ubuntu18.04下用yolo训练自己的数据集
ubuntu18.04下用yolo训练自己的数据集并进行检测
收集数据集并标注
数据集的量对于检测的准确度有很高的影响,所以应该尽可能的获取较多的数据集。这里,我从百度图片上获得了92张夏洛特中的动漫人物——友利奈绪的图片。
之后在windows下用labelImg软件进行标注:

本文的工作分为两端进行,在windows下完成数据集的搜集,再将其标注好后传输进ubuntu(本想在nano中跑训练,结果失败了,后续表明原因)内。
在dasknet-master文件夹下,将数据集按照如下图文件夹格式放置:

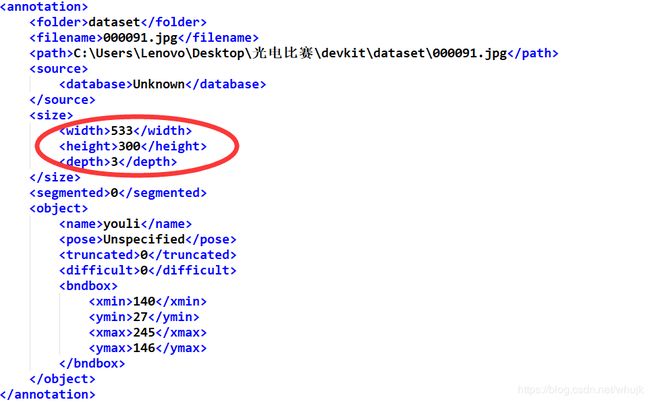
其中Annotations下面放置标注后的xml文件,JPEGImages里面放原图片,ImageSets里面放置Main文件夹,里面的vol.txt,train.txt存放训练集和验证集的图片名。
/////////
后续可能遇到的问题
标注时也发现了一些会导致后续工作出错的问题:
一些xml文件中的下面画框区域会出现width,height为0的情况,导致后续工作出错。
解决办法可以手动查看标注的图片的像素,将其width,height对应位置调整。
大多数博客都建议在自己的PC端进行模型的训练。我也用nano跑训练尝试了一下:
sudo init 3
#进入纯命令行界面,释放图形界面占用的内存
cd darknet-master
./darknet detector train cfg/voc.data cfg/yolov3-tiny.cfg yolov3-tiny.conv.15
后续中运行以上代码,结果是PC端不跑训练的话,nano根本跑不起来,本机跑到19层的时候发烫然后系统保护自动重启。因此建议还是转到自己的PC端进行训练。

/////////
安装CUDA,CUDNN,NVIDIA驱动,pytorch,opencv
这一步是必须的,也是最痛苦的,常常由于版本号对不住而导致出错。建议搭建先从驱动开始,然后从驱动里面看需要的cuda版本(第一遍自己找的cuda,结果版本不对,后面一直出错),方法我采用官网下载驱动.run文件,之后在开机选项的setup里面关闭security boot,原本默认为enabled,改为disabled,不然挂载会失败。
安装驱动中,先禁用nouveau第三方驱动,打开编辑配置文件: sudo vim /etc/modprobe.d/blacklist.conf,在最后一行添加:blacklist nouveau,改好后执行命令:sudo update-initramfs -u,重启使之生效:reboot。
之后进入驱动的run文件所在目录:
sudo chmod a+x NVIDIA-Linux-x86_64-440.82.run
sudo ./NVIDIA-Linux-x86_64-390.25.run -no-opengl-files -no-x-scheck -no-nouveau-check
modprobe nvidia
nvidia-smi#查看是否安装成功
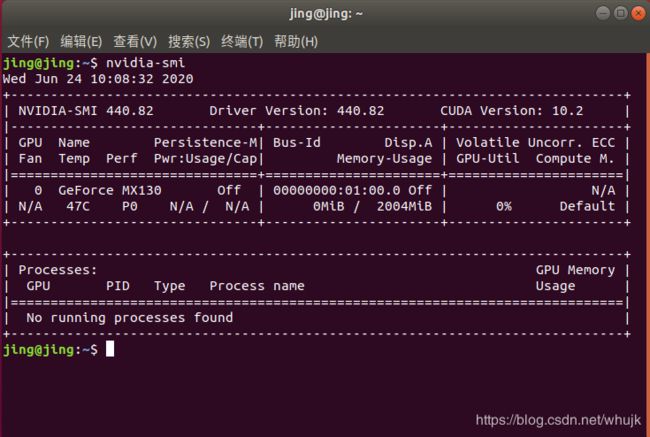
CUDA、CUDNN我根据驱动显示结果使用了cuda-10.2,cudnn在官网中选择适合的就行,这里注意cudnn的安装需要注册NVIDIA账号。这些安装就不再多说了,比较简单。
驱动可以在window的任务管理器下找到自己的GPU型号后,进入官网搜索合适的驱动文件.run。之后再下载。如图可以看到我的GPU1下面便是我的显卡型号:NVIDIA GeForce Mx130(很菜的一个显卡,但是依然支持CUDA,所以大多数博客上说的查询是否支持CUDA基本没必要。)
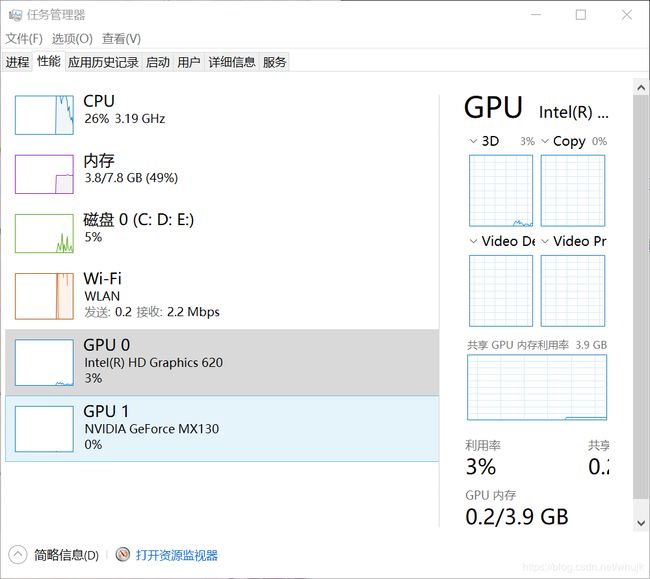
下载之后的安装中,就根据报错,找各种东西来补,这里提出一个比较坑的地方,双系统的secure boot默认是enable状态,这种情况会阻止NVIDIA驱动的安装,因此导致安装失败,需要禁用boot。(禁用手段自己再搜索)
最后,附上Yolov4检测成功图片。
而pytorch的安装则比较简单,进入pytorch官网,找到适合cuda-10.2版本的pytorch,安装按官方说明安装即可。
sudo pip3 install torch torchvision
而opencv的安装就是
pip3 install opencv-python
sudo apt-get install libopencv-dev
#补充一点opencv必须的依赖
顺带一提,我的python是3.6.9。ubuntu18.04.4自带的,如果有升级python或者其他版本的需另行对照版本。
/////////
配置相关文件
- 在上述完成后,在自己的ubuntu下修改scripts文件夹下的vol_label.py文件


数据集sets修改:我们生成的数据集为训练集和验证集,且其版本为2012版本。
分类classes:我们只检测一种目标 “youli”,如果数据集中有标注多个目标,这里需要添加数量。
执行voc_lable.py脚本,我们就会在scripts/下生成 2012_train.txt 、2012_val.txt 、train.txt三个文件,以及在数据集 scripts/VOCdevkit/VOC2012/labels 生成了每一个图片数据的标签文件
-
之后修改darknet-master/data/voc.names和darknet-master/cfg/voc.data
最好先做好备件。或者可以在最初的darknet文件夹直接复制一个新的出来,在里面做自己的更改,一些基本的功能都不会因此变化。
voc.data的修改:(voc.names只需要把原本的类别删去,输入自己的类别,本博客为youli)

-
修改yolov3-tiny.cfg。
修改~/darknet-master/cfg目录下的yolov3-tiny.cfg文件
现在我们需要训练模型,不需要测试,所以将yolov3-tiny.cfg中的Testing下面的batch=1、subdivisions=1注释,将Training下面两行的注释取消:

另外,可以提高subdivision来降低对显卡的需求,本博客设置为32。而将classes=1 ,因为我们只有一类,根据公式filters=3*(classes+5),因为我们的classes=1,所以filters=18。找到相关的进行修改,因为之前的classes为80,我们再找到对应的filters=255进行修改即可。
降低batch也可以降低对显卡的需求,而且还有max_batches以及下面对应的steps最好也做一下修改,基本按照A=max_batches=2000✖(类别数目),steps=0.8✖A,0.9✖A的原则,但是A一般取值>=4000。本博客设置为4000。
-
生成预训练模型
./darknet partial cfg/yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15训练模型
./darknet detector train cfg/voc.data cfg/yolov3-tiny.cfg yolov3-tiny.conv.15 | tee train.txt #后面的命令属于输出一个文本文件,非必须。训练一段时间后,我们可以按‘ctrl+c’手动结束模型训练,然后可以在backup中找到相应的训练模型.
不过可能由于未设置好一些方面,训练层数不足100层,得不到权重文件。(一般这些权重文件都要循环100次才进行保存且保存在一个_last.weights文件中,1000次后才会另外生成权重文件,之前跑tensorflow里面的record文件也是如此。)
-
也可以尝试选择新的预训练模型darknet53.conv.54,用yolov3-voc.cfg来进行训练。所需修改的配置只有yolov3-voc.cfg。但是这些内存要求更高,我的电脑都没能跑起来。
/////////
检测自己的图片
在得到权重文件后,就可以检测自己的图片了,这个步骤可以就放在nano端进行了。但是也需要修改nano端的.cfg,.data,.names文件。
例如
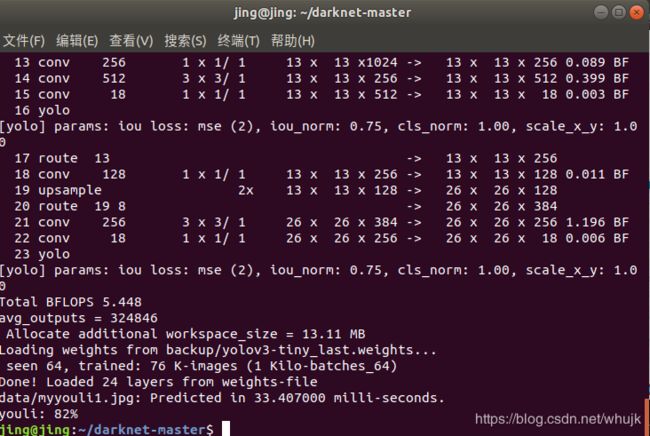
./darknet detect cfg/yolov3-tiny.cfg backup/yolov3-tiny_last.weights data/myyouli.jpg
结果奉上:


还有命令行的结果: