微软自动调参工具—NNI—安装与使用教程(附错误解决)
简介
NNI是微软的开源自动调参的工具。人工调参实在是太麻烦了,最近试了下水,感觉还不错,能在帮你调参的同时,把可视化的工作一起给做了,简单明了。然后感觉很多博客写的并不是很明白,所以打算自己补充一下。如果觉得解决了你的一些问题,请收藏关注。
本文分为以下两个部分:
- 如何安装并使用NNI
- 调试经验 & 错误汇总
第一步:安装
nni的安装十分简单。通过pip命令就可以安装了。并且提供了example供参考学习。
先决条件:tensorflow,python >= 3.5,
# 安装nni
python3 -m pip install --upgrade nni
# 示例程序,用于学习
git clone https://github.com/Microsoft/nni.git
# 如果想运行这个示例程序,需要安装tensorflow
python3 -m pip install tensorflow
第二步:设置超参数的搜索范围
我们打开NNI的示例程序先来观摩一下
cd ./nni/examples/trials/mnist/
可以看到目录中有 config.yml, mnist.py ,search_space.json 三个文件,这三个文件分别决定了我们的NNI配置文件,main.py和超参数搜索空间。
1.打开 search_space.json文件
{
"dropout_rate":{"_type":"uniform","_value":[0.5, 0.9]},
"conv_size":{"_type":"choice","_value":[2,3,5,7]},
"hidden_size":{"_type":"choice","_value":[124, 512, 1024]},
"batch_size": {"_type":"choice", "_value": [1, 4, 8, 16, 32]},
"learning_rate":{"_type":"choice","_value":[0.0001, 0.001, 0.01, 0.1]}
}
在这里可以定义我们的超参数和搜索范围,可以根据自己的需要随意调整。
搜索的类型有很多种,常用的有uniform,choice等。
但是因为这个example只写了uniform和choice的用法,所以很多其他博客只介绍了choice和uniform的用法,在这里进行补充。详细内容见NNI的github帮助文档
{"_type": "choice", "_value": options}
# dropout_rate":{"_type":"uniform","_value":[0.5, 0.9]}的结果为0.5或者0.9
{"_type": "uniform", "_value": [low, high]}
# 变量是 low 和 high 之间均匀分布的值。
# 当优化时,此变量值会在两侧区间内。
{"_type": "quniform", "_value": [low, high, q]}
# 从low开始到high结束,步长为q。
# 比如{"_type": "quniform", "_value": [0, 10, 2]}的结果为0,2,4,6,8,10
{"_type": "normal", "_value": [mu, sigma]}
# 变量值为实数,且为正态分布,均值为 mu,标准方差为 sigma。 优化时,此变量不受约束。
{"_type": "randint", "_value": [lower, upper]}
# 从 lower (包含) 到 upper (不包含) 中选择一个随机整数。
第二步:配置config.yaml
打开config.yaml
authorName: default
experimentName: example_mnist
trialConcurrency: 1
maxExecDuration: 1h
maxTrialNum: 10
#choice: local, remote, pai
trainingServicePlatform: local
searchSpacePath: search_space.json
#choice: true, false
useAnnotation: false
tuner:
#choice: TPE, Random, Anneal, Evolution, BatchTuner, MetisTuner, GPTuner
#SMAC (SMAC should be installed through nnictl)
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
trial:
command: python3 mnist.py
codeDir: .
gpuNum: 0
除了command,maxExecDuration,trialConcurrency,gpuNum,optimize_mode需要更改,这里的参数一般不需要更改。
-
command是nni的运行后将要执行的指令,mnist.py改为你的main.py或者train.py等等主程序。
-
maxExecDuration是整个NNI自动调参的时间,注意不是一次训练的时间(我一开始就理解成了一次训练所需要的最大时间),假如你用一个gpu跑,要训练10种不同的参数,每次训练都要2小时,这个值就设置为20h
-
trialConcurrency是trail的并发数,这个需要根据自己的GPU数量设置,而不是下面的gpuNum!!!为什么呢,因为一个trail代表一次调参的过程,理解为用一种超参数在运行你的train.py,并发数设为x,就有x个trainer在训练!
-
gpuNum是每个trail所需要的gpu个数,而不是整个nni调参所需要的gpu个数。对于大型任务,单独训练一次需要N个GPU的话,这个值就设置为N;如果单次训练,一个GPU就足够,请把这个值设置为1;没有GPU?我要写个惨字…
所以你最后需要的GPU总数为trialConcurrency*gpuNum,即 trail的个数*每个trail需要的gpu个数
- optimize_mode对应着优化的方向,有最大和最小两种方式,具体如何设置在下一步中提到。
一般来说这里的配置已经足够。
如果需要调节网格搜索的算法等等更细节的东西,请参考NNI的github帮助文档
第三步 修改我们的代码
# 引入nni
import nni
"""
设置参数自动更新,假设params 是我们的默认参数
注意params是**字典**类型的变量
"""
params = vars(get_params())
tuner_params= nni.get_next_parameter() # 这会获得一组搜索空间中的参数
params.update(tuner_params)
"""
向nni报告我们的结果
如果test_acc是准确率,那第二步(5)optimize_mode就选maximize。如果这里的test_acc如果是loss,
那第二步(5)optimize_mode就选minimize,也可以填其他训练的指标
另外这里的报告结果都是数字,一般选择float类型
"""
nni.report_intermediate_result(test_acc)
'''
report_intermediate_result是汇报中间结果,一般可以设置每个epoch报告一次
'''
nni.report_final_result(best_acc)
'''
report_final_result是汇报最终结果,可以是last_acc,也可以设置为报告best_acc
'''
很多体验者说report_intermediate_result汇报loss,report_final_result汇报精确度,这种说法是错的。
这两个report的内容应该是一个意义的(都是loss or 都是准确度 or 其他)
原因下面会讲到
第四步 两行代码直接运行
cd ./YourCode_dir
nnictl create --config config.yml -p 8888
切换到代码的目录下,直接运行。
-p代表使用的端口号。注意如果代码使用的是conda虚拟环境,需要激活conda虚拟环境。
第五步 查看训练过程
相信此刻你应该看到了succes的字样,别兴奋,这并不代表成功开始调参了,反正我是不知道多少次才成功。
打开命令行给的网站,如下图,点开Trail Detial->Intermediate result

如果你打开的太快,应该是WATING的状态。别急,稍等一会儿就开始RUNNING了。如果直接Fail了,请检查你的代码。
如果report_intermediate_result是每一个epoch report一次,那么跑完一个epoch过后会看到有Default metric,后面加了个括号(LATEST),这个时候基本就大工告成了,恭喜你!
如果report_final_result是训练结束时report,那么等训练结束后会有Default metric(FINAL)的数值。
所以这说明了report_intermediate_result和report_final_result其实都是Default metric,是一个意义的衡量指标,都用于衡量模型的好坏。
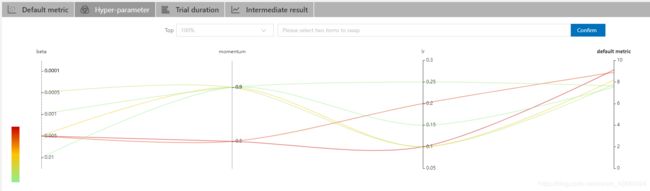
下图是超参数曲线,其实从上图可以看出来我刚始调参不久,只有几个trail是SUCCEED的。不过我想说,在这种条件下!!这个曲线也太美了吧!!!
第六步 停止
在你不想继续搜寻超参数的时候,可以使用nnictl stop停止自动调参。
但是这只是说不会开始下一个trail了,没有运行完的trail依然会继续执行。如果想终止trail可以用nvidia-smi中找到训练进程的PID,然后用kill -9 PID杀死进程
常见的坑
本人比较菜,nni其实很简单但是折腾了很久。这里把我走过的坑分享给大家,让大家少走弯路。
1.你的参数应该是个字典,比如args['batch_size']而非args.batch_size
因为nni.get_next_parameter()获取到的是一个字典,并且对于params使用的是字典的update方法params.update(tuner_params),所以params应该是字典格式的,使用params['batch_size']
2. Fail了怎么办?
我一开始也fail了很多次(nni启动成功,打开网站也RUNNING了,但是没跑完一个epoch就FAILED了)。这种情况,建议把以下三行代码nni.get_next_parameter(), nni.report_final_result(), nni.report_intermediate_result()都注释掉,然后跑一下程序看看有没有bug。这也是调试程序的重要手段! 没有bug的话,就看看report的值是不是数字。report的必须是数字,不是tensor等其他变量。另外还需要看看GPU可不可用,如果GPU内存不够,就会报错。
3.一直都在Waiting
nni启动了,但是一直WATING,可能是你的config.yaml配置错了,参照第二步,好好检查下gpuNum和trialConcurrency的值正确不,实在不行就都填写1。另外,nvidia-smi看看你的GPU使用情况,如果 第六步的停止只是stop,没有kill进程,你的GPU可能还在跑之前的trail。
4. train detail没有result
程序一直在跑,早该跑完一个epoch了但是网页中没有数值显示?检查report函数,report的必须是数字,不是tensor等其他变量
5.网页打不开
如果用的是Linux远程GPU服务器,本地打不开网页,怎么办?别慌,可以重定向。在本地命令行输入
ssh -p ,
remote_port是服务器端口号,
127.0.0.1代表localhost,
前面的8888是第四步-p后面写的端口号,
后面的8888是你要重定向到本机的端口号,可以随意填写
username是服务器的用户名,remote_ip是服务器的ip地址
然后在自己电脑上打开浏览器,输入127.0.0.1:8888,就ok了
6.报错NoneType
请注意,使用nni,必须使用nnictl create --config config.yml启动程序,不能直接Run
7.学会利用日志log
虽然在终端上不能直接看到训练日志,但是实际上在我们设置的实验路径下,有一个log文件,里面记录了所有的stdout内容,可以方便我们调试程序。