python3爬虫基础三(爬取js文件)
有时候我们要爬取的信息不是通过css文件编写而是在js文件中,所以我们之前的爬虫方法就无法爬取我们想要的信息
现在我们以拉勾网为例,爬取js文件信息
第一步打开拉勾网,搜索python
页面如下:
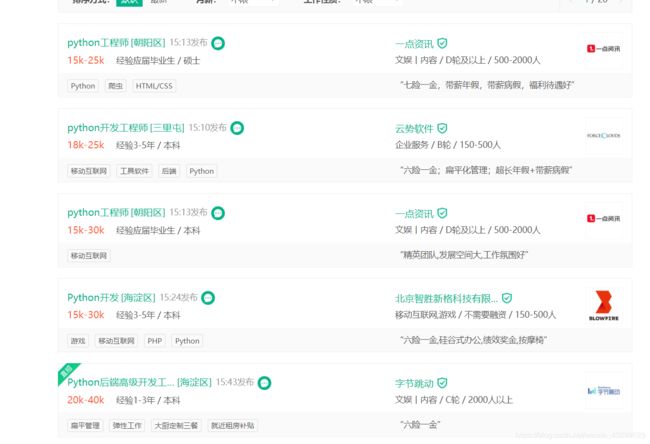
第二步,右键点击检查
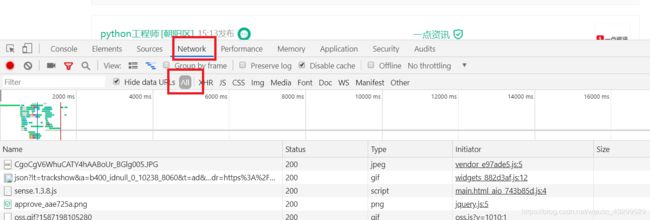
然后找到positionAjax.json文件,文件右侧就是我们要爬取的内容

在浏览器中打开json.cn网页,将json文件右侧的内容全部复制到json.cn左侧,就可以看到我们要爬取的内容

第三步爬取json文件信息
在json文件的请求头中我们可以看到请求的Method是POST,请求的data内容,然后编写代码


from urllib import request
url = "https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput="
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
}
data = {
'first':'true',
'pn':1,
'kd':'python'
}
req = request.Request(url,headers = headers,data=data,method='POST')
resp =request.urlopen(req)
print(resp.read())
会出现报错信息:
TypeError: can't concat str to bytes
原因:data需要进行encode
修改代码:
from urllib import request,parse
data = {
'first':'true',
'pn':1,
'kd':'python'
}
req = request.Request(url,headers = headers,data=parse.urlencode(data),method='POST')
print(resp.read())
运行时又出现错误
TypeError: POST data should be bytes, an iterable of bytes, or a file object. It cannot be of type str.
表示POST方法的数据应该为bytes,即经过编码的数据(二进制),在python3中默认字符串为Unicode,需要对其进行编码为utf-8格式
代码为:
from urllib import request,parse
url = "https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput="
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
}
data = {
'first':'true',
'pn':1,
'kd':'python'
}
req = request.Request(url,headers = headers,data=parse.urlencode(data).encode('utf-8'),method='POST')
resp =request.urlopen(req)
print(resp.read())
结果为:
b'\n\n\n \n \n\n\n\n\n\n\n\n
如果你得到操作太频繁警告,说明浏览器已经意识到我们是在爬虫,所以我们要伪装的好一点,可以把我们访问网页的cookie信息和referer内容复制到我们的代码header中,就不会出现警告了

![]()