学习vue源码(11)学习 合并策略

我们 之前 谈 学习vue源码(5) 手写Vue.use、Vue.mixin、Vue.compile的时候 谈到了Vue.mixin的源码实现,然后谈到了mergeOptions,那时并没有深入解说 这个函数 的原理。如图所示
这次我们就来深入研究下,因此也就离不开Vue中的一个重要思想:合并策略了。
我们有时面试时可能会遇到这样的问题:
- 引入的mixin的data中 有 name这个属性,自己注册的组件的data中也有name,那哪个会生效?
- 引入的mixin中有created,自己注册的组件中也有created,那哪个create会先执行?
- 。。。。
这样的问题其实还很多,而想要弄清楚这些问题,其实就是 合并策略的问题。
现在先大概地谈下合并策略,是让大家有兴趣去研究源码的时候,可以提前理清一下思路。暂时没时间了解源码的,也可以先了解下内部流程,对解决一些奇奇怪怪的问题也是很有作用的
mixins 我觉得可能大家很少用把,但是这个东西真的非常有用。相当于封装,提取公共部分。
显然,今天我不是来教大家怎么用的,怎么用看文档就好了,我是讲解 生命的真谛 内部的工作原理。如果不懂用的,请去官网看怎么用,兄弟
mixin不难,就是有点绕,今天我们探索两个问题
1、什么时候合并
2、怎么合并
什么时候合并
合并分为两种
1.全局mixin 和 基础全局options 合并
这个过程是先于你调用 Vue 时发生的,也是必须是先发生的。这样mixin 才能合并上你的自定义 options
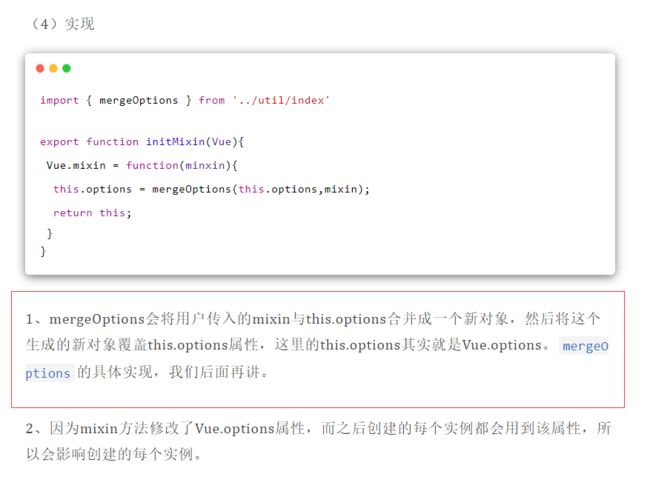
Vue.mixin = function(mixin) {
this.options = mergeOptions(
this.options, mixin
);
return this
};
基础全局options 是什么?
就是 components,directives,filters 这三个,一开始就给设置在了 Vue.options 上。所以这三个是最先存在全局options。
Vue.options = Object.create(null);
['component','directive','filter'].forEach(function(type) {
Vue.options[type + 's'] = Object.create(null);
});
这一步,是调用 Vue.mixin 的时候就马上合并了,然后这一步完成 以后,举个栗子

全局选项就变成下面这样,然后每个Vue实例都需要和这全局选项合并

可能你会奇怪,我明明没写keep-alive这些组件,为什么可以用这些组件呢?
其实原因就在这,在我们new Vue,之前 ,源码 就给 Vue 的 option中的 components数组 添加了keep-alive这些组件。
基础组件形成后 就 和 全局的mixin合并生成新的option。
然后,我们new Vue()时,会传入自己的option,然后就把自己的option和上面那个新的option合并。
2.全局options和 自定义options合并
在调用Vue 的时候,首先进行的就是合并
function Vue(options){
vm.$options = mergeOptions(
{ 全局component,
全局directive,
全局filter 等....},
options , vm
);
...处理选项,生成模板,挂载DOM 等....
}
options 就是你自己传进去的对象参数,然后跟 全局options 合并,全局options 是哪些,也已经说过了

2.怎么合并
下面开始讲解各种合并策略
1、函数合并叠加
包括选项:data,provide
把两个函数合并加到一个新函数中,并返回这个函数。在函数里面,会执行 那两个方法。
按照这个流程,使用代号
data 中数据有重复的,权重大的优先,比如下面
var test_mixins={
data(){
return {name:34}
}
}
var a=new Vue({
mixins:[test_mixins],
data(){
return {name:12}
}
})
可以看到,mixin 和 组件本身 的 data 都有 name 这个数据,很显然会以组件本身的为主,因为组件本身权重大
2、数组叠加
包括生命周期函数和watch
生命周期函数
权重越大的越放后面,会合并成一个数组,比如created
[
全局 mixin - created,
组件 mixin-mixin - created,
组件 mixin - created,
组件 options - created
]
执行流程是
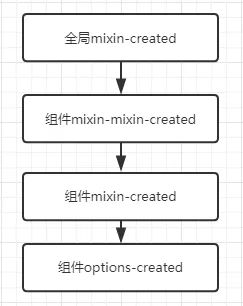
生命周期,权重小的 先执行
watch
合并成一个下面这样的数组,权重越大的越放后面
[
全局 mixin - watch,
组件 mixin-mixin - watch,
组件 mixin - watch,
组件 options - watch
]
执行流程是

监听回调,权重小的 先执行
3、原型叠加
包括选项:components,filters,directives
两个对象合并的时候,不会相互覆盖,而是 权重小的 被放到 权重大 的 的原型上
这样权重大的,访问快些,因为原型链短了
A.__proto__ = B
B.__proto__ = C
C.__proto__ = D
两个对象合并的时候,不会
以 filter 为例,下面是四种 filter 合并
// 全局 filter
Vue.filter("global_filter",function (params) {})
// mixin 的 mixin
var mixin_mixin={
filters:{
mixin_mixin_filter(){}
}
}
// mixin filter
var test_mixins={
mixins:[mixin_mixin],
filters:{
mixin_filter(){}
}
}
// 组件 filter
var a=new Vue({
mixins:[test_mixins],
filters:{
self_filter(){}
}
})
结果就系这样…

4、覆盖叠加
包括选项:props,methods,computed,inject
两个对象合并,如果有重复key,权重大的覆盖权重小的
比如
组件的 props:{ name:""}
组件mixin 的 props:{ name:"", age: "" }
那么 把两个对象合并,有相同属性,以 权重大的为主,组件的 name 会替换 mixin 的name。
这个其实就是跟第一种(函数合并叠加)是一样的,只不过第一种是函数
5、直接替换
这是默认的处理方式,当选项不属于上面的处理方式的时候,就会像这样处理,包含选项:el,template,propData 等
两个数据只替换,不合并,权重大的,会一直替换 权重小的,因为这些属于只允许存在一个,所有只使用权重大的选项
组件 设置 template,mixin 也设置 template,不用怕,组件的肯定优先
这个好像跟 覆盖叠加 很像,其实不一样,覆盖叠加会把两个数据合并,重复的才覆盖。而这个不会合并,直接替换掉整个选项
好了,现在我们结合 源码 来谈谈这五种合并策略。
来看看mergeOptions函数到底是什么妖魔鬼怪
function mergeOptions(parent, child, vm) {
// 遍历mixins,parent 先和 mixins 合并,然后在和 child 合并
if (child.mixins) {
for (var i = 0, l = child.mixins.length; i < l; i++) {
parent = mergeOptions(parent, child.mixins[i], vm);
}
}
var options = {}, key;
// 先处理 parent 的 key,
for (key in parent) {
mergeField(key);
}
// 遍历 child 的key ,排除已经处理过的 parent 中的key
for (key in child) {
if (!parent.hasOwnProperty(key)) {
mergeField(key);
}
}
// 拿到相应类型的合并函数,进行合并字段,strats 请看下面
function mergeField(key) {
// strats 保存着各种字段的处理函数,否则使用默认处理
var strat = strats[key] || defaultStrat;
// 相应的字段处理完成之后,会完成合并的选项
options[key] = strat(parent[key], child[key], vm, key);
}
return options
}
这段代码看上去有点绕,其实无非就是
-
先遍历合并 parent 中的key,保存在变量options
-
再遍历 child,合并补上 parent 中没有的key,保存在变量options
-
优先处理 mixins ,但是过程跟上面是一样的,只是递归处理而已
在上面实例初始化时的合并, parent 就是全局选项,child 就是组件自定义选项,因为 parent 权重比 child 低,所以先处理 parent 。
“公司开除程序猿,也是先开始作用较低。。”
重点其实在于 各式各样的处理函数 strat,下面将会一一列举
注意,不要对strat这个词迷糊,其实就是strategy策略一词的缩写,它就是一个对象,这个对象里
保存了上面说的各种策略。如下
strat = {
// 合并data的策略
data: function(parentVal, childVal, vm) {
return mergeDataOrFn(
parentVal, childVal, vm
)
}
// 合并生命勾子的策略
created: mergeHook;
mounted: mergeHook;
。。。。。
}
下面讲各种合并策略
1. 默认策略 defaultStrats
该策略 不保存在 strat对象中,也就是说在strat对象找不到key对应的策略时就会使用该策略,上面 mergeOptions函数中 的
function mergeField(key) {
// strats 保存着各种字段的处理函数,否则使用默认处理
var strat = strats[key] || defaultStrat;
// 相应的字段处理完成之后,会完成合并的选项
options[key] = strat(parent[key], child[key], vm, key);
}
这段代码就是这个意思。
好了,看下默认策略的源码实现
var defaultStrats= function(parentVal, childVal) {
return childVal === undefined ?
parentVal :
childVal
};
这段函数言简意赅,意思就是优先使用组件的options
组件options>组件 mixin options>全局options
2.data
strats.data = function(parentVal, childVal, vm) {
return mergeDataOrFn(
parentVal, childVal, vm
)
};
function mergeDataOrFn(parentVal, childVal, vm) {
return function mergedInstanceDataFn() {
var childData = childVal.call(vm, vm)
var parentData = parentVal.call(vm, vm)
if (childData) {
return mergeData(childData, parentData)
} else {
return parentData
}
}
}
function mergeData(to, from) {
if (!from) return to
var key, toVal, fromVal;
var keys = Object.keys(from);
for (var i = 0; i < keys.length; i++) {
key = keys[i];
toVal = to[key];
fromVal = from[key];
// 如果不存在这个属性,就重新设置
if (!to.hasOwnProperty(key)) {
set(to, key, fromVal);
}
// 存在相同属性,合并对象
else if (typeof toVal =="object" && typeof fromVal =="object) {
mergeData(toVal, fromVal);
}
}
return to
}
我们先默认 data 的值是一个函数,简化下源码 ,但是其实看上去还是会有些复杂
不过我们主要了解他的工作过程就好了
1、两个data函数 组装成一个函数
2、合并 两个data函数执行返回的 数据对象
3.生命钩子
把所有的钩子函数保存进数组,重要的是数组子项的顺序
顺序就是这样
[
全局 mixin - created,
组件 mixin-mixin - created,
组件 mixin - created,
组件 options - created
]
所以当数组执行的时候,正序遍历,就会先执行全局注册的钩子,最后是 组件的钩子
function mergeHook(parentVal, childVal) {
var arr;
arr = childVal ?
// concat 不只可以拼接数组,什么都可以拼接
( parentVal ?
// 为什么parentVal 是个数组呢
// 因为无论怎么样,第一个 parent 都是{ component,filter,directive}
// 所以在这里,合并的时候,肯定只有 childVal,然后就变成了数组
parentVal.concat(childVal) :
( Array.isArray(childVal) ? childVal: [childVal] )
) :
parentVal
return arr
}
strats['created'] = mergeHook;
strats['mounted'] = mergeHook;
... 等其他钩子
4. component、directives、filters
我一直觉得这个是比较好玩的,这种类型的合并方式,我是从来没有在项目中使用过的
原型叠加
两个对象并没有进行遍历合并,而是把一个对象直接当做另一个对象的原型
这种做法的好处,就是为了保留两个相同的字段且能访问,避免被覆盖
学到了学到了…反正我是学到了
strats.components=
strats.directives=
strats.filters = function mergeAssets(
parentVal, childVal, vm, key
) {
var res = Object.create(parentVal || null);
if (childVal) {
for (var key in childVal) {
res[key] = childVal[key];
}
}
return res
}
就是下面这种,层层叠加的原型

5. watch
watch 的处理,也是合并成数组,重要的也是合并顺序,跟 生命钩子一样
这样的钩子
[
全局 mixin - watch,
组件 mixin-mixin - watch,
组件 mixin - watch,
组件 options - watch
]
按照正序执行,最后执行的 必然是组件的 watch
strats.watch = function(parentVal, childVal, vm, key) {
if (!childVal) {
return Object.create(parentVal || null)
}
if (!parentVal) return childVal
var ret = {};
// 复制 parentVal 到 ret 中
for (var key in parentVal) {
ret[key] = parentVal[key];
}
for (var key$1 in childVal) {
var parent = ret[key$1];
var child = childVal[key$1];
if (!Array.isArray(parent)) {
parent = [parent];
}
ret[key$1] = parent ? parent.concat(child) :
( Array.isArray(child) ? child: [child] );
}
return ret
};
6. props、computed、methods
这几个东西,是不允许重名的,合并成对象的时候,不是你死就是我活
重要的是,以谁的为主?必然是组件options 为主了
比如
组件的 props:{ name:""}
组件mixin 的 props:{ name:"", age: "" }
那么 把两个对象合并,有相同属性,组件的 name 会替换 mixin 的name
strats.props =
strats.methods =
strats.inject =
strats.computed = function(parentVal, childVal, vm, key) {
if (!parentVal) return childVal
var ret = Object.create(null);
// 把 parentVal 的字段 复制到 ret 中
for (var key in parentVal) {
ret[key] = parentVal[key];
}
if (childVal) {
for (var key in childVal) {
ret[key] = childVal[key];
}
}
return ret
};
最后
合并策略大概就这么多,初看有点复杂,其实很简单。就这几种。
有错误的地方,欢迎更正。