动手学深度学习PyTorch版-task4
目录:
task1:https://blog.csdn.net/zahidzqj/article/details/104293563
task2:https://blog.csdn.net/zahidzqj/article/details/104309590
task3:https://blog.csdn.net/zahidzqj/article/details/104319328
task4:本章节
task5:https://blog.csdn.net/zahidzqj/article/details/104324349
task6:https://blog.csdn.net/zahidzqj/article/details/104451810
task8:https://blog.csdn.net/zahidzqj/article/details/104452274
task9:https://blog.csdn.net/zahidzqj/article/details/104452480
task10:https://blog.csdn.net/zahidzqj/article/details/104478668
1 机器翻译及相关技术
机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。 主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列的长度不同。
主要包括:数据预处理、分词、建立词典
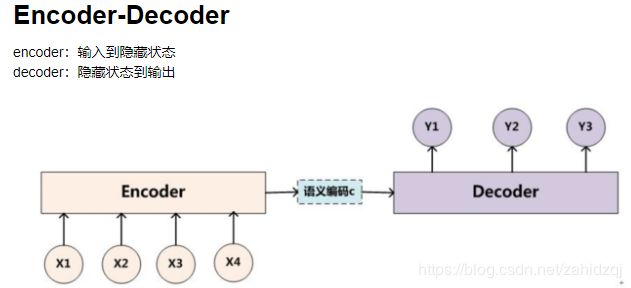
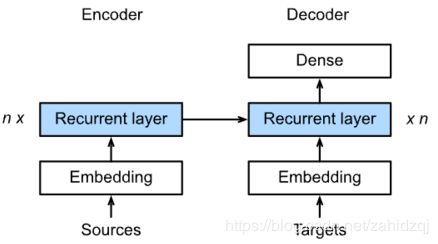
Seq2seq模型:
2 注意力机制与Seq2seq模型
当试图描述一件事情,我们当前时刻说到的单词和句子和正在描述的该事情的对应某个片段最相关,而其他部分随着描述的进行,相关性也在不断地改变。
为什么加入注意力:上下文输入信息都被编码器限制到固定长度,而解码器则受到该固定长度的影响,过长截断,过短补零,这限制了模型的性能,尤其是输入序列较长时,性能会很差。
attention思想:打破了传统编码器-解码器结构在编解码时都依赖于内部一个固定长度向量的限制
Attention机制的实现:通过保留LSTM编码器对输入序列的中间输出结果,然后训练一个模型来对这些输入进行选择性的学习并且在模型输出时将输出序列与之进行关联。即输出序列中的每一项的生成概率取决于在输入序列中选择了哪些项。
在文本翻译任务上,使用attention机制的模型每生成一个词时都会在输入序列中找出一个与之最相关的词集合。之后模型根据当前的上下文向量 (context vectors) 和所有之前生成出的词来预测下一个目标词。
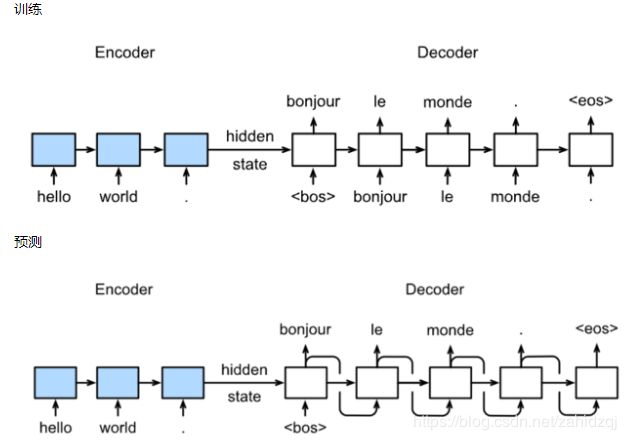
在“编码器—解码器(seq2seq)”⼀节⾥,解码器在各个时间步依赖相同的背景变量(context vector)来获取输⼊序列信息。当编码器为循环神经⽹络时,背景变量来⾃它最终时间步的隐藏状态。将源序列输入信息以循环单位状态编码,然后将其传递给解码器以生成目标序列。然而这种结构存在着问题,尤其是RNN机制实际中存在长程梯度消失的问题,对于较长的句子,我们很难寄希望于将输入的序列转化为定长的向量而保存所有的有效信息,所以随着所需翻译句子的长度的增加,这种结构的效果会显著下降。
与此同时,解码的目标词语可能只与原输入的部分词语有关,而并不是与所有的输入有关。例如,当把“Hello world”翻译成“Bonjour le monde”时,“Hello”映射成“Bonjour”,“world”映射成“monde”。在seq2seq模型中,解码器只能隐式地从编码器的最终状态中选择相应的信息。然而,注意力机制可以将这种选择过程显式地建模。
Attention 是一种通用的带权池化方法,输入由两部分构成:询问(query)和键值对(key-value pairs)。
对于一个query来说,attention layer 会与每一个key计算注意力分数并进行权重的归一化,输出的向量o则是value的加权求和,而每个key计算的权重与value一一对应。
为了计算输出,我们首先假设有一个函数α 用于计算query和key的相似性,然后可以计算所有的 attention scores a1,…,an by
ai=α(q,ki).
我们使用 softmax函数 获得注意力权重:![]()
最终的输出就是value的加权求和:

注意力分配概率分布值的通用计算过程:
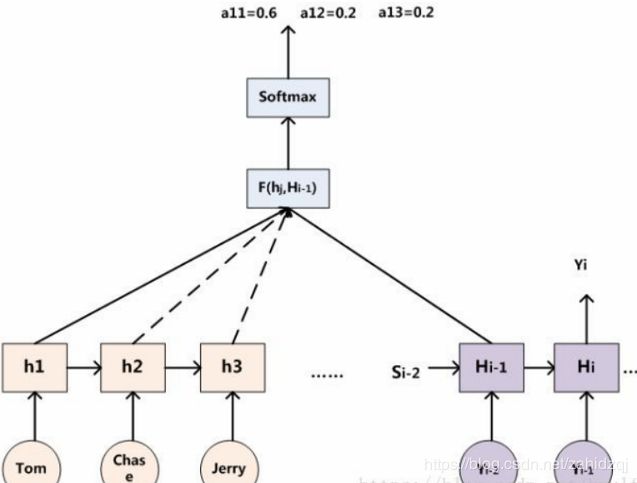
对于采用RNN的Decoder来说,在时刻i,如果要生成yi单词,我们是可以知道Target在生成Yi之前的时刻i-1时,隐层节点i-1时刻的输出值Hi-1的,而我们的目的是要计算生成Yi时输入句子中的单词“Tom”、“Chase”、“Jerry”对Yi来说的注意力分配概率分布,那么可以用Target输出句子i-1时刻的隐层节点状态Hi-1去一一和输入句子Source中每个单词对应的RNN隐层节点状态hj进行对比,即通过函数F(hj,Hi-1)来获得目标单词yi和每个输入单词对应的对齐可能性,这个F函数在不同论文里可能会采取不同的方法,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。
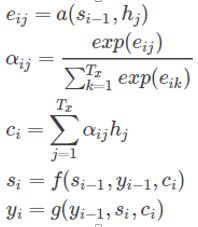
通过计算余弦相似度来求eij:
又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度。余弦相似度将向量根据坐标值,绘制到向量空间,如最常见的二维空间。
3 Transformer
主流的神经网络架构如卷积神经网络(CNNs)和循环神经网络(RNNs)。让我们进行一些回顾:
- CNNs 易于并行化,却不适合捕捉变长序列内的依赖关系。
- RNNs 适合捕捉长距离变长序列的依赖,但是却难以实现并行化处理序列。
为了整合CNN和RNN的优势,创新性地使用注意力机制设计了Transformer模型。该模型利用attention机制实现了并行化捕捉序列依赖,并且同时处理序列的每个位置的tokens,上述优势使得Transformer模型在性能优异的同时大大减少了训练时间。
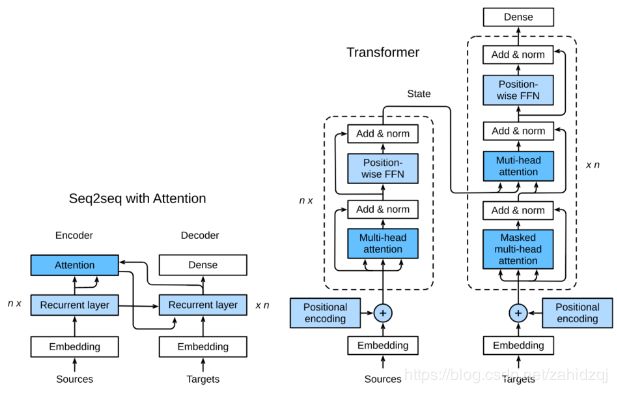
图10.3.1展示了Transformer模型的架构,与9.7节的seq2seq模型相似,Transformer同样基于编码器-解码器架构,其区别主要在于以下三点:
- Transformer blocks:将seq2seq模型重的循环网络替换为了Transformer Blocks,该模块包含一个多头注意力层(Multi-head Attention Layers)以及两个position-wise feed-forward networks(FFN)。对于解码器来说,另一个多头注意力层被用于接受编码器的隐藏状态。
- Add and norm:多头注意力层和前馈网络的输出被送到两个“add and norm”层进行处理,该层包含残差结构以及层归一化。
- Position encoding:由于自注意力层并没有区分元素的顺序,所以一个位置编码层被用于向序列元素里添加位置信息。