JAVA中的对象的序列化格式
JAVA中的对象的序列化
1.网络传输时对象要序列化,而字符串就不用序列化
网络传输会将对象转换成字节流传输,序列化可以将一个对象转化成一段字符串编码,以便在网络上传输或者做存储处理,使用时再进行反序列。
字符串不用序列化的原因: 字符串是已经实现了Serializable接口的,所以它已经是序列化了的2.Java序列化格式详解
RPC的世界,由于涉及到进程间网络远程通信,不可避免的需要将信息序列化后在网络间传送,序列化有两大流派: 文本和二进制.
文本序列化
序列化的实现有很多方式,在异构系统中最常用的就是定义成人类可读的文本形式,其在开发时debug比较方便.
常见的有:
- 如通过http协议传送并用soap协议(实际形式为xml)封装的webservice方式.
- http传送,封装形式为json.
二进制序列化
二进制序列化会比较复杂,由于字节流只是一组101010,需要一个比较详细的协议来定义被序列化后的二进制流的每个字节的含义是什么.一般使用其原因是其在网络传送效率较高,但牺牲了可读性.
常见的有:
- Protocol Buffers
- Thrift
- Java序列化
重点介绍下java序列化. JDK1.1起,sun就有Java Object Serialization Specification定义java的序列化方式,根据文档,可以根据字节流读出序列化后的含义. 地址在这里.
借用一张java rmi的图解释一下其工作方式:
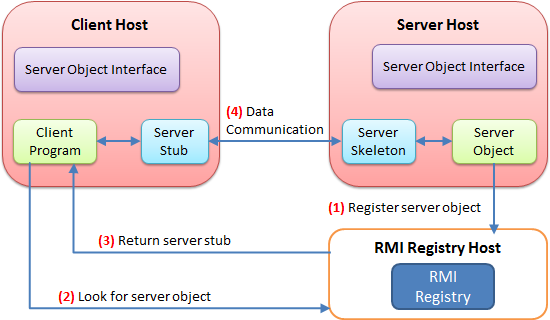
客户端与服务端都需要有实现了rmi接口的实现类,该接口在实际远程通信的时候作为一个桩类来处理网络通信的各种细节.而其传递的信息,就是java对象序列化后的二进制流.
读懂java序列化流
我们给一个简单的例子,定义一个简单实现了serializable接口的类:
class Pet implements Serializable{
private static final long serialVersionUID = 2L;
int paws;
}再写一段将Pet序列化到文件中的程序:
public class Main {
public static void main(String[] args) {
System.out.println("Hello World!");
Pet dto = new Pet();
File file = new File("/users/kunrong/p3.txt");
try {
ObjectOutputStream oout =
new ObjectOutputStream(new FileOutputStream(file));
oout.writeObject(dto);
} catch (IOException e) {
e.printStackTrace();
}
}
}什么也没干,直接将其内容输出到p3.txt文件中.运行后,由于序列化后写出的是二进制流,所以用能打开二进制文件的编辑器打开,在mac下我用的是HexMiner,免费.
这些是什么意思呢?先摘取部分协议文档定义的常量内容:
final static short STREAM_MAGIC = (short)0xaced;
final static short STREAM_VERSION = 5;
final static byte TC_CLASSDESC = (byte)0x72;
final static byte TC_OBJECT = (byte)0x73;
下面对照图中每个16进制
- 0xACED:根据协议文档的约定,由于所有二进制流(文件)都需要在流的头部约定魔数(magic number=STREAM_MAGIC),既java object 序列化后的流的魔数约定为ACED;
- 0x0005:然后是流协议版本是short类型(2字节)并且值为5,则十六进制值为0005;
- 0x7372:java byte型长度为1字节,所以0x73 0x72直接对应到字节流上,0x73(TC_OBJECT)代表这是一个对象,0x72(TC_CLASSDESC)代表这个之后开始是对类的描述.
- 0x0003:类名的长度,这个类名是Pet,是三个字符,所以长度是3,对应16进制中就是0x0003.
-
0x506574:这三个字节转为ASCII码就是类名Pet.

-
0x00 00 00 00 00 00 00 02: 由于序列化中标识类版本是这样定义的
private static final long serialVersionUID = 2L;
是long型,long在java中的定义是8字节,所以这里2L对应的二进制值就是这个. -
0x02: 关于classDescFlags的定义在协议文档是这样的:
The flag byte classDescFlags may include values of
final static byte SC_WRITE_METHOD = 0x01; //if SC_SERIALIZABLE
final static byte SC_BLOCK_DATA = 0x08; //if SC_EXTERNALIZABLE
final static byte SC_SERIALIZABLE = 0x02;
final static byte SC_EXTERNALIZABLE = 0x04;
final static byte SC_ENUM = 0x10;
所以0x02代表了可序列化.
- 0x0001: 这一位代表了类中域的个数,在我们的Pet类里,只有一个域就是int paws,所以为1.
-
0x49: 这个二进制对应的ASCII值是I,这在规范里有定义,我们看下规范定义的是什么:
(
B' for byte,C' for char,D' for double,F' for float,I' for int, >J' for long,L' for non-array object types,S' for short,Z' for boolean, and[` for arrays)
所以I的意思就是域的类型int型,跟我们在Pet类中的定义一样. - ** 0x00 04 :** 既然前面已经指明了域的类型和个数,这里就是域名的长度,就是4个字节,代表这里之后的4个字节代表的是域名.
- ** 0x70617773:** 这里就是域名的ASCII字符,转换成ASCII就是paws,我们在Pet类声明的变量名.
-
** 0x78 70:** 看下协议中的这两个值的含义:
final static byte TC_ENDBLOCKDATA = (byte)0x78;
final static byte TC_NULL = (byte)0x70;
所以0x78代表该块定义的序列化流结束了,0x70是NULL,没有超类了. -
** 0x00000000**
至此,对于需要传送的类的整个定义已经完成了,那么最后面四个字节的0x00000000是什么意思呢?很简单,就是之前定义的我们的int型域变量paws里存储的实际值了,由于我们声明了但没有给值,所以这里就是4个字节的00000000.
总结
看了以上对序列化后的二进制流的逐字翻译,我们可以看到为什么java的序列化需要服务器和客户端都需要同一个类的jar包.
因为序列化的流只定义了所传输类的一些定义和域的值,其写入和读取是分别由客户端程序和服务端程序组装完成的,如果双方没有一个共同的基础(同一个类),是无法完成的.
而且由于在网络上传输的两端的进程可能跑的是不同jdk版本的虚拟机,这个协议还要保证序列化仍然能成功,这个协议文档中明确写明了版本设计在序列化中的目标:
The goals are to:
Support bidirectional communication between different versions of a class >operating in different virtual machines by:
Defining a mechanism that allows Java classes to read streams written by >older versions of the same class.
Defining a mechanism that allows Java classes to write streams intended to >be read by older versions of the same class.
Provide default serialization for persistence and for RMI.
Perform well and produce compact streams in simple cases, so that RMI can >use serialization.
Be able to identify and load classes that match the exact class used to >write the stream.
Keep the overhead low for nonversioned classes.
Use a stream format that allows the traversal of the stream without having >to invoke methods specific to the objects saved in the stream.
比较重要的就是:
- java类可以读取其自身的老版本流信息.
- java类可以输出一个其老版本的同样的类能读出的流.
参考:
https://zhidao.baidu.com/question/1950526799354625868.html
https://www.cnblogs.com/zhukunrong/p/4868856.html