刘二大人《PyTorch深度学习实践》p9多分类问题
刘二大人《PyTorch深度学习实践》p9多分类问题
- 一、零碎知识点
-
- 1.LongTensor长整形张量
- 2.transform结构及用法
- 二、预备知识
-
- 1.Softmax激活函数
- 2.NLLLoss损失函数
- 3.CrossEntropyLoss()
- 4.随堂练习CrossEntropyLoss vs NLLLoss
- 三、课程代码
-
- 1.函数名问题导致的运行错误
- 2.课程代码
一、零碎知识点
1.LongTensor长整形张量
torch.LongTensor是一种用于表示整数类型的张量(tensor)。
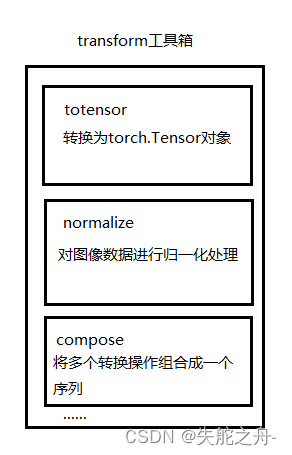
2.transform结构及用法
from torchvision import transforms
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) # 归一化
# 均值0.1307 标准差0.3081
])
transforms.Compose函数
将多个转换操作组合成一个序列(pipeline),并按顺序依次对数据进行转换。transforms.ToTensor()
这个操作将图像数据从原始的PIL.Image对象转换为torch.Tensor对象,将图像数据的像素值从范围0-255缩放到范围0-1之间。transforms.Normalize()
这个操作对图像数据进行归一化处理,MNIST手写数据集其均值为0.1307,标准差为0.3081。归一化操作通过减去均值,并将结果除以标准差来完成。
二、预备知识
1.Softmax激活函数
Softmax是一种常用的激活函数,常用于多类别分类问题中。
Softmax函数将原始的实数向量转换为表示概率分布的向量,使每个元素的取值范围≥0,并且所有元素的和等于1。

Softmax函数的定义如下:
对于输入向量 z = ( z 1 , z 2 , … , z k − 1 ) \mathbf{z} = (z_1, z_2, \ldots, z_{k-1}) z=(z1,z2,…,zk−1),Softmax函数对应的输出向量 y = ( y 1 , y 2 , … , y n ) \mathbf{y} = (y_1, y_2, \ldots, y_n) y=(y1,y2,…,yn) 的计算公式为:
y i = e z i ∑ j = 0 k − 1 e z j y_i = \frac{e^{z_i}}{\sum_{j=0}^{k-1} e^{z_j}} yi=∑j=0k−1ezjezi
其中, e e e 是自然对数的底。 y i y_i yi 表示输入向量 z \mathbf{z} z 属于类别 i i i 的概率。
举例:

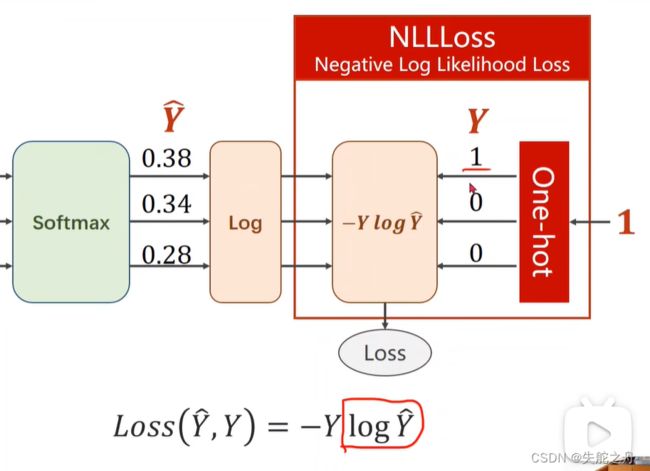
2.NLLLoss损失函数
NLLLoss(Negative Log Likelihood Loss)负对数似然损失是PyTorch中用于多类别分类问题的损失函数。
计算公式如下:
L o s s ( Y , Y ^ ) = − Y log Y ^ Loss(Y, \hat{Y}) = - Y \log\hat{Y} Loss(Y,Y^)=−YlogY^
3.CrossEntropyLoss()
CrossEntropyLoss是PyTorch中的一个损失函数,常用于多分类问题的训练中。它结合了Softmax激活函数和负对数似然损失(NLLLoss),能够同时计算预测类别的概率分布和真实标签之间的差异。(好狠,直接包含1和2两个功能)

举例:
我们给出两组预测Y_pred1,Y_pred2:

import torch
criterion = torch.nn.CrossEntropyLoss()
Y = torch.LongTensor([2, 0, 1])
Y_pred1 = torch.Tensor([[0.1, 0.2, 0.9],
[1.1, 0.1, 0.2],
[0.2, 2.1, 0.1]])
Y_pred2 = torch.Tensor([[0.8, 0.2, 0.3],
[0.2, 0.3, 0.5],
[0.2, 0.2, 0.5]])
l1 = criterion(Y_pred1, Y)
l2 = criterion(Y_pred2, Y)
print("Batch Loss1 = ", l1.data)
print("Batch Loss2 = ", l2.data)

损失越小表示模型的预测结果与真实标签之间的差异越小,即预测越准确。
4.随堂练习CrossEntropyLoss vs NLLLoss
学习链接:
CrossEntropyLoss
NLLLoss
CrossEntropyLoss是包括softmax激活函数和NLLLoss函数的一种损失函数。
NLLLoss用于测量模型预测的概率分布与真实标签之间的差异。
如果模型的输出已经经过log_softmax函数处理,或者你手动对模型输出进行log_softmax处理,可以使用NLLLoss,取决于咱们的具体需求。
三、课程代码
1.函数名问题导致的运行错误
照着老师的代码打的一直运行不成功,test这个函数名得改一下


修改:
2.课程代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) # 归一化
# 均值0.1307 标准差0.3081
])
train_dataset = datasets.MNIST(root='dataset/mnist',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
test_dataset = datasets.MNIST(root='dataset/mnist',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_dataset,
shuffle=True,
batch_size=batch_size)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d %5d]loss:%.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def practice():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set:%d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
practice()
