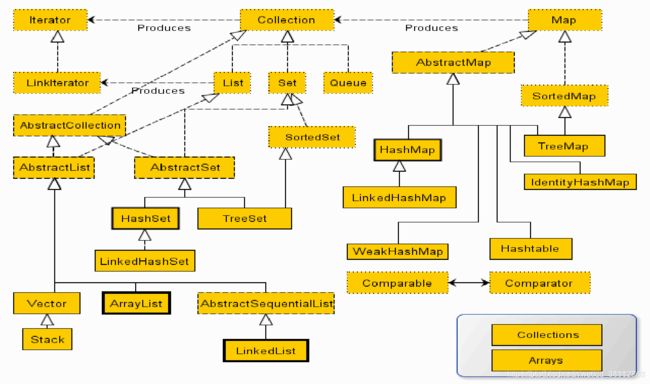
java的容器底层原理实现
一.java容器的体系大览
1. java为啥子需要容器呢?
通常,程序总是在运行时才能确定要创建的对象,甚至是对象的类型。为了解决这个问题,需要在任意时刻任意位置创建任意数量的对象。大多数语言都提供某种方法来解决这个问题,Java使用容器来解决这个问题。容器也称集合类,基本的类型是List、Set、Queue、Map,但由于Java类库中使用了Collection关键字来代表某一接口,所以一般用容器来称呼这些集合类。Java容器工具包位置是java.util.*。
2. java.util包简介

3. 容器的大体组成
Java容器主要可以划分为5个部分:List列表、Set集合、Map映射、queue队列、工具类(Iterator迭代器、Enumeration枚举类、Arrays和Collections)。


上面两图也是下面要展开讲解的部分啦!
二. list接口的实现(主要讲解下面四个实现)

1. list的概念
List 接口继承 Collection,有序允许重复,以元素安插的次序来放置元素,不会重新排列。
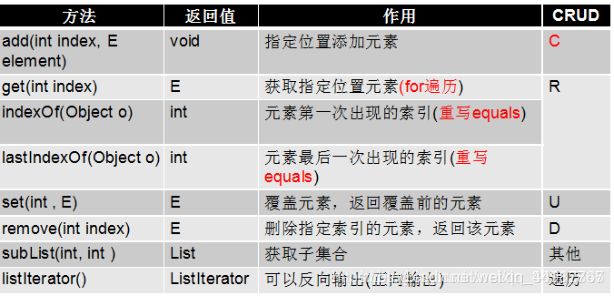
1-1 list集合源码中的方法
package java.util;
import java.util.function.UnaryOperator;
public interface List<E> extends Collection<E> {
// Query Operations
/**
* @return the number of elements in this list
*/
int size();
/**
* @return true if this list contains no elements
*/
boolean isEmpty();
/**
* Returns true if this list contains the specified element.
*/
boolean contains(Object o);
/**
* @return an iterator over the elements in this list in proper sequence
*/
Iterator<E> iterator();
/**
* Returns an array containing all of the elements in this list in proper(自身的,合适的)
* sequence (from first to last element).
*/
Object[] toArray();
/**
* Returns an array containing all of the elements in this list in
*/
<T> T[] toArray(T[] a);
/**
* Appends the specified element to the end of this list (optional operation).
* Lists that support this operation may place limitations on what
* elements may be added to this list. In particular, some
* lists will refuse to add null elements, and others will impose(利用,欺骗)
* restrictions(限制) on the type of elements that may be added(可能添加的元素类型的限制).
*/
boolean add(E e);
/**
* Removes the first occurrence of the specified element from this list
*/
boolean remove(Object o);
/**
* Returns true if this list contains all of the elements of the specified collection.
*/
boolean containsAll(Collection<?> c);
/**
* Appends all of the elements in the specified collection to the end of
*/
boolean addAll(Collection<? extends E> c);
/**
* Inserts all of the elements in the specified collection into this
* list at the specified position (optional operation).
*/
boolean addAll(int index, Collection<? extends E> c);
/**
* Removes from this list all of its elements that are contained in the specified collection (optional operation)
*/
boolean removeAll(Collection<?> c);
/**
* Retains(保持,保留) only the elements in this list that are contained in the
* specified collection (optional operation). In other words, removes
* from this list all of its elements that are not contained in the specified collection.
*/
boolean retainAll(Collection<?> c);
/**
* Replaces each element of this list with the result of applying the operator to that element.
* @since 1.8
*/
default void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
final ListIterator<E> li = this.listIterator();
while (li.hasNext()) {
li.set(operator.apply(li.next()));
}
}
/**
* Sorts this list according to the order induced by the specified
* @since 1.8
*/
@SuppressWarnings({"unchecked", "rawtypes"})
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}
/**
* Removes all of the elements from this list (optional operation).
* The list will be empty after this call returns
*/
void clear();
/**
* Compares the specified object with this list for equality.
* Returns true only if the specified object is also a list, both
* lists have the same size, and all corresponding pairs of (对的)elements in
* the two lists are equal.
* In other words, two lists are defined to be equal if they contain the same elements in the same order. This
* definition ensures that the equals method works properly across
* different implementations of the List interface.
*/
boolean equals(Object o);
/**
* Returns the hash code value for this list. The hash code of a list
* is defined to be the result of the following calculation(计算,计算方法):
* {@code
* int hashCode = 1;
* for (E e : list)
* hashCode = 31*hashCode + (e==null ? 0 : e.hashCode());
* }
*/
int hashCode();
/**
* Returns the element at the specified position in this list.
* @param index index of the element to return
* @return the element at the specified position in this list
* @throws IndexOutOfBoundsException if the index is out of range
* (index < 0 || index >= size()) (因为ArrayList为数组实现方式, 从0开始到长度-1)
*/
E get(int index);
/**
* Replaces the element at the specified position in this list with the specified element (optional operation)
*/
E set(int index, E element);
/**
* Inserts the specified element at the specified position in this list
*/
void add(int index, E element);
/**
* Removes the element at the specified position in this list (optional operation).
*/
E remove(int index);
/**
* Returns the index of the first occurrence of the specified element (返回第一个出现该元素的位置)
* in this list, or -1 if this list does not contain the element.
*/
int indexOf(Object o);
/**
* Returns the index of the last occurrence of the specified element
* in this list, or -1 if this list does not contain the element.
*/
int lastIndexOf(Object o);
/**
* Returns a list iterator over the elements in this list (in proper sequence).
*/
ListIterator<E> listIterator();
/**
* Returns a list iterator over the elements in this list (in proper
* sequence), starting at the specified position in the list.
*/
ListIterator<E> listIterator(int index);
/**
* Returns a view of the portion of this list between the specified
* fromIndex, inclusive(递归), and toIndex, exclusive. (If
* fromIndex and toIndex are equal, the returned list is empty.)
*/
List<E> subList(int fromIndex, int toIndex);
/**
* Creates a {@link Spliterator} over the elements in this list
* @since 1.8
*/
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.ORDERED);
}
}
2. ArrayList的实现
ArrayList 是 List 的子类,它和 HashSet 相反,允许存放重复元素,因此有序。集合中元素被访问的顺序取决于集合的类型。如果对 ArrayList 进行访问,迭代器将从索引 0 开始,每迭代一次,索引值加 1。然而,如果访问 HashSet 中的元素,每个元素将会按照某种随机的次序出现。虽然可以确定在迭代过程中能够遍历到集合中的所有元素,但却无法预知元素被访问的次序。
2-1 特点
底层用数组实现的 List。特点:查询效率高,增删效率低,线程不安全。
既然使用数组实现,底层的查询与插入等等一定是与数组的操作时一样的
下面来看看里面几个重要的方法实现
add(E e)方法的源码实现
public void add(E e) {
int cursor; // index of next element to return (该指针始终指向最后一个元素的下一个元素下标)
int lastRet = -1; // index of last element returned; -1 if no such(当cursor指向最后一个的时候就为-1啦!)
int expectedModCount = modCount; //protected transient int modCount = 0;
checkForComodification();
try {
int i = cursor;
ArrayList.this.add(i, e);
cursor = i + 1;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
add(int index, E element)方法的实现
public void add(int index, E element) {
rangeCheckForAdd(index); //检查下标越界的函数
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1, size - index);
elementData[index] = element;
size++;
}
真正的插入方法实现 arraycopy(Object src, int srcPos, Object dest, int destPos, int length);
private void ensureCapacityInternal(int minCapacity) {
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); //相当于+1啦!
}
/**
* The capacity of the ArrayList is the length of this array buffer.
* Any empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to)(扩展到) DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData;
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* Copies an array from the specified source array, beginning at the
* specified position, to the specified position of the destination array.
* @param src the source array.
* @param srcPos starting position in the source array.
* @param dest the destination array.
* @param destPos starting position in the destination data.
* @param length the number of array elements to be copied.
*/
public static native void arraycopy(Object src, int srcPos, Object dest, int destPos, int length);
2-2 得出的结论
从上面的ArrayList的插入方式可以知道,里面的元素都是可以重复且与插入的顺序一致(因为是一个接着一个插入的)
2-3 get(int, index)的实现
public E get(int index) {
rangeCheck(index); //检查下标问题
return elementData(index);
}
E elementData(int index) {
return (E) elementData[index];
}
2-4 再次得出结论
为啥ArrayList的查询效率高呢?因为它是根据所给的下标直接返回了元素的. 再深入一步,数组是怎样通过给定一个下标就能直接得到他的值的呢! 下面简单来谈一下.
定义一个数组其实它的引用(也就是底层实现的爸爸指针啦!)指向的是该数组的首地址, 如:
Integer[] array = new Integer[5];
array = {1,2,3,4,5};
1. new(实例化对象) jvm做的三件大事: 在堆里分配空间, 在栈里分配引用空间, 该引用(指针)指向该对象在堆里面的首地址
2. 数组得到的一定是内存中的连续空间
3. 里面的每个子空间为该数组的类型所占的内存大小
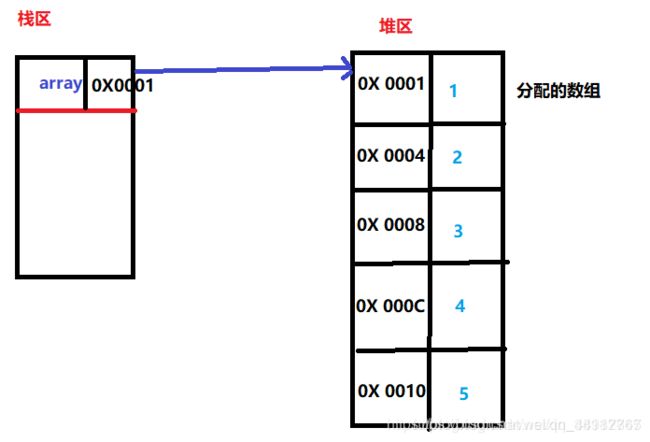
从数组中取元素的时间复杂度为:o(1)
2-5 增删效率低
正因为数组为连续空间存储,当你添加或删除一个元素其他的元素必须跟着相应的移动,效率很低,时间复杂度为: o(n)(n为数组的长度)
2-6 ArrayList的set加入元素的实现
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
看完上面的源码有没有发现什么惊天大密码? 主要它的下标index, 能得出的结论就是:
采用set方式,你要设置的该下标必须的存在元素,也就是说每个下标的第一次赋值必须用add方式,set相当于修改该下标的值;
如果直接用set方式给ArrayList赋值,会抛出下标越界异常,请看下面的测试:
public static void main(String[] args) {
//LinkedList
ArrayList<Integer> array = new ArrayList<>();
array.add(0,3);
array.add(1,3);
array.set(2, 4);
for(int i=0; i<array.size(); ++i){
System.out.println(array.get(i));
}
}
抛出的异常为:

而且采用add添加元素时,必须连续的添加且从0下标开始,不然也会抛出上面的异常, 如下写法错误:
/第一种错误写法
array.add(1,3);
array.add(2,4);
//第二种错误写法
array.add(0,3);
array.add(2,4);
//正确写法
array.add(0,3);
array.add(1,4);
2-7 为啥ArrayList是线程不安全的呢?
public boolean add(E e) {
/**
* 添加一个元素时,做了如下两步操作
* 1.判断列表的capacity容量是否足够,是否需要扩容
* 2.真正将元素放在列表的元素数组里面
*/
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
/**
*扩容的基本操作源码
*/
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
仔细观察源码,是有多线程安全问题的,主要有两个基本问题:
1.在多个线程进行add操作时可能会导致elementData数组越界. 具体逻辑如下:
数组默认大小为10,即size=10
线程A开始进入add方法,这时它获取到当前数组size的值为9,调用ensureCapacityInternal方法进行容量判断。
线程B此时也进入add方法,它获取到size的值也为9,也开始调用ensureCapacityInternal方法。
线程A发现需求大小为10,而elementData的大小就为10,可以容纳。于是它不再扩容,返回。
线程B也发现需求大小为10,也可以容纳,返回。
线程A开始进行设置值操作, elementData[size++] = e 操作。此时size变为10。
线程B也开始进行设置值操作,它尝试设置elementData[10] = e,而elementData没有进行过扩容,它的下标最大为9。于是此时会报出一个数组越界的异常ArrayIndexOutOfBoundsException.
elementData[size++] = e 设置值的操作同样会导致线程不安全。从这儿可以看出,这步操作也不是一个原子操作,它由如下两步操作构成:
elementData[size] = e; //1111111
size = size + 1; //2222222
在单线程执行这两条代码时没有任何问题,但是当多线程环境下执行时,可能就会发生一个线程的值覆盖另一个线程添加的值,具体逻辑如下:
列表大小为0,即size=0
线程A开始添加一个元素,值为A。此时它执行第一条操作,将A放在了elementData下标为0的位置上。
接着线程B刚好也要开始添加一个值为B的元素,且走到了第一步操作。此时线程B获取到size的值依然为0,于是它将B也放在了elementData下标为0的位置上。
线程A开始将size的值增加为1
线程B开始将size的值增加为2
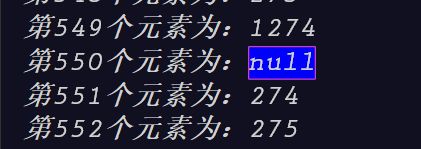
这样线程AB执行完毕后,理想中情况为size为2,elementData下标0的位置为A,下标1的位置为B。而实际情况变成了size为2,elementData下标为0的位置变成了B,下标1的位置上什么都没有。并且后续除非使用set方法修改此位置的值,否则将一直为null,因为size为2,添加元素时会从下标为2的位置上开始。
线程测试不安全,让它先出原型:
public static void main(String[] args) throws InterruptedException {
List<Integer> list = new ArrayList<>();
// 线程A将0-1000添加到list
new Thread(new Runnable() {
public void run() {
for (int i = 0; i < 1000 ; i++) {
list.add(i);
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
// 线程B将1000-2000添加到列表
new Thread(new Runnable() {
public void run() {
for (int i = 1000; i < 2000 ; i++) {
list.add(i);
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
Thread.sleep(1000);
// 打印所有结果
for (int i = 0; i < list.size(); i++) {
System.out.println("第" + (i + 1) + "个元素为:" + list.get(i));
}
}
结果如下:
3. LinkedList的实现
LinkedList 是一种可以在任何位置进行高效地插入和删除操作的有序序列。底层用双向链表实现的 List。特点:查询效率低,增删效率高,线程不安全。
java里面定义的链式结构如下:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
这就知道了LinkedList 的底层是用双向链表实现的,下面先来从数据结构的角度分析一下双向链表的特点:
双向链表的插入
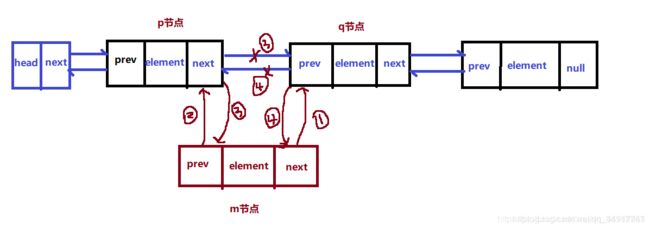
如上图,大致有四步操作,对应的算法实现如下:
m.next=q.prev; //1
m.prev=p.next; //2
p.next=m.prev; //3
q.prev=m.next; //4
双向链表的删除
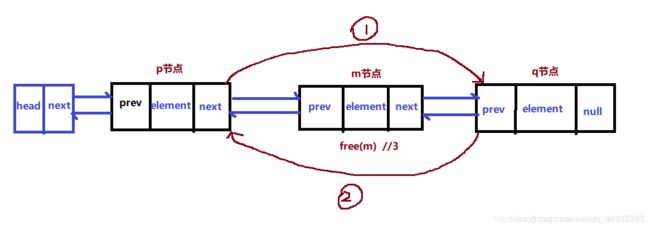
对应的算法实现如下:
`p.next=m.next; //1
m.next.prev=m.prev //2`’
3-1 上面解释了第一个问题:查询效率低,增删效率高
查询元素的复杂度为:o(n) //n为链表的size
增删的时间复杂度为:o(1)
3-2 从源码看java怎样实现元素的添加的
add(E e)方法的实现
/**
*初始化的一些值
*/
private Node<E> lastReturned;
private Node<E> next;
private int nextIndex;
public void add(E e) {
checkForComodification();
lastReturned = null;
if (next == null)
linkLast(e); //链表的尾插法(默认为尾插法)
else
linkBefore(e, next); //链表的头插法
nextIndex++; //始终指向当前节点
expectedModCount++;
}
add(E e)的分解详解
final void checkForComodification() {
protected transient int modCount = 0; //初始化的值
private int expectedModCount = modCount; //初始化的值
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last; //l 与 last两个指针同时指向最后一个节点
final Node<E> newNode = new Node<>(l, e, null); //得到一个新节点,新的节点的前驱指向最后一个节点的后继
last = newNode; //last指向新的节点,怎样最后一个节点与新的节点互联了
if (l == null) //异常,没有连上
first = newNode; //头结点指针指向新节点
else
l.next = newNode;
size++; //链表长度加1
modCount++; //对应的加1
}
/**
* Inserts element e before non-null Node succ.
*/
void linkBefore(E e, Node<E> succ) { //succ节点为头结点后面的第一个数据节点
// assert succ != null;
final Node<E> pred = succ.prev; //定义个指针指向head节点
final Node<E> newNode = new Node<>(pred, e, succ); //得到的节点已经连接好两个点啦!
succ.prev = newNode; //继续连接
if (pred == null) //如果pred连接不成功
first = newNode; //采用first指针连接
else
pred.next = newNode;
size++;
modCount++;
}
3-3 插入节点的结论
从上面可以得出,LinkedList默认插入方式为尾插法,也就是每个元素都是插在链表的最后面,所以为有序序列,且允许元素为空,且为双向链表,源码里面写的非常清楚:
* Doubly-linked list implementation of the {@code List} and {@code Deque}
* interfaces. Implements all optional list operations, and permits allelements (including {@code null}).
3-4 获取元素的方法实现
get(int index) 方法的源码实现
public E get(int index) {
checkElementIndex(index); //检查下标的函数
return node(index).item;
}
get(int index)的分解
/**
*下标检测
*/
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
/**
* 关键代码的实现
* Returns the (non-null) Node at the specified element index.
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) { // 为运算, 向右移动一位2进制, 如果为偶数相当于除2, 如果为奇数那就是整除2,如5/2=2;
// 上面的判断减少了检索次数,时间复杂度为0(n/2);优秀
Node<E> x = first; //头结点
for (int i = 0; i < index; i++)
x = x.next; //往后走
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev; //往前走
return x;
}
}
3-5 get结论
上面的检索顺序根据下标,先判断落在前半段还是后半段,大大的减少了索引的顺序,使得时间复杂度降低了一半,但是与ArrayList的数组实现模式相比,这样的时间复杂度还是不能忍受的.
3-6 简单看一下set(E e), 覆盖元素,与上面差不多,不多讲解
public void set(E e) {
if (lastReturned == null)
throw new IllegalStateException();
checkForComodification();
lastReturned.item = e;
}
- Stack 与 Vector实现
4-1 Vector实现线程安全的方式
Vector(向量)与 ArrayList 底层一致,就是多了线程安全而已。那Vector到底施了啥魔法变得线程安全呢?那下面我来简单的通过源码来展示它背后的神秘力量.
继承结构:
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
4-2 实现线程安全的关键
public void add(E e) {
int i = cursor;
synchronized (Vector.this) {
checkForComodification();
Vector.this.add(i, e);
expectedModCount = modCount;
}
cursor = i + 1;
lastRet = -1;
}
揭开它的面纱才发现:我靠,这么简单,暴力,每错,与ArrayList的方式一模一样,就是加了个同步锁,其实看到这里我情不自禁的笑起来了,简简单单.
这也解释了为什么Vector效率比较低啦!原因就是多了个同步等待啦!
熊掌与鱼不可兼得,java中还有许多怎样的例子啦! StringBuffer(低效,安全)与StringBuilder就是怎样啦!但逗比String高效.
4-3 Stack实现FILO(先进后出)的方法
Stack(栈)为 Vector 子类,具有后进先出的特点。
继承结构图:
/**
* The Stack class represents a last-in-first-out
* (LIFO) stack of objects.
* @since JDK1.0
*/
public
class Stack<E> extends Vector<E
4-4 FILO的源码实现
插入的操作: push(E item)
/**
* Pushes an item onto the top of this stack. This has exactly
* @param item the item to be pushed onto this stack.
* @return the item argument.
*/
public E push(E item) {
addElement(item);
return item;
}
/**
* Adds the specified component to the end of this vector,
* increasing its size by one.(并不是从1开始的意思,而是栈是从小到大的增长)
*/
public synchronized void addElement(E obj) {
modCount++;
ensureCapacityHelper(elementCount + 1); //与ArrayList一样
elementData[elementCount++] = obj; //先赋值再++
}
弹出元素的操作: pop(E obj)
/**
* Removes the object at the top of this stack and returns that
* object as the value of this function.
*
* @return The object at the top of this stack (the last item
* of the Vector object).
*/
public synchronized E pop() {
E obj;
int len = size();
obj = peek(); //求出最上面元素的下标
removeElementAt(len - 1); //实际弹出的为最新push进去的元素
return obj;
}
/**
* Looks at the object at the top of this stack without removing(正在移动的) it
* from the stack.
*
* @return the object at the top of this stack (the last item
* of the Vector object).
* @throws EmptyStackException if this stack is empty.
*/
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
4-5 FILO结论
话不多说,从上面可以赤裸裸的看出Stack(栈)是如何实现先进后出的功能的,插入正常,但是弹出就有点猫腻啦!
三. map接口的源码实现
-
map基本概念
HashMap 可以说是 Java 中最常用的集合类框架之一,是 Java 语言中非常典型的数据结构,我们总会在不经意间用到它,很大程度上方便了我们日常开发。实现 Map 接口的类 用来存储 键(key) -值(value) 对,Map 类中存储的键-值对通过键来标识, 所以键值不能重复。 -
map接口的基本方法
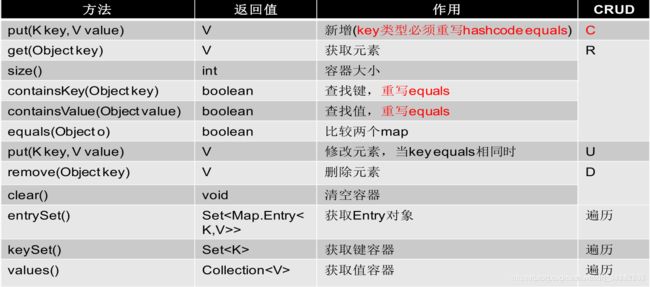
package java.util;
/**
* An object that maps keys to values. A map cannot contain duplicate keys;
* each key can map to at most one value.(key不能重复啦!)
* @since 1.2
*/
public interface Map<K,V> {
/**
* Returns the number of key-value mappings in this map.
*/
int size();
/**
* Returns true if this map contains no key-value mappings.
*/
boolean isEmpty();
/**
* Returns true if this map contains a mapping for the specified key.
*/
boolean containsKey(Object key);
/**
* Returns true if this map maps one or more keys to the specified value.
*/
boolean containsValue(Object value);
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*/
V get(Object key);
/**
* Associates the specified value with the specified key in this map (optional operation).
*/
V put(K key, V value);
/**
* Removes the mapping for a key from this map if it is present
*/
V remove(Object key);
/**
* Copies all of the mappings from the specified map to this map
* (optional operation).
*/
void putAll(Map<? extends K, ? extends V> m);
/**
* Removes all of the mappings from this map (optional operation).
* The map will be empty after this call returns.
*/
void clear();
/**
* Returns a {@link Set} view of the keys contained in this map.
*/
Set<K> keySet();
/**
* Returns a {@link Collection} view of the values contained in this map.
*/
Collection<V> values();
/**
* Returns a {@link Set} view of the mappings contained in this map.
*/
Set<Map.Entry<K, V>> entrySet();
/**
* A map entry (key-value pair). The Map.entrySet method returns
* a collection-view of the map
* @since 1.2
*/
interface Entry<K,V> {
/**
* Returns the key corresponding to this entry.
*/
K getKey();
/**
* Returns the value corresponding to this entry. If the mapping
V getValue();
/**
* Replaces the value corresponding to this entry with the specified
* value (optional operation).
*/
V setValue(V value);
/**
* Compares the specified object with this entry for equality.
* Returns true if the given object is also a map entry and
* the two entries represent the same mapping.
*/
boolean equals(Object o);
/**
* Returns the hash code value for this map entry.
*/
int hashCode();
/**
* Returns a comparator that compares {@link Map.Entry} in natural order on key.
* @since 1.8
*/
public static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K,V>> comparingByKey() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getKey().compareTo(c2.getKey());
}
/**
* Returns a comparator that compares {@link Map.Entry} in natural order on value.
* @since 1.8
*/
public static <K, V extends Comparable<? super V>> Comparator<Map.Entry<K,V>> comparingByValue() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getValue().compareTo(c2.getValue());
}
/**
* Returns a comparator that compares {@link Map.Entry} by key using the given
* @since 1.8
*/
public static <K, V> Comparator<Map.Entry<K, V>> comparingByKey(Comparator<? super K> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getKey(), c2.getKey());
}
/**
* Returns a comparator that compares {@link Map.Entry} by value using the given
* @since 1.8
*/
public static <K, V> Comparator<Map.Entry<K, V>> comparingByValue(Comparator<? super V> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getValue(), c2.getValue());
}
}
/**
* Compares the specified object with this map for equality. Returns
* true if the given object is also a map and the two maps
* represent the same mappings.
*/
boolean equals(Object o);
/**
* Returns the hash code value for this map.
*/
int hashCode();
/**
* Returns the value to which the specified key is mapped, or
* {@code defaultValue} if this map contains no mapping for the key.
* @since 1.8
*/
default V getOrDefault(Object key, V defaultValue) {
V v;
return (((v = get(key)) != null) || containsKey(key))
? v
: defaultValue;
}
/**
* Performs the given action for each entry in this map until all entries
* have been processed or the action throws an exception. Unless
* otherwise specified by the implementing class, actions are performed in
* the order of entry set iteration (if an iteration order is specified.)
* @since 1.8
*/
default void forEach(BiConsumer<? super K, ? super V> action) {
Objects.requireNonNull(action);
for (Map.Entry<K, V> entry : entrySet()) {
K k;
V v;
try {
k = entry.getKey();
v = entry.getValue();
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
action.accept(k, v);
}
}
/**
* Replaces each entry's value with the result of invoking the given
* function on that entry until all entries have been processed or the
* function throws an exception.
* @since 1.8
*/
default void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {
Objects.requireNonNull(function);
for (Map.Entry<K, V> entry : entrySet()) {
K k;
V v;
try {
k = entry.getKey();
v = entry.getValue();
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
// ise thrown from function is not a cme.
v = function.apply(k, v);
try {
entry.setValue(v);
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
}
}
/**
* If the specified key is not already associated with a value (or is mapped
* to {@code null}) associates it with the given value and returns
* {@code null}, else returns the current value.
* @since 1.8
*/
default V putIfAbsent(K key, V value) {
V v = get(key);
if (v == null) {
v = put(key, value);
}
return v;
}
/**
* Removes the entry for the specified key only if it is currently
* mapped to the specified value
* @since 1.8
*/
default boolean remove(Object key, Object value) {
Object curValue = get(key);
if (!Objects.equals(curValue, value) ||
(curValue == null && !containsKey(key))) {
return false;
}
remove(key);
return true;
}
/**
* Replaces the entry for the specified key only if currently
* mapped to the specified value.
* @since 1.8
*/
default boolean replace(K key, V oldValue, V newValue) {
Object curValue = get(key);
if (!Objects.equals(curValue, oldValue) ||
(curValue == null && !containsKey(key))) {
return false;
}
put(key, newValue);
return true;
}
/**
* Replaces the entry for the specified key only if it is
* currently mapped to some value
* @since 1.8
*/
default V replace(K key, V value) {
V curValue;
if (((curValue = get(key)) != null) || containsKey(key)) {
curValue = put(key, value);
}
return curValue;
}
/**
* If the specified key is not already associated with a value (or is mapped
* to {@code null}), attempts to compute its value using the given mapping
* function and enters it into this map unless {@code null}.
* @since 1.8
*/
default V computeIfPresent(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
V oldValue;
if ((oldValue = get(key)) != null) {
V newValue = remappingFunction.apply(key, oldValue);
if (newValue != null) {
put(key, newValue);
return newValue;
} else {
remove(key);
return null;
}
} else {
return null;
}
}
/**
* Attempts to compute a mapping for the specified key and its current
* mapped value (or {@code null} if there is no current mapping). For
* example, to either create or append a {@code String} msg to a value mapping
* @since 1.8
*/
default V compute(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
V oldValue = get(key);
V newValue = remappingFunction.apply(key, oldValue);
if (newValue == null) {
// delete mapping
if (oldValue != null || containsKey(key)) {
// something to remove
remove(key);
return null;
} else {
// nothing to do. Leave things as they were.
return null;
}
} else {
// add or replace old mapping
put(key, newValue);
return newValue;
}
}
/**
* If the specified key is not already associated with a value or is
* associated with null, associates it with the given non-null value.
* Otherwise, replaces the associated value with the results of the given
* remapping function, or removes if the result is {@code null}. This
* method may be of use when combining multiple mapped values for a key.
* For example, to either create or append a {@code String msg} to a
* value mapping:
* @since 1.8
*/
default V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
Objects.requireNonNull(value);
V oldValue = get(key);
V newValue = (oldValue == null) ? value :
remappingFunction.apply(oldValue, value);
if(newValue == null) {
remove(key);
} else {
put(key, newValue);
}
return newValue;
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
3. map的实现类HashMap的实现
HashMap: 线程不安全,效率高. 允许 key 或 value 为 null
在JDK1.6,JDK1.7中,HashMap采用位桶+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,HashMap采用位桶+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
当链表数组的容量超过初始容量的0.75时,再散列将链表数组扩大2倍,把原链表数组的搬移到新的数组,HashMap底层采用散列表存储方式,即是数组+链表的存储方式,结构如下:
为啥能允许key为空呢?还是得从源码入手
1. transient Node<k,v>[] table;//存储(位桶)的数组 的定义,其中 数组元素Node实现了Entry接口,代码如下:
1
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
//Node是单向链表,它实现了Map.Entry接口
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
//构造函数的Hash值, 建, 值, 下一个节点的指针
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() { //计算hashcode的方法
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
//判断两个node是否相等,若key和value都相等,返回true。可以与自身比较为true
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
2.源码中的数据域:
加载因子(默认0.75):为什么需要使用加载因子,为什么需要扩容呢?因为如果填充比很大,说明利用的空间很多,如果一直不进行扩容的话,
链表就会越来越长,这样查找的效率很低,因为链表的长度很大(当然最新版本使用了红黑树后会改进很多),扩容之后,
将原来链表数组的每一个链表分成奇偶两个子链表分别挂在新链表数组的散列位置,这样就减少了每个链表的长度,增加查找效率
1
2
3
4
public class HashMap<k,v> extends AbstractMap<k,v> implements Map<k,v>, Cloneable, Serializable {
private static final long serialVersionUID = 362498820763181265L;
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //值为16
static final int MAXIMUM_CAPACITY = 1 << 30;//最大容量
static final float DEFAULT_LOAD_FACTOR = 0.75f;//填充比
//当add一个元素到某个位桶,其链表长度达到8时将链表转换为红黑树
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
static final int MIN_TREEIFY_CAPACITY = 64;
transient Node<k,v>[] table;//存储元素的数组
transient Set<map.entry<k,v>> entrySet;
transient int size;//存放元素的个数
transient int modCount;//被修改的次数fast-fail机制
int threshold;//临界值 当实际大小(容量*填充比)超过临界值时,会进行扩容
final float loadFactor;//填充比(......后面略)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
3. HashMap的四种构造函数
1
//构造函数1
public HashMap(int initialCapacity, float loadFactor) {
//指定的初始容量非负
if (initialCapacity < 0)
throw new IllegalArgumentException(Illegal initial capacity: +
initialCapacity);
//如果指定的初始容量大于最大容量,置为最大容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//填充比为正
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException(Illegal load factor: +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);//新的扩容临界值
}
//构造函数2
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
//构造函数3
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
//构造函数4用m的元素初始化散列映射
public HashMap(Map<!--? extends K, ? extends V--> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
4.老大put(key,value)来了
1
/**
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with key,
* or null if there was no mapping for key
* HashMap map = new HashMap(); //返回结果如下
System.out.println(map.put(1, 11)); //null
System.out.println(map.put(2,22 )); //null
System.out.println(map.put(2,33 )); //22 ,也就是返回改变前的值
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
1
2
3
4
5
6
7
8
9
10
11
12
13
put(K key, V value)的详解
下面简单说下添加键值对put(key,value)的过程:
1,判断键值对数组tab[]是否为空或为null,否则以默认大小resize();
2,根据键值key计算hash值得到插入的数组索引i,如果tab[i]==null,直接新建节点添加,否则转入3
3,判断当前数组中处理hash冲突的方式为链表还是红黑树(check第一个节点类型即可),分别处理
1
2
3
4
5
/**
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode(表处于创建模式).
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
/*如果table的在(n-1)&hash的值是空,就新建一个节点插入在该位置*/
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
/*表示有冲突,开始处理冲突*/
else {
Node<K,V> e; K k;
/*检查第一个Node,p是不是要找的值*/
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
/*指针为空就挂在后面*/
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//如果冲突的节点数已经达到8个,看是否需要改变冲突节点的存储结构,
//treeifyBin首先判断当前hashMap的长度,如果不足64,只进行
//resize,扩容table,如果达到64,那么将冲突的存储结构为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
/*如果有相同的key值就结束遍历*/
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
/*就是链表上有相同的key值*/
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue; //返回存在的Value值
}
}
++modCount;
/*如果当前大小大于门限,门限原本是初始容量*0.75*/
if (++size > threshold)
resize(); //扩容两倍
afterNodeInsertion(evict);
return null;
}
5. HasMap的扩容机制resize(); 构造hash表时,如果不指明初始大小,默认大小为16(即Node数组大小16),如果Node[]数组中的元素达到
(填充比*Node.length)重新调整HashMap大小 变为原来2倍大小,扩容很耗时源码如下:(填充比*Node.length)重新调整HashMap大小
变为原来2倍大小,扩容很耗时源码如下:变为原来2倍大小,扩容很耗时源码如下:
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
*
* @return the table
*/
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
/*如果旧表的长度不是空*/
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
/*把新表的长度设置为旧表长度的两倍,newCap=2*oldCap*/
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
/*把新表的门限设置为旧表门限的两倍,newThr=oldThr*2*/
newThr = oldThr << 1; // double threshold
}
/*如果旧表的长度的是0,就是说第一次初始化表*/
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;//新表长度乘以加载因子
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
/*下面开始构造新表,初始化表中的数据*/
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;//把新表赋值给table
if (oldTab != null) {//原表不是空要把原表中数据移动到新表中
/*遍历原来的旧表*/
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)//说明这个node没有链表直接放在新表的e.hash & (newCap - 1)位置
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
/*如果e后边有链表,到这里表示e后面带着个单链表,需要遍历单链表,将每个结点重*/
else { // preserve order保证顺序
////新计算在新表的位置,并进行搬运
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;//记录下一个结点
//新表是旧表的两倍容量,实例上就把单链表拆分为两队,
//e.hash&oldCap为偶数一队,e.hash&oldCap为奇数一对
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {//lo队不为null,放在新表原位置
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {//hi队不为null,放在新表j+oldCap位置
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
6. get(key)方法时获取key的hash值,计算hash&(n-1)得到在链表数组中的位置first=tab[hash&(n-1)],先判断first的key是否与参数key相等,
不等就遍历后面的链表找到相同的key值返回对应的Value值即可不等就遍历后面的链表找到相同的key值返回对应的Value值即可
get(Object key)的源码实现get(Object key)的源码实现:
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab;//Entry对象数组
Node<K,V> first,e; //在tab数组中经过散列的第一个位置
int n;
K k;
/*找到插入的第一个Node,方法是hash值和n-1相与,tab[(n - 1) & hash]*/
//也就是说在一条链上的hash值相同的
if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {
/*检查第一个Node是不是要找的Node*/
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))//判断条件是hash值要相同,key值要相同
return first;
/*检查first后面的node*/
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
/*遍历后面的链表,找到key值和hash值都相同的Node*/
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
7.JDK1.8 使用红黑数的改进(可以对比平衡二叉树,有许多相同点),排好了序的
在Java jdk8中对HashMap的源码进行了优化,在jdk7中,HashMap处理“碰撞”的时候,都是采用链表来存储,当碰撞的点很多时,查询时间是O(n)。
在jdk8中,HashMap处理“碰撞”增加了红黑树这种数据结构,当碰撞结点较少时,采用链表存储,当较大时(>8个),采用红黑树(特点是查询时间是O(log2 n))存储(有一个阀值控制,大于阀值(8个),将链表存储转换成红黑树存储)
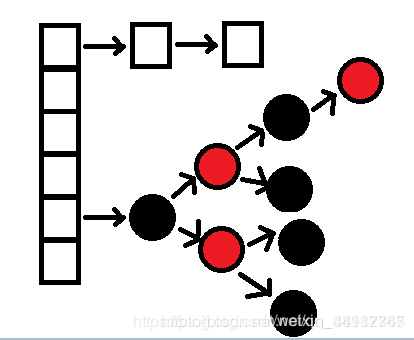
你可能还知道哈希碰撞会对hashMap的性能带来灾难性的影响。如果多个hashCode()的值落到同一个桶内的时候,这些值是存储到一个链表中的。最坏的情况下,所有的key都映射到同一个桶中,这样hashmap就退化成了一个链表——查找时间从O(1)到O(n)。
随着HashMap的大小的增长,get()方法的开销也越来越大。由于所有的记录都在同一个桶里的超长链表内,平均查询一条记录就需要遍历一半的列表。
JDK1.8HashMap的红黑树是这样解决的:
如果某个桶中的记录过大的话(当前是TREEIFY_THRESHOLD = 8),HashMap会动态的使用一个专门的treemap(实现红黑数的数据结构)实现来替换掉它。这样做的结果会更好,是O(log2 n),而不是糟糕的O(n)。
它是如何工作的?前面产生冲突的那些KEY对应的记录只是简单的追加到一个链表后面,这些记录只能通过遍历来进行查找。但是超过这个阈值后HashMap开始将列表升级成一个二叉树,使用哈希值作为树的分支变量,hashcode值取余法等等,如果两个哈希值不等,但指向同一个桶的话,较大的那个会插入到右子树里。如果哈希值相等,HashMap希望key值最好是实现了Comparable接口的,这样它可以按照顺序来进行插入。这对HashMap的key来说并不是必须的,不过如果实现了当然最好。如果没有实现这个接口,在出现严重的哈希碰撞的时候,你就并别指望能获得性能提升了。
- HashTable的实现
线程安全,效率低. 不允许 key 或 value 为 null
为啥有上面的特点,从源码来看看
4-1 put(key, value)方法的实现

public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode(); //如果key为空,抛出NullPointerException();异常,所以没有判断
//&运算为两个数的二进制的相同数的结果,都从低位开始,如:(4 & 12)--->(100 & 1100)--->100--->4
int index = (hash & 0x7FFFFFFF) % tab.length; //下标为hashcode值取模法,得到在hash表里面的位置
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) { //散列表的数组部分不为空
if ((entry.hash == hash) && entry.key.equals(key)) { //找到了桶位,该插入到后面的链表啦!
//下面三条语句就是将桶位后第一个entry换成插入的,并把原来第一个值返回
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
上面的已经很好的解释了hashTable的特点了:线程安全,效率低. 不允许 key 或 value 为 null
- Properties的实现
Properties是Hashtable 的子类,但是key 和 value 都是 string , 也就是我们常用的那个Properties文件啦!里面果然是键值对key-value的形式啦!
四. set接口的源码实现

1. set基本概念
Set 接口继承 Collection,使用自己内部的一个排列机制。Set 接口中的元素无序不可重复:不包含重复元素,最多包含一个 null,元素没有顺序 。
2. set接口的基本方法
package java.util;
/**
* A collection that contains no duplicate elements.
* @since 1.2
*/
public interface Set<E> extends Collection<E> {
/**
* Returns the number of elements in this set (its cardinality).
*/
int size();
/**
* Returns true if this set contains no elements.
*/
boolean isEmpty();
/**
* Returns true if this set contains the specified element.
*/
boolean contains(Object o);
/**
* Returns an iterator over the elements in this set. The elements are
* returned in no particular order (unless this set is an instance of some
* class that provides a guarantee).
*/
Iterator<E> iterator();
/**
* Returns an array containing all of the elements in this set.
*/
Object[] toArray();
/**
* Returns an array containing all of the elements
*/
<T> T[] toArray(T[] a);
/**
* Adds the specified element to this set if it is not already present(optional operation).
*/
boolean add(E e);
/**
* Removes the specified element from this set if it is present
*/
boolean remove(Object o);
/**
* Returns true if this set contains all of the elements of the
* specified collection.
*/
boolean containsAll(Collection<?> c);
/**
* Adds all of the elements in the specified collection to this set if
* they're not already present (optional operation).
*/
boolean addAll(Collection<? extends E> c);
/**
* Retains only the elements in this set that are contained in the
* specified collection (optional operation). In other words, removes
* from this set all of its elements that are not contained in the
* specified collection.
*/
boolean retainAll(Collection<?> c);
/**
* Removes from this set all of its elements that are contained in the
* specified collection (optional operation).
*/
boolean removeAll(Collection<?> c);
/**
* Removes all of the elements from this set (optional operation).
* The set will be empty after this call returns.
*
* @throws UnsupportedOperationException if the clear method
* is not supported by this set
*/
void clear();
/**
* Compares the specified object with this set for equality. Returns
* true if the specified object is also a set, the two sets
* have the same size, and every member of the specified set is
* contained in this set
*/
boolean equals(Object o);
/**
* Returns the hash code value for this set. The hash code of a set is
* defined to be the sum of the hash codes of the elements in the set,
* where the hash code of a null element is defined to be zero.
* This ensures that s1.equals(s2) implies that
* s1.hashCode()==s2.hashCode() for any two sets s1
* and s2, as required by the general contract(约定,合同,契约) of
*/
int hashCode();
/**
* Creates a {@code Spliterator} over the elements in this set.
* @since 1.8
*/
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT);
}
}
- set的一个实现类HashSet的实现
继承结构:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
HashSet 是 Set 接口的一个子类,主要的特点是:里面不能存放重复元素(元素不能重复),而且采用散列的存储方法,所以没有顺序。这里所说的没有顺序是指:元素插入的顺序与输出的顺序不一致。 使用重写 equals 和 hashcode 来实现自定义的类型的去重。Java 中规定,两个内容相同的对象应该具有相等的 hashcode,但是hashcode相等,不一定是同一个对象
那么问题来了,set与它的各个实现类是如何实现元素不重复的呢?散列的存储方式又是如何存储的呢?下面让我们通过java源码一探这两位神秘的大哥是如何实现的.
JDK API中是这样描述的:HashSet实现 Set 接口,由哈希表(实际上是一个 HashMap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用 null 元素, HashSet不是同步的(线程不安全),需要外部保持线程之间的同步问题。而从HashSet的构造函数也可以看出,它与HashMap的关系不一般,HashSet的构造函数如下:
/**
* Constructs a new, empty set; the backing HashMap instance has
* default initial capacity (16) and load factor (0.75).(默认容量为16,加载因子为0.75)
*/
public HashSet() {
map = new HashMap<>();
}
/**
* Constructs a new set containing the elements in the specified
* collection. The HashMap is created with default load factor
* (0.75) and an initial capacity sufficient to contain the elements in
* the specified collection
*/
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
/**
* Constructs a new, empty set; the backing HashMap instance has
* the specified initial capacity and the specified load factor.
*/
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
/**
* Constructs a new, empty set; the backing HashMap instance has
* the specified initial capacity and default load factor (0.75).
*/
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
/**
* Constructs a new, empty linked hash set. (This package private
* constructor is only used by LinkedHashSet.)
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
观察可知:HashSet与HashMap果然酷似双胞胎, 其实HashSet底层是通过HashMap实现的, 通过构造函数构造出了一个HashMap
3-1 添加元素的实现
函数add(E e)实现元素的插入
/**
* Adds the specified element to this set if it is not already present.
* If this set already contains the element, the call leaves the set
* unchanged and returns false.
* @param e element to be added to this set
* @return true if this set did not already contain the specified element
*/
public boolean add(E e) {
//它的value始终是PRESENT
return map.put(e, PRESENT)==null;
}
// Dummy(傀儡,假的) value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
3-2 移除元素remove(Object o)的实现
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
/**
* Removes the mapping for the specified key from this map if present.
* @param key key whose mapping is to be removed from the map
* @return the previous value associated with key
*/
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
/**
* Implements Map.remove and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to match if matchValue, else ignored
* @param matchValue if true only remove if value is equal
* @param movable if false do not move other nodes while removing
* @return the node, or null if none
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) { // 遍历桶位,也就是散列表的数组部分
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) //找到桶位
node = p;
else if ((e = p.next) != null) { //桶位后面存在链表节点
if (p instanceof TreeNode) // 如果是采用红黑数的模式存储
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else { // 链表结构存储
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) { //在链表里面找到元素
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) { //红黑数存储模式
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node; //返回移除的节点
}
}
return null;
}
通过以上分析不难得出HashSet的特点了 : 元素不能重复 , 而且采用散列的存储方法,所以没有顺序。这里所说的没有顺序是指:元素插入的顺序与输出的顺序不一致.