caffe学习记录(三):多标签分类/回归训练(下)
接上篇。
我们已经为caffe添加了多标签分类训练功能,多标签分类的训练过程和单标签非常相似,同样包含以下几个步骤:
一、准备多标签分类/回归训练的数据集(train.txt,val.txt,test.txt)
这里我们以MTCNN人脸检测网络中的P-Net训练为例,P-Net需要同时输出人脸框的分类置信度(相当于一个二分类问题)和平移缩放参数(相当于一个回归问题),它的训练数据应该包含如下格式:
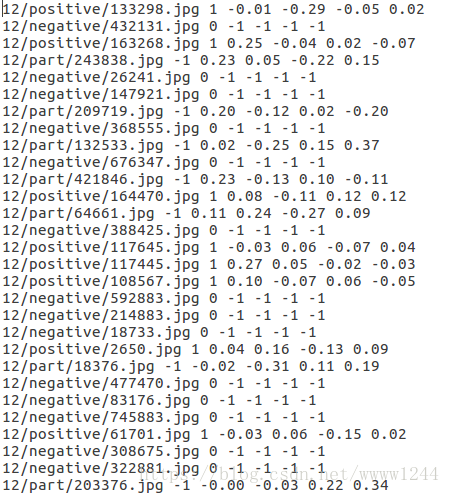
其中,五个标签数据中的第一个用于分类训练,剩下的四个用于回归训练(暂时忽略其中的-1项。。)。
二、生成lmdb数据集
可以参考这里的脚本,修改可执行文件为$CAFFE_PATH/build/tools/convert_imageset_multi(这是我们在上文中生成的可执行文件),其余操作不变。
#!/usr/bin/env sh
CAFFE_PATH=... # caffe路径
IMG_PATH=... # 数据集文件夹
LMDB_PATH=... # 工程文件夹
echo "Create train lmdb.."
rm -rf $LMDB_PATH/img_train_lmdb
$CAFFE_PATH/build/tools/convert_imageset_multi \
--shuffle \
--resize_height=12 \ # 图片尺寸
--resize_width=12 \
$IMG_PATH \
$LMDB_PATH/train.txt \
$LMDB_PATH/img_train_lmdb
echo "Create test lmdb.."
rm -rf $LMDB_PATH/img_test_lmdb
$CAFFE_PATH/build/tools/convert_imageset_multi \
--shuffle \
--resize_width=12 \
--resize_height=12 \
$IMG_PATH \
$LMDB_PATH/val.txt \
$LMDB_PATH/img_test_lmdb
echo "Create meanfile.."
rm -rf $LMDB_PATH/mean.binaryproto
$CAFFE_PATH/build/tools/compute_image_mean \
$LMDB_PATH/img_train_lmdb \
$LMDB_PATH/mean.binaryproto
echo "All Done.."
三、生成均值文件(可以不使用均值文件),参考上面的脚本最后几行
四、修改train_val.prototxt
同样要注意Data Layer和Loss Layer的修改
1. Data层
我们使用一个Data层加载数据集,此时label应是一个(batch_size * label_num * 1 * 1)的矩阵,在我们修改caffe源码之前,label的尺寸应该固定为(batch_size * 1 * 1 * 1) 。
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: false # 回归问题中不使用镜像,这样会导致图像坐标出错(可以直接删掉这一行)
crop_size: 12 # 如果事先已经将图片裁剪到这一尺寸,这一行也可以删除
mean_file: "/home/.../mean.binaryproto" # 改成绝对路径
}
data_param {
source: "/home/.../img_train_lmdb"
label_num: 5 # 标签数量(我们新添加的参数)
batch_size: 64
backend: LMDB
}
}我们需要将不同类型的标签输入到不同的loss层中,因此需要利用一个slice层对label进行分割:
layer {
name: "slice"
type: "Slice"
bottom: "label"
top: "label_cls"
top: "label_box"
include {
phase: TRAIN
}
slice_param {
axis: 1
slice_point: 1
}
}其中,axis表示要分割的维度(0是第一维,1是第二维……显然,我们需要对第二维进行分割),
slice_point表示分割点,可以设置多个,有几个分割点就会对应n+1个top,1可以理解为将从第二个数往后的部分分割出去。
总之,最后,我们会得到一个label_cls (batch_size * 1 * 1 * 1)和一个label_box (batch_size * 4 * 1 * 1)的矩阵,分别用于分类和回归,后面的操作就非常简单了。
2. Loss层
考虑我们要解决的问题,需要用到两种loss,分别是SoftmaxLoss和EuclideanLoss(欧式距离),添加这两个loss层:
layer {
name: "loss_cls"
type: "SoftmaxWithLoss"
bottom: "conv4-1"
bottom: "label_cls"
top: "loss_cls"
loss_weight: 1
}
layer {
name: "loss_box"
type: "EuclideanLoss"
bottom: "conv4-2"
bottom: "label_box"
top: "loss_box"
loss_weight: 0.5
}还可以再添加一个Accuracy层用于测试分类准确率,回归效果就只能根据loss进行判断了:
layer {
name: "accuracy"
type: "Accuracy"
bottom: "conv4-1"
bottom: "label_cls"
top: "accuracy_cls"
include {
phase: TEST
}
}
五、最后,修改solver.prototxt,设置网络超参数,这里没有什么特别需要指出的。
对于一般的多标签分类问题,到这里就可以调用caffe可执行文件开始训练了。