可变形的卷积网络
原文链接:Deformable Convolutional Networks
代码链接:https://github.com/msracver/Deformable-ConvNets
一、首先看看文章的摘要
由于构造卷积神经网络 (CNN) 所用的模块中几何结构是固定的,其几何变换建模的能力本质上是有限的。在我们的工作中,我们引入了两种新的模块来提高卷积神经网络 (CNN) 对变换的建模能力,即可变形卷积 (deformable convolution) 和可变形兴趣区域池化 (deformable ROI pooling)。它们都是基于在模块中对空间采样的位置信息作进一步位移调整的想法,该位移可在目标任务中学习得到,并不需要额外的监督信号。新的模块可以很方便在现有的卷积神经网络 (CNN) 中取代它们的一般版本,并能很容易进行标准反向传播端到端的训练,从而得到可变形卷积网络 (deformable convolutional network)。大量的实验验证了我们的方法在目标检测和语义分割这些复杂视觉任务上的有效性。
二、进一步的分析
这是一种对传统方块卷积的改进核,本质是一种抽样改进。
谈到抽样,人脑好像天生知道如何抽样获得有用特征,而现代机器学习就像婴儿一样蹒跚学步。我们学会用cnn自动提取有用特征,却不知用什么样的卷积才是最有效的。我们习惯于方块卷积核窗口,而Jifeng Dai的work认为方块不是最好的形状。
标准卷积中的规则格点采样是导致网络难以适应几何形变的“罪魁祸首”。为了削弱这个限制,研究员们对卷积核中每个采样点的位置都增加了一个偏移的变量。通过这些变量,卷积核就可以在当前位置附近随意的采样,而不再局限于之前的规则格点。这样扩展后的卷积操作被称为可变形卷积(deformable convolution)。
三、用图说话
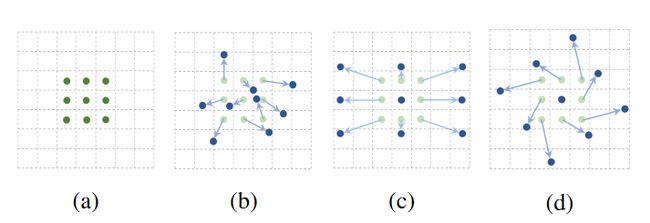
图1:展示了卷积核大小为 3x3 的正常卷积和可变形卷积的采样方式,(a) 所示的正常卷积规律的采样 9 个点(绿点),(b)(c)(d) 为可变形卷积,在正常的采样坐标上加上一个位移量(蓝色箭头),其中(c)(d) 作为 (b) 的特殊情况,展示了可变形卷积可以作为尺度变换,比例变换和旋转变换的特殊情况
事实上,可变形卷积单元中增加的偏移量是网络结构的一部分,通过另外一个平行的标准卷积单元计算得到,进而也可以通过梯度反向传播进行端到端的学习。加上该偏移量的学习之后,可变形卷积核的大小和位置可以根据当前需要识别的图像内容进行动态调整,其直观效果就是不同位置的卷积核采样点位置会根据图像内容发生自适应的变化,从而适应不同物体的形状、大小等几何形变。然而,这样的操作引入了一个问题,即需要对不连续的位置变量求导。作者在这里借鉴了之前Spatial Transformer Network和若干Optical Flow中warp操作的想法,使用了bilinear插值将任何一个位置的输出,转换成对于feature map的插值操作。同理,类似的想法可以直接用于 (ROI) Pooling中改进。

Figure 2 展示了可变形卷积框架,首先通过一个小卷积层(绿色)的输出得到可变形卷积所需要的位移量,然后将其作用在卷积核(蓝色)上,达到可变形卷积的效果。

Figure 3 展示了可变形兴趣区域池化框架。首先通过标准的兴趣区域池化(绿色)获得兴趣区域对应的特征,该特征通过一个全连接层得到兴趣区域每个部位的位移量。用该位移作用在可变形兴趣区域池化(蓝色)上,以获得不局限于兴趣区域固定网格的特征
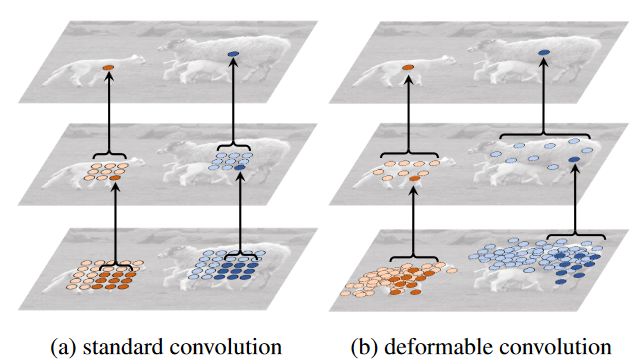
Figure 4 展示了两层结构,拥有标准固定感受野的卷积层 (a) 与拥有自适应感受野的可变性卷积层(b)。最上方是两个在不同大小的物体上的激活单元,中间是该单元所需的采样位置,最下方是中间的采样点分别所需的采样位置

Figure 5 对可变形卷积的效果进行了可视化,其中左中右分别展示了激活单元(绿点)倒推三层可变形卷积层以后在背景/小物体/大物体上的所采样的点

Figure 6 对可变形兴趣区域池化的效果进行可视化,使用了 R-FCN,兴趣区域网格大小为 3x3,可以发现现在池化区域基本覆盖在物体上。
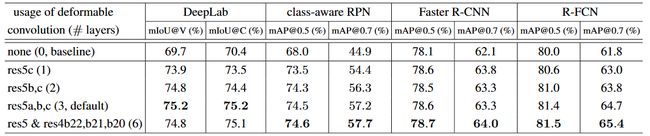
Table 1 在各种方法和各种数据集上,使用不同层数的可变形卷积对结果带来的影响,其中 DeepLab 在 VOC2012 与 Cityscapes 的训练集上进行训练,在验证集上进行测试,class-aware RPN, Faster R-CNN 与 R-FCN 在 VOC2007 与 VOC2012 的训练验证集上进行训练,在 VOC2007 的测试集上进行测试。
四、可变卷积网络的新思路:简明深刻的网络结构变革
可变形卷积单元具有诸多良好的性质。它不需要任何额外的监督信号,可以直接通过目标任务学习得到。它可以方便地取代任何已有视觉识别任务的卷积神经网络中的若干个标准卷积单元,并通过标准的反向传播进行端到端的训练。是对于传统卷积网络简明而又意义深远的结构革新,具有重要的学术和实践意义。它适用于所有待识别目标具有一定几何形变的任务(几乎所有重要的视觉识别任务都有此特点,人脸、行人、车辆、文字、动物等),可以直接由已有网络结构扩充而来,无需重新预训练。它仅增加了很少的模型复杂度和计算量,且显著提高了识别精度。例如,在用于自动驾驶的图像语义分割数据集(CityScapes)上,可变形卷积神经网络将准确率由70%提高到了75%。
此外,通过增加偏移量来学习几何形变的思想还可方便地扩展到其它计算单元中去。例如,目前业界最好的物体检测方法都使用了基于规则块采样的兴趣区域(region of interests, ROI)池化(pooling)。在该操作中,对于每个采样的规则块增加类似的偏移量,从而得到可变形兴趣区域池化 (deformable ROI pooling)。由此所获得的新的物体检测方法也取得了显著的性能提升。
近年来,与神经网络结构相关的研究工作层出不穷,大多是对于各种基本网络单元连接关系的研究。不同于大部分已有的工作,可变形卷积网络首次表明了可以在卷积网络中显式地学习几何形变。它修改了已使用二十余年的基本卷积单元结构,在重要的物体检测和语义分割等计算机视觉任务上获得了重大的性能提升。
可以想象,在不远的未来,在更多的计算机视觉识别任务中(如文字检测、视频物体检测跟踪等)都将看到它的成功应用。