验证码识别(一)图片预处理-全国高校计算机能力挑战赛(基于tensorflow+python+opencv)
验证码识别-全国高校计算机能力挑战赛(基于tensorflow+python+opencv)(一)
- 赛题介绍
- 题目分析
- 文件目录
- 参数配置
- 图片读取
- 灰度化和图像增强
- 总结
- 联系我们:
赛题介绍

这是今年全国高校计算机能力挑战赛-人工智能算法赛的题目,功能是实现验证码识别,目前的准确率单模型最高是97.2%,融合模型还没来得及提交比赛就结束了,,,(泪目(ㄒoㄒ))。整个题目分成几部分讲:
- 读取图片和图片预处理;
- 搭建VGG神经网络;
- 开始训练和一些训练技巧;
- 制作新数据集和数据增强;
- 模型融合;

这一部分讲一下读取数据和数据预处理,包括:
- 读取图片及其标签并保存其路径为pkl文件,以及实现迭代batch的功能(注意要把一张图片切成四个单独的图片);
- 使用中值滤波去除噪点,再使用不同的灰度化方法(包括:opencv自带的灰度化函数,最大灰度化法,加权平均灰度化法和均值灰度化法)将图片转换成灰度图,并通过伽马变换实现图像增强;
- 通过开运算(先腐蚀再膨胀)去除干扰线;
题目分析
题目分析详见官网说明,这里就简单分析几点吧~:

-
验证码类别分类较多 ,52个大小写字母➕10个数字共62个分类,但是验证码像素较低(40*120大小);
-
一些大小写字母难以区分 ,如图,,,(反正我是看不出来/(ㄒoㄒ)/~~,而且zZ2这样的人眼也很难识别);

-
个别图片背景和文字颜色相近 ,如图:

-
乱七八糟的干扰线和干扰点;
-
数据少 ,只有5000张训练集;
-
文字有一定的偏移 。
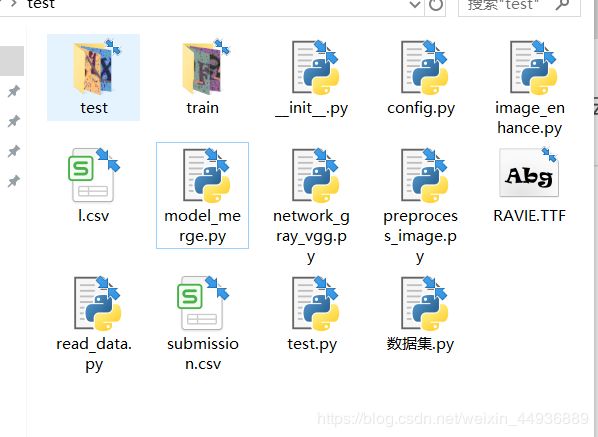
文件目录
文件目录如图,数据集可以从百度云下载:
链接: https://pan.baidu.com/s/1TbQWMdSNMWNlGchh_ouD7g 提取码: gah2
参数配置
我习惯把参数放在一个config.py文件中,这样改参数只需要在这里改就ok,不用再去每个程序找了。在其他程序中调用方法为: import config as cfg,然后用cfg.参数名即可引用该参数。
config.py
# config.py
import numpy as np
GAMMA = 1.6 # 伽马变换参数
NORM = True # 是否进行归一化
LEARNING_RATE = 2e-4 # 学习率
KEEP_RATE = 0.95 # drop_out的keep_prob参数,防止过拟合
IMAGE_BATCH = 128 # 每次训练batch的大小
BATCH_NUM = 256 # 每次训练迭代batch的数目
STOP_ACC = 0.99 # early_stop,即valid集准确率达到99%时停止训练
RGB_WEIGHTS = np.array([0.229, 0.578, 0.114]) # 加权灰度化的权重
START_POINT = [5, 30, 55, 80] # 切割验证码为四个小图片的起始点(手动测得)
ADD_NUM = 1000 # 额外增加的数据量
TEST_NUM = 1000 # 训练集分离出来,用于验证鲁棒性
HEIGHT = 40 # 图片高度
WIDTH = 32 # 裁剪成小图片的宽度
TRAIN_STEPS = 2000 # 迭代次数
PKL_PATH = './train_data.pkl' # 训练集数据保存文件路径
TRAIN_PATH = './train/' # 训练集图片路径
TEST_PATH = './test/' # 测试集图片路径(无标签)
MODEL_PATH = './model/' # 模型保存路径
IMAGE_NUMS = 5000 # 数据集总数
CLASSES = {
'0': 0, '1': 1, '2': 2,
'3': 3, '4': 4, '5': 5,
'6': 6, '7': 7, '8': 8,
'9': 9,
'a': 10, 'b': 11,
'c': 12, 'd': 13, 'e': 14,
'f': 15, 'g': 16, 'h': 17,
'i': 18, 'j': 19, 'k': 20,
'l': 21, 'm': 22, 'n': 23,
'o': 24, 'p': 25, 'q': 26,
'r': 27, 's': 28, 't': 29,
'u': 30, 'v': 31, 'w': 32,
'x': 33, 'y': 34, 'z': 35,
'A': 36, 'B': 37,
'C': 38, 'D': 39, 'E': 40,
'F': 41, 'G': 42, 'H': 43,
'I': 44, 'J': 45, 'K': 46,
'L': 47, 'M': 48, 'N': 49,
'O': 50, 'P': 51, 'Q': 52,
'R': 53, 'S': 54, 'T': 55,
'U': 56, 'V': 57, 'W': 58,
'X': 59, 'Y': 60, 'Z': 61
} # 类别
IDs = {} # 每个数字对应的字母(或数字)
for key, value in CLASSES.items():
IDs.update({value: key})
图片读取
读取图片定义了一个Reader类,文件是read_data.py,功能是读取train文件夹下的存有标签的csv文件读取,并将图片路径、标签保存在train.pkl文件中;同时也会读取test(测试集)文件夹下的图片,标签记为空。Reader下的generate方法生成训练时迭代需要的训练集图片和label。
程序里面有几点要注意:
1、preprocess_image是自己定义的一个预处理图片程序,下面会详细讲,这里知道是把RGB图片变成灰度图即可;
2、./pic_data/ 文件夹下保存自己生成的验证码图片,在最后一篇会提到生成方法,如果自己需要训练的话可以在路径下创建这个文件夹,不需要放入图片;
先上代码:
# read_data.py
import pandas as pd
import os
import pickle
import numpy as np
import config as cfg
import cv2
from random import shuffle, randint
from preprocess_image import image_process
class Reader(object):
def __init__(self):
self.train_path = cfg.TRAIN_PATH
self.train_save_path = './train_data.pkl'
self.test_save_path = './test_data.pkl'
if not os.path.exists(self.train_save_path):
self.pre_process()
with open(self.train_save_path, 'rb') as f:
self.train_dict = pickle.load(f)
with open(self.test_save_path, 'rb') as f:
self.test_dict = pickle.load(f)
shuffle(self.train_dict)
shuffle(self.test_dict)
self.cursor = 0 # 当前游标(在训练集上滑动)
self.batch_size = cfg.IMAGE_BATCH
self.cls_num = len(cfg.CLASSES)
self.epoch = 0 # 当前的epoch
self.length = cfg.WIDTH
def pre_process(self):
train_data = pd.read_csv(self.train_path+'train_label.csv') # 读取训练数据
train_data = train_data.to_dict(orient='records')
for i in range(len(train_data)):
train_data[i]['ID'] = self.train_path + train_data[i]['ID']
new_train_data = self.read_directory('./pic_data/')
train_data.extend(new_train_data[:cfg.ADD_NUM])
with open(self.train_save_path, 'wb') as f:
pickle.dump(train_data[cfg.TEST_NUM:], f)
with open(self.test_save_path, 'wb') as f:
pickle.dump(train_data[:cfg.TEST_NUM], f)
def generate(self, batch_size, s=cfg.START_POINT, is_training=True):
value = {}
batch_images = []
batch_labels = []
batch_index = 0
while batch_index < batch_size:
# 取一个batch
if is_training:
image_path = self.train_dict[self.cursor]['ID']
label = self.train_dict[self.cursor]['label']
else:
image_path = self.test_dict[batch_index]['ID']
label = self.test_dict[batch_index]['label']
# image_path = self.train_path + ID
image = cv2.imread(image_path)
# image = image_process(image)
tmp = randint(0, 2)
image = self.moving(image)[tmp] # 随机上下偏移
label = self.transform_label(label)
self.cursor += 1
if self.cursor >= len(self.train_dict):
# 如果取完一遍,则打乱顺序并且游标归零
np.random.shuffle(self.train_dict)
self.cursor = 0
self.epoch += 1
batch_images.append(
np.stack(
[image[:, s[0]:s[0]+self.length],
image[:, s[1]:s[1]+self.length],
image[:, s[2]:s[2]+self.length],
image[:, s[3]:s[3]+self.length]]
)
) # 把验证码裁剪成四个小图分别验证
batch_labels.append(label)
batch_index += 1
value = {'images': np.stack(batch_images).reshape(
(batch_size*4, 40, self.length, 3)
),
'labels': np.stack(batch_labels).reshape(
(batch_size*4, self.cls_num)
)}
value_list = []
for i in range(batch_size*4):
tmp = image_process(value['images'][i])
value_list.append(tmp)
value_list = np.stack(value_list)
value['images'] = np.expand_dims(value_list, axis=-1)
return value
def transform_label(self, label):
one_hot = np.zeros((4, self.cls_num))
for i, value in enumerate(label):
num = cfg.CLASSES[value]
one_hot[i, num] = 1
return one_hot # 把标签转换成one_hot表示
def decode_label(self, label, IDs=cfg.IDs):
ids = np.argmax(label)
str_label = cfg.IDs[ids]
return str_label
def moving(self, image, bias=2):
# 图片随偏移
size = image.shape
image3 = image.copy()
image4 = image.copy()
image3 = np.concatenate(
(image3[bias:, :], image3[:bias, :]), axis=0) # 上
image4 = np.concatenate(
(image4[size[0] - bias:, :], image4[:size[0] - bias, :]), axis=0) # 下
return image, image3, image4
def read_directory(self, directory_name):
data = []
for filename in os.listdir(directory_name):
# print(filename)
path = directory_name + filename
label = filename[:4]
tmp = {'ID': path, 'label': label}
data.append(tmp)
return data
1、pre_process 方法检测是否读取过图片,没有则读取训练集并保存为pkl文件;
2、generate 方法生成训练的一个batch的图片及其标签;
3、transform_label 方法把标签(A,f,9这样的)转换成向量的one_hot表示;
4、decode_label 方法跟 transform_label 正好相反;
5、moving 方法对图片随机上下平移,做一些数据增强;
6、read_dictory 方法读取额外生成的训练集(这里没有讲就pass掉先);
灰度化和图像增强
灰度化和增强
image_enhance.py 程序,功能是对图片进行灰度化和伽马变换(使灰度图看起来对比度更高一点)
# image_enhance.py
import cv2
import numpy as np
import config as cfg
def max_gray(image):
# 最大灰度化方法
b, g, r = cv2.split(image)
index_1 = b > g
result = np.where(index_1, b, g)
index_2 = result > r
result = np.where(index_2, result, r)
return result
def mean_gray(image):
# 平均灰度化方法
return np.mean(image, axis=-1)
def weight_gray(image):
# 加权平均灰度化方法
w = cfg.RGB_WEIGHTS
image = np.sum(image*w, axis=-1)
return image
def enhance_value_max(image, gamma=1.6, norm=True):
image = cv2.medianBlur(image, 3)
image = max_gray(image)
# gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
dst = enhance(image, gamma=gamma, norm=norm)
return dst
def normalize(a):
# 归一化
amin, amax = a.min(), a.max() # 求最大最小值
result = (a-amin)/(amax-amin) # (矩阵元素-最小值)/(最大值-最小值)
return result
def enhance(image, gamma=1.6, norm=True):
# 伽马变换
fI = (image+0.5)/256
fI = fI + np.median(fI)
dst = np.power(fI, gamma)
if norm:
dst = normalize(dst)
return dst
去除干扰线
先看preprocess_image.py,功能是将灰度化和伽马变换处理过的图片上的干扰线去掉:
# preprocess_image.py
import cv2
import image_enhance as en
import numpy as np
import config as cfg
def image_process(image):
image = en.enhance_value_max(image, gamma=cfg.GAMMA, norm=cfg.NORM)
image += ercode_dilate(image, 3)
# 为什么是加呢,因为去掉干扰线的同时也可能去掉字母比较细的地方
return image
def ercode_dilate(img, threshold):
# 腐蚀参数, (threshold, threshold)为腐蚀矩阵大小
kernel = np.ones((threshold, threshold), np.uint8)
# 腐蚀图片
img = cv2.dilate(img, kernel, iterations=1)
# 膨胀图片
img = cv2.erode(img, kernel, iterations=1)
return img
处理效果大概如图啦(emmm似乎干扰线去除的不是很好,但是对比一下没调用开运算的结果还是可以接受的)~




总结
到这里图片预处理就结束啦~
-
读取图片和图片预处理;
-
搭建VGG神经网络;
-
开始训练和一些训练技巧;
-
制作新数据集和数据增强;
-
模型融合;
-
剩下的明天更新,绝不咕咕咕
-
AND 可能大佬们有别的思路,欢迎指教~
联系我们:
权重文件需要的请私戳作者~
联系我时请备注所需模型权重,我会拉你进交流群~
该群会定时分享各种源码和模型,之前分享过的请从群文件中下载~