50',
'4': '240,50',
'5': '50,121',
'6': '120,120',
'7': '174,123',
'8': '240,125',
}
position_data = []
for i in args:
position_data.append(position_dict.get(i))
return ','.join(position_data)
在这里,我们要设置第二个params参数,传给检验验证码的url
# 4. 坐标整理
input_data = input("enter:") # 第几张图就输入几,空格分开
pic_num = input_data.split()
pix_num = position_count(pic_num)
params = {
"callback": "jQuery191014934245692777215_1556354228848",
"answer": pix_num, # answer是验证码的坐标
"rand": "sjrand",
"login_site": "E",
"_": "1556354228850",
}
第四步,发送check:
这里的URL是检验验证码的URL,不是生成验证码的URL(可手动验证一次获取)
# 5. 发送check
session.params = params
resp = session.get(url="https://kyfw.12306.cn/passport/captcha/captcha-check", verify=False)
print(resp.text)
结果:

代码整合:
#coding=utf-8
import requests
import re
import urllib3
import base64
# requests关闭证书验证会警告,加上这个可以关闭警告
urllib3.disable_warnings()
# 模拟点击验证图片
def position_count(args):
"""
1 2 3 4
5 6 7 8
:param args:
:return:
"""
# 这是图片的坐标,模拟点击用
position_dict = {
'1': '49,50',
'2': '106,50',
'3': '174,50',
'4': '240,50',
'5': '50,121',
'6': '120,120',
'7': '174,123',
'8': '240,125',
}
position_data = []
for i in args:
position_data.append(position_dict.get(i))
return ','.join(position_data)
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"}
params = {
"login_site": " E",
"module": "login",
"rand": "sjrand",
"1556350688384": "",
"callback": "jQuery1910650727092213933_1556350657738",
"_":" 1556350657741"
}
# 1. 创建session对象, 设置相关信息
session = requests.Session()
session.headers = headers
session.params = params
# 2. 发送请求, 是session不用管cookies
resp = session.get(url="https://kyfw.12306.cn/passport/captcha/captcha-image64", verify=False)
# 3. 数据处理
b64_image = re.findall(r'{"image":"(.*?)",', resp.text, re.S)[0]
image_data = base64.b64decode(b64_image)
with open(r"ca.jpg", "wb") as f:
f.write(image_data)
# 4. 坐标整理
input_data = input("enter:")
pic_num = input_data.split()
pix_num = position_count(pic_num)
params = {
"callback": "jQuery191014934245692777215_1556354228848",
"answer": pix_num,
"rand": "sjrand",
"login_site": "E",
"_": "1556354228850",
}
# 5. 发送check
session.params = params
resp = session.get(url="https://kyfw.12306.cn/passport/captcha/captcha-check", verify=False)
print(resp.text)
END
您的支持,是我前进的动力!