Hadoop配置文档
预节
在这一节中,笔者主要向大家介绍了该配置文档中,所用到的Linux命令和Linux的帮助。
终端提示信息
在Linux中,终端的每一行都有提示信息,其包含了当前终端登录的用户,当前登录的主机,当前终端所在的目录。
如:[frank@master ~]$其格式为:[[用户名]@[hosts主机名或主机ip [当前所在路径]]$解析后可以知道,例子给的提示,实际上代表的是:当前终端登录的主机为master,所有的操作都是针对master的,登录主机的用户为frank,当前终端cd命令进入的是~文件夹即/home/frank。
这些信息在进行多机操作时,是需要格外注意的,需要清除的知道,当前终端为那个用户,针对哪台主机进行操作,当前文件夹在哪等等。
su命令
命令格式:su [用户名]
su命令为切换用户的命令,su [用户名],其中用户名为可选项,若不填,则会切换至root用户(要输入root密码)
cd命令
命令格式:cd [路径名]
cd 命令是路径的进入,这个命令在windows中也仍然保留,但是Unix下,其文件系统显得更加灵活,两者区别在此不赘述。
从格式中可以看出,路径名是可选项,也就是说cd是一个合法有效命令,此命令使得终端进入~目录下。
几个特殊符号的意义:
* .
该符号表示当前文件,如:cd .,就是进入当前文件夹。
* /
该符号表示Linux根目录下,在Linux分区中,所有文件都挂载在了/下,包括媒体设备为/media,/下有etc,opt,usr,home等路径。因此,cd /命令进入了Linux根目录
* ..
该符号表示返回上一层,即返回当前目录的上一层目录,如当前处于/usr/bin,则cd ..将会返回至/usr
* ~
该符号表示用户的home路径,假设用户名为frank,则~等价于/home/frank,路径中frank根据登录用户而改变
* 相对路径和绝对路径
在Linux中,若cd命令的路径以/开头,则表示根目录下的绝对路径,如/usr表示根目录下的usr文件夹或文件,而相对路径则直接以文件名为开头,如当前处于/usr下,cd hadoop/etc/hadoop则表示了进入当前目录下的hadoop文件夹下的etc文件夹下的hadoop文件或文件夹,其就等价于cd /usr/hadoop/etc/hadoop
注意:在路径中存在空格是需要特别处理的,因为空格被当做了参数的分隔符,因此在使用空格路径时,可在路径上加上”进行标识,这样可以直接使用空格如:
VMware Tools,或者也可以在空格前加上\进行转义,如:VMware\ Tools
路径通配符
格式:*
该符号表示匹配任意的意思,比如/usr/*.xml,则表示/usr路径下所有以.xml结尾的文件或文件夹
执行可执行程序或shell
在Linux中,文件有权限,分别是r、w、x、rw组合,分别代表读、写、可执行、读写。
在执行可执行程序时,有两种方法。第一种是环境变量中,进行了配置的可执行程序。如配置好了java环境,在终端中输入java -version其会自动执行JAVA_HOME/bin下的java文件,这是在环境变量中进行配置过的。
注意:在终端中,一切不带路径的可执行程序,都是在执行系统指令或者环境变量中配置好的可执行文件。如java,cd,su等,其都是直接敲入即可。
而要执行某些文件夹下的可执行文件,都必须带上路径。假设当前终端处于~目录下,hadoop文件夹有个可执行文件为/home/frank/hadoop/bin/hdfs,则可以这样执行该hdfs:
[frank@master ~]$ ./hadoop/bin/hdfs fs -put input/* input,这样便是在带上路径,执行某个文件夹下的可执行文件。
sudo获取root权限
命令格式:sudo command [params….]
在Linux中,权限是被严格控制的,很多指令都需要使用root权限才能执行,因此在用户加入root后,经常需要sudo指令,来使用root权限执行某个操作。从格式中可以看出,sudo是为了获取root权限执行某个command命令。
vim 编辑器
命令格式:[sudo] vim [filename]
在Linux下,最好用的编辑器无疑是vim,虽然其没有绚丽的可视化界面,但是其在Linux这种权限被严格控制的情况下,它是很好的一个选择,而且它为我们提供了良好的高亮效果,大大提高了我们的编辑效率。
Vim优秀,在于其可以为在配合sudo的情况下直接对r权限的文件进行w操作,比如/etc/profile文件,该文件通常是r权限的,使用gedit等可视化编辑器在保存时,通常是无法正常保存的,而是将原始文件重命名,在原始文件名后带上~,然后新建一个具有w权限的同名文件。
而Vim则可以在原始文件上进行修改并保存。
通过格式,我们可以看出,vim可以配合root权限使用,因此其可以对r权限的文件进行w操作。在vim时,默认以r打开,在该模式下不能编辑,而按下I或insert键后,会进入INSERT模式,这种模式可以进行编辑,再次按下INSERT,将会更改为REPLACE模式,再按下会切换会INSERT,具体差别可读者自行测试。
在编辑完成后,首先需要按下ESC键,退出编辑模式,此时左下角的INSERT标识将会消失,进入到了r模式,此时可以输入vim的退出命令。
vim退出命令有如下几个:
* :wq
保存并退出(常用)
在sudo下,对只读文件修改后,使用该命令可以正确保存,等价于:wq!
* :q
直接退出(常用)
若对只读文件修改后,无法使用该命令退出,需要使用:q!强制退出,并且不保存更改
* :x
文件被修改则保存后退出,否则直接退出
* :w filename
文件另存为命令,将文件另存为filename
* :e
重新载入当前文件
* :q!
强制退出,主要使用于无权限的文件的修改后强制退出和无权限的文件的强制退出
* :wq!
强制保存并退出
reboot命令
命令格式:[sudo] reboot
该命令可以配合root权限进行操作,并且最好带上sudo进行使用,该命令表示对终端登录的当前系统进行重新引导。
exit命令
命令格式:exit
该命令表示退出当前的终端登录,比如ssh从master登录至slave,终端在登录slave时执行exit可退出slave登录回到master,读者可自行测试,注意观察终端提示的@后的主机名或IP地址
cat命令
cat命令格式比较灵活,其主要功能可以显示某个文件,将多个文件合并显示,将多个文件合并为一个文件,将某个文件中内容追加到另一个文件中,具体使用方法,可以参看标准帮助文档。
service命令
命令格式:[sudo] service 服务名 服务状态
该命令必须使用root权限执行,sudo之所以为可选项,是因为用户很可能切换至root,此时可以省略sudo,若非root用户,则需要使用sudo获取root权限执行命令。
该命令可以启动、重启、或停止某个服务。
如:
sudo service network restart表示重启network服务,该指令在修改了网卡配置文件后需要执行。
ssh-keygen命令
命令格式:ssh-keygen [-t] [typename] [-P] [password]
该命令用户生成SSH密钥,-t指定类型名,-P可指定密码。
如:
ssh-keygen -t rsa -P ''表示生成rsa类型的密钥对,并且密码为空,生成的文件将保存至:/home/[用户名]/.ssh下
在该命令中,可以指定保存路劲,具体用法可参照标准帮助文档。
ls 命令
命令格式:ls [filename]
该命令表示列举出某个文件夹下的所有文件名和文件夹名,若filename为空,则表示列举当前目录。
ll 命令
命令格式:ll [filename]
该命令表示列举出某个文件夹下的所有文件和文件夹详情,并且显示出文件的权限等具体信息,若filename为空,则表示列举当前目录。
ssh 命令
命令格式:ssh [主机名或IP地址]
使用ssh方式,登录到远程主机。若使用主机名,则必须在hosts中将hostname和IP地址进行映射。
ssh方式登录有密码验证和密钥认证,其中使用密码认证较不安全,且较为繁琐,使用密钥认证相对安全。
scp 命令
命令格式:[sudo] scp [-r] filname 主机名或IP:[路径]
该命令个可以在多台主机中传输文件,若传输的是当前用户不具权限的文件或文件夹,需要使用sudo获取root权限,若传输文件夹,需要加上-r。
详细配置请参照官方帮助文档。
chown 命令
命令格式:[sudo] chown [用户名]:[组] 路径名
该命令必须使用root权限,可使用root用户或sudo获取root权限。该命令表示,将某个文件或文件夹的所有权改为某个用户,或某个组。
具体用法请参考官方文档。
chmod 命令
命令格式:[sudo] chmod [权限值] 路径名
该命令用户修改某个文件或文件夹的权限,权限值可以为数字,也可以为u+w,u-w,g+w等参数。
具体用法请参考官方文档。
1. VWare Tools:Windows于Linux文件互访
首先安装好Linux后,需要安装插件,来供Linux和Windows进行文件传输。
由于在新装好的环境中,当前用户未加入root权限,因此无法使用sudo命令,此时需要切换到root下执行
代码如下:
- 切换到su:
su,提示输入密码,并输入你的root密码 - 此处进入了root,将vmtools解压到桌面,若使用可视化的界面,可直接解压到桌面即可,这里讲解使用命令行进行安装
- 执行
cd /media进入挂在的媒体盘即CD,如图:

图中即为VMware自动挂在的安装盘,进入该盘,解压gz文件,由于上述路径存在空格,则使用cd时应该这样操作避免空格:cd 'VMware Tools'或cd VMware\ Tools - 解压文件,使用
tar -zxvf VMwareTools-9.6.1-1378637.tar.gz -C /home/frank/Desktop注意其中,frank为用户名,再进入解压后的文件夹进行安装,执行:cd /home/frank/Desktop/vmware-tools-distrib回车后执行:./vmware-install.pl,回车后一路回车后,等待安装完毕并执行reboot命令进行重启生效,生效后,将所需要的JDK和hadoop文件都拖入到虚拟机中。
注意在上述的命令中,都无法进行sudo命令,都是在su命令下使用root完成,若Linux不为桌面版,则可以使用samba进行文件传输。
在我们的使用中,由于GUI较为消耗资源,并且GUI很多地方受到权限的限制,对文件的操作等等都需要借助shell,因此在拖完JDK和Hadoop后即可把GUI关闭,有需要可执行:sudo vim /etc/inittab,将其中id:5:initdefault:中的5修改为3,sudo reboot即可生效。
2. 为用户分配root权限
- su切入root,请参照上一节中步骤1进行切换,执行
visudo对/etc/profile进行编辑,注意该文件为只读,使用gedit命令,可能会无法保存而产生一份可写的副本,为避免不必要的麻烦,所有gedit都用vim进行编辑。 - 将frank用户加入sudo,并且免密码。在文件中
root ALL=(ALL) ALL后追加一行frank ALL=(ALL) NOPASSWD:ALL,执行完毕之后,使用exit退出root用户,执行sudo whoami,若显示root且不提示密码,则配置成功,并且免密码设置成功。
3. 进行JAVA环境配置
第一节VMTools安装好后,拖入JDK,如果已经解压则,无需解压,若未解压需要解压到指定目录下。
笔者为演示充分,拖入了未解压版的JDK文件,在Linux中进行解压,并且使用命令的方式进行,笔者的JDK文件在/home/frank/Desktop下,并且hadoop也拖入该目录中,见图:

解压JDK文件,执行:
tar -zxvf ~/Desktop/jdk-8u101-linux-i586.tar.gz -C ~/Desktop,执行命令时,请注意路径问题,这很重要!!- 在解压后,~/Desktop多出了一个jdk文件,为了后面配置的方便,这里我们给它重命名:
mv ~/Desktop/jdk1.8.0_101 ~/Desktop/jdk1.8,该名称要牢记! - 在这里使用同样的方法解压hadoop,并且给他重命名,类似2、3步骤,将路径改为hadoop路径即可。执行结束之后,桌面上将存在两个文件夹:jdk1.8为JDK文件,hadoop为hadoop文件夹。
- 在这里,我们不将hadoop和jdk放在一起,而是将jdk放到另外/usr下,因为该路径是有权限,其安全性相对较高,不易被修改。执行拷贝命令:
sudo cp -r ~/Desktop/jdk1.8 /usr,执行ls /usr即可看到一个jdk1.8的文件夹被拷贝到了/usr路径下,并将桌面的文件删除:sudo rm -r ~/Desktop/jdk1.8。 
- 设置环境变量
执行:sudo vim /etc/profile,该地方使用vim不是用gedit,在于该文件是默认没有写权限的,若使用gedit保存很可能产生一个副本文件,若要使用gedit最好使用sudo chmod u+w frank /etc/profile对写权限进行添加,保存后再sudo chmod u-w frank /etc/profile进行移除,为了简便,使用vim更可靠!在文件末尾追加:
#SET JAVA Enviorment
JAVA_HOME=/usr/jdk1.8
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
JRE_HOME=$JAVA_HOME/jre
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME
export CLASSPATH
export JRE_HOME
export PATH追加完成后,执行:source /etc/profile 进行生效,执行:java -version验证是否配置成功。
注意:在上述内容中JAVA_HOME,应该修改为JDK所在的路径。在某些CentOS中,默认携带了OpenJDK,这会对JAVA环境变量造成影响,可以使用命令:sudo yum -y remove java*进行移除
4. 进行hadoop环境变量配置
该部分内容为可选配置内容,因为主要是为了能够在后面的操作中,快速方便的使用hadoop,start-dfs.sh等操作而配置,而对hadoop集群配置并没有很大的影响。
在执行之前,请先将hadoop按照jdk解压的方式,进行解压,为方便,笔者使用mv命令将解压后的文件夹重命名为hadoop。
1. 将hadoop文件移动到某个目录下。
该目录是需要注意某些条件的,因为在Linux中,权限被限定在各个方面,因此在移动时,需要非常小心权限问题,其中/目录下,usr,opt,等文件目录都是不被普通用户所有,其没有所有权,也没有了编辑权,即JAVA程序,不能对这些目录进行更改,也不能进行目录的创建等操作。而在/home/frank中,即’~’下,是被用户frank所有的,因此可以执行写操作。
因此在这种情形下,若hadoop放在了没有写权限的路径下,那么hadoop在启动时,将无法自动创建某些文件夹,从而启动失败,因此将hadoop放在了无所有全的路径时,需要进行权限的修改,方可启动成功,后面会讲到。这里我们使用/usr路径作为演示路径。
执行sudo cp -r ~/Desktop/hadoop /usr,(有关hadoop路径和重命名,请看之前的小结)这样就将桌面的hadoop复制到了/usr下面,如有需要可执行sudo rm -r ~/Desktop/hadoop删除桌面的原始文件,这里作为备份不删除。
前面提到有关权限的问题,这里/usr的路径下的hadoop是不被frank所有的,没有写的权限,因此我们改变/usr/hadoop的所有权为frank用户:sudo chown -R frank:frank /usr/hadoop 其中,frank:frank为用户:用户组形式。若目录为 ~/hadoop/这其实是不需要执行该操作的,即前面的目录移动至:sudo cp -r ~/Desktop/hadoop ~/是不需要执行chown的。
2. 将hadoop中的bin和sbin导出到环境变量,执行:
sudo vim /etc/profile,追加值:
export PATH=$PATH:/usr/hadoop/bin:/usr/hadoop/sbin并执行source /etc/profile生效修改。
生效后,执行hadoop命令可以看到:
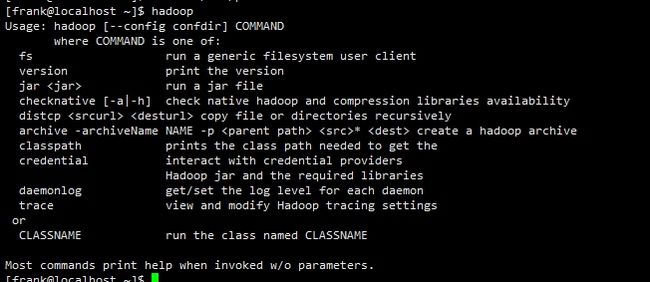
提示命令用法
5. 修改hostname文件配置
在进行hadoop集群配置时,需要一台主机作为master,管理namenodes,其他一台或几台主机作为datanode来实现数据的分布式存储和mapreduce,因此需要将多台主机互连,并且借助hostname快速访问主机。
在这里如果需要设置一台master和两台slave时,可以命名为:
* master
* slave1
* slave2
若只有一台slave,则可以把slave2不要即可。
1. 修改master的hostname
首先进入对应文件编辑模式:sudo vim /etc/sysconfig/network,默认文件内容如下:
![]()
我们将HOSTNAME修改为master作为master节点主机。
在通常条件下,我们会通过浏览器访问虚拟机中的8088和50070来管理hadoop,此时Linux端口是被防火墙所关闭的,无法访问,因此我们一般会关闭防火墙:执行
sudo chkconfig iptables off,这样会永久生效并且重启有效,这样即可通过浏览器访问hadoop进行管理和查看。
配置完毕后,即可对虚拟机进行关机和克隆。注意:上述文件为只读文件,gedit保存需要尤其注意!保存后,请关机,并克隆虚拟机。
6. 修改克隆主机的hostname和hosts
在hosts中,可以将IP地址与hostname进行一个映射,那么经过映射后,即可在一台主机中,快捷的使用hostname进行访问。首先在虚拟机中,将三(两)台虚拟机同时开启,分别执行ifconfig,获取到IPv4地址,供hosts文件绑定。
slave1如图:
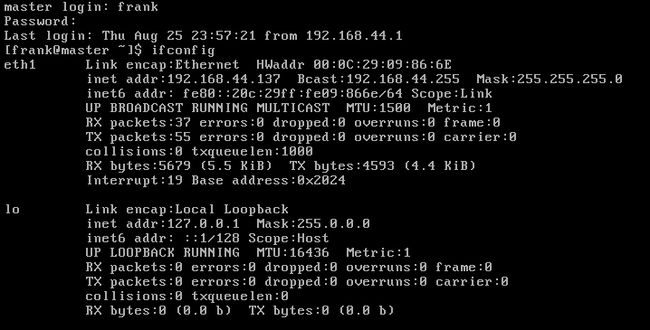
slave2如图:

master如图:
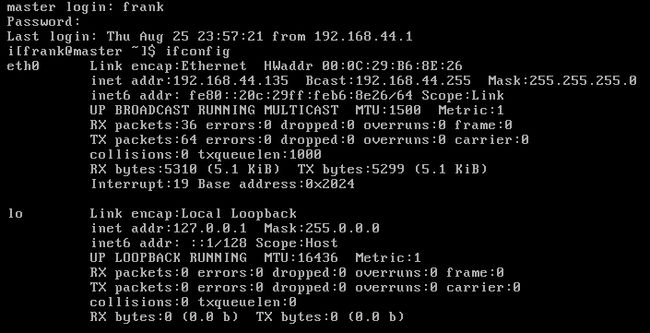
分别几下该三个IP为:
* master: 192.168.44.135
* slave1: 192.168.44.136
* slave1: 192.168.44.137
在这里,我使用XShell进行连接,VM后台运行,SSH至master,或者在master虚拟机中执行,但是一定要保证终端@后面为master主机
1. 修改hosts文件,绑定hostname和IP地址。
执行命令:sudo vim /etc/hosts,并在原始文件尾部,追加:
192.168.44.135 master
192.168.44.136 slave1
192.168.44.137 slave22. ping测试hosts配置
在master中,ping slave1和ping slave2
如图ping slave1结果:

正确获取到响应.
如图ping slave2:
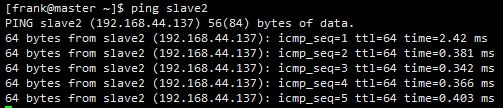
可以获取到响应,证明master的hosts文件配置成功。
3. 将hosts文件传输到slave主机
执行shell:sudo scp /etc/hosts slave1:/etc/hosts发送到slave1
执行shell:sudo scp /etc/hosts slave2:/etc/hosts发送到slave2
结果如图:

出现传输为100%则传输成功。
注:在该配置过程中,还未设置SSH免密钥,必须输入密码方可传输。
4. 修改slave主机的hostname
使用SSH,在master主机登录slave1,执行:ssh slave1输入密码即可。
使用第五节,修改master的方法,修改hostname为slave1和slave2即可,并reboot(重启)生效。
7. 配置SSH免密钥登录
在前面的修改slave主机的hostname中,我们都是需要输入密码的,这在hadoop上操作是不太方便的,因此我们需要设置SSH免密钥登录。
1. 修改sshd_config文件,使得其可以免密钥。
执行:sudo vim /etc/ssh/sshd_config
如图:

在文件中找到:
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys将其前面的#注释去除,保存即可。
保存之后,需要重启sshd服务,执行:sudo service sshd restart重启服务
![]()
同时,将更改传输到slave主机分别执行:
# 发送到slave1
sudo scp /etc/ssh/sshd_config slave1:/etc/ssh/sshd_config
# 发送到slave2
sudo scp /etc/ssh/sshd_config slave2:/etc/ssh/sshd_config看到传输为100%即为成功!
之后依次在终端执行下列shell,以重启slave主机的sshd服务:
# SSH连接到slave1主机,期间可能要输入密码
ssh slave1
# 重启sshd服务
sudo service sshd restart
# 退出slave1主机
exit
# SSH至slave2
ssh slave2
# 重启sshd服务
sudo service sshd restart
# 退出slave2主机
exit2. SSH生成公钥和私钥
在三(两)台主机分别上执行:ssh-keygen -t rsa,之后一直默认回车,生成密钥和公钥,默认保持在~/.ssh文件夹下。
如图:
master:

slave1:

slave2:

再执行exit进入到master主机,执行:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
修改.ssh文件夹权限为700:
chmod 700 ~/.ssh
修改authorized_keys权限为600:
chmod 600 ~/.ssh/authorized_keys
修改后,可以在master下执行ssh master,若不提示密码则设置成功。注:以上操作,在三台主机均需要执行。
注:在上述的chmod一定要执行,否则在Linux中,会因为配置文件的权限过高而产生不安全的隐患,从而不应用该配置,因此尽量执行上述的chmod操作。
在使用秘钥登录时,无需使用密码,安全性更高,其认证过程大概是:
+ 客户端(A主机)连接服务器(B主机)时,服务器(B主机)产生一个随机码,并且发送给客户端(A主机)
+ 客户端(A主机)使用自己的私钥,来对服务器(B主机)发送的随机码进行加密,并将密文回传给服务器(B主机)
+ 服务器(B主机)在收到密文后,使用已有的公钥进行解密,若解密后匹配成功则允许连接的建立
因此在这个过程中,要使用master主机免密码SSH至slave1和slave2,那么相当于slave作为服务器,因此slave需要保存master的公钥,来进行认证,方可免密码。
因此在接下来,生成了master的公钥后,需要传回slave主机,分别执行:
# 传回到slave1主机
cat ~/.ssh/id_rsa.pub | ssh slave1 'cat - >> ~/.ssh/authorized_keys'
# 传回到slave2主机
cat ~/.ssh/id_rsa.pub | ssh slave2 'cat - >> ~/.ssh/authorized_keys'执行完毕后,使用ssh slave1或ssh slave2验证是否成功。在传输过程中,是需要输入密码的。
注:在该配置过程中,采用了单向配置的方式,,因此只能master SSH连接至slave主机,而从slave SSH至master时,仍然是需要密码的。并且判断当前是登录哪台主机,可看终端前面的提示,frank@master表示,当前使用frank用户登录了master主机,而终端显示frank@slave1时,则表示当前终端使用了frank用户登录了slave1主机,在测试SSH时,必须保证@后面为master方可测试成功。
8. 安装Hadoop分布式集群环境
在第4节中,我们已经将hadoop解压后的文件夹拷贝至/usr目录下,可以执行ls /usr/hadoop,查看该文件是否存在。
![]()
从图中我们可以看出,笔者在这里将jdk重命名为jdk1.8并复制到了/usr目录下,hadoop文件夹重命名为hadoop并复制到/usr目录下,该两个目录较为重要,将是后续操作中比较常见的目录。
为了后面的执行方便,我们在这里将Hadoop的环境变量配置齐全,执行:sudo vim /etc/profile,在文件中追加以下数据:
# Hadoop Environment Variables
export HADOOP_HOME=/usr/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin其中HADOOP_HOME的值,需要相应替换为读者自己的hadoop路径,该路径中包含bin、sbin等文件夹。
添加完毕后,ESC退出编辑模式,使用:wq保存,再执行:source /etc/profile生效更改。
并将该文件,发送到其他slave节点,如图:

如图可以看到,大致过程为发送profile文件,ssh至slave主机,分别应用该profile文件,分别执行以下的命令:
# 发送到slave1,期间可能需要密码
sudo scp /etc/profile slave1:/etc/profile
# 发送到slave2,期间可能需要密码
sudo scp /etc/profile slave1:/etc/profile
# ssh连接至slave1
ssh slave1
# 应用profile
source /etc/profile
# 退回到master
exit
# ssh连接至slave2
ssh slave2
# 应用profile
source /etc/profile
# 退回到master
exit最后将返回master主机的登录,注意看终端的开头@后面是否为master
如此之后,环境变量配置完毕,接下来需要配置hadoop的配置文件,该部分也是较为重要的部分,也是核心部分。
以下的内容为hadoop的核心配置,需要明确。并且需要详细了解几个重要的配置文件的属性和需要注意的问题。
在整个的配置过程中,主要有以下几个文件需要配置:
* core-site.xml
* hdfs-site.xml
* mapred-site.xml(需要从模板中重命名)
* yarn-site.xml
* master
* slaves
其中core-site.xml和hdfs-site.xml中有两个属性尤为重要,其分别是hadoop.temp.dir(存放一些临时文件)、dfs.namenode.name.dir(这里是存放Hadoop中Master节点中的NameNodes文件,且master节点主要便是管理这些namenode)以及dfs.namenode.data.dir(存放Hadoop中有哪些DataNodes,hdfs是分布存储中,用于存储数据的),这三个文件夹,在执行hadoop的format和开启hadoop服务是,需要创建一些数据文件和日志文件,因此这些属性的目录值,当前用户必须要拥有权限,并且在运行时,在hadoop下会自动创建的logs文件夹存放日志文件。
注意:上面所涉及的目录,是灵活的,可随意设置的,但是必须保证一点,当前用户对这些目录,是有读写权限的。否则启动或格式化将会失败!
- 在这里,笔者使用的hadoop.temp.dir为$HADOOP_HOME/tmp,该目录会在hadoop格式化时被创建。
- dfs.namenode.name.dir的值为file:/$HADOOP_NAME/hdname(URI路径)
- dfs.namenode.data.dir的值为file:/$HADOOP_NAME/hddata(URI路径)
$HADOOP_HOME表示在/etc/profile中设置的环境变量,若未设置,请使用绝对路径,即为hadoop文件所在的路径,在第1节第4小节中,笔者有让大家移动hadoop文件,这里的路径,即为移动后的最终路径,也就是该文件下包含bin、sbin、README.txt等文件。
在第4节中,笔者向大家介绍了关于Hadoop文件夹权限的问题,在这里,前面的介绍将显得很关键,请详细阅读第4节中绿色文字内容。
我们讲到,/usr目录包括其子目录默认是用户不具有读写权限的,那么将hadoop移动到该目录下后,用户是不对其具有读写权限的,因此在hadoop格式化时,无法自动创建文件夹,也无法写入日志等文件,会导致格式化失败!而在/home/frank或者说是~目录下,响应的用户是具有读写权限的。
若hadoop文件移动在/home/frank下,可跳过该步骤,否则必须执行该步骤。
执行(frank指代用户名,请酌情替换,$HADOOP_HOME与前面的解释一致,需要酌情替换。):
sudo chown -R frank:frank $HADOOP_HOME
注意:这里只执行了一句,因为在笔者的设置中,dfs.namenode.name.dir和dfs.namenode.data.dir都是设置为$HADOOP_HOME子目录,执行命令后,$HADOOP_HOME及其子目录,用户都讲有读写权,倘若dfs.namenode.name.dir和dfs.namenode.data.dir不为其子目录,则需要另外执行:sudo chown -R frank:frank [dfs.namenode.name.dir]和sudo chown -R frank:frank [dfs.namenode.data.dir],其中的方括号表示可替换部分,请对应的替换为该属性的值,由于该属性值为URI形式,在执行时,请替换为file:后的路径。
接下来我们来实际设置对应的几个文件:
1. core-site.xml文件配置
执行:sudo vim $HADOOP_HOME/etc/hadoop/core-site.xml进入编辑模式:
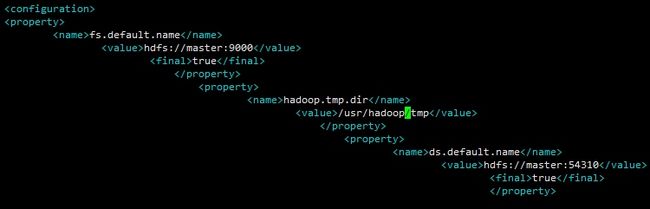
在configuration标签内,添加($HADOOP_HOME/tmp勿直接使用,请替换成真实路径如:/usr/hadoop/tmp,并且需要确保用户具有读写权限,请阅读配置前的声明):
<property>
<name>fs.default.namename>
<value>hdfs://master:9000value>
<final>truefinal>
property>
<property>
<name>hadoop.tmp.dirname>
<value>$HADOOP_HOME/tmpvalue>
property>
<property>
<name>ds.default.namename>
<value>hdfs://master:54310value>
<final>truefinal>
property> 如图:
保存即可。
2. hdfs-site.xml文件配置
执行: sudo vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
同理插入(file:/$HADOOP_NAME/hdname和file:/$HADOOP_NAME/hddata勿直接使用,请替换成真实路径如:/usr/hadoop/hddata等,并且需要确保用户具有读写权限,请阅读配置前的声明):
<property>
<name>dfs.namenode.name.dirname>
<value>file:/$HADOOP_NAME/hdnamevalue>
<final>truefinal>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/$HADOOP_NAME/hddatavalue>
<final>truefinal>
property>
<property>
<name>dfs.replicationname>
<value>2value>
property>如图:

3. mapred-site.xml文件配置
执行:sudo cp $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml复制并重命名
执行:sudo vim $HADOOP_HOME/etc/hadoop/mapred-site.xml编辑
同理添加:
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>master:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>master:19888value>
property>如图:
4. yarn-site.xml文件配置
执行:sudo vim $HADOOP_HOME/etc/hadoop/yarn-site.xml编辑
同理添加:
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mastervalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>master:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>master:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>master:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>master:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>master:8088value>
property>如图:

5. master(s)文件配置
执行:sudo vim $HADOOP_HOME/etc/hadoop/master编辑
增加master后保存,如图:
![]()
6. slaves文件配置
执行:sudo vim $HADOOP_HOME/etc/hadoop/slaves编辑
注释localhost,增加slave节点,如:
slave1
slave2如图:

7. hadoop-env.sh文件配置
执行:sudo vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh编辑
修改export JAVA_HOME=/usr/jdk1.8文件如下:
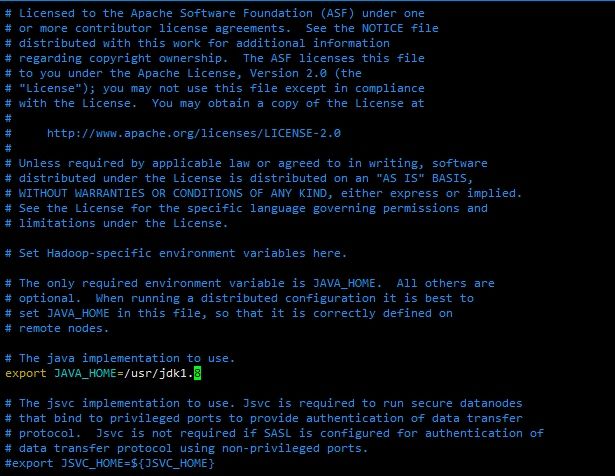 ]
]
其中/usr/jdk1.8请替换为你的JAVA安装路径
将hadoop发送到其他主机
执行:sudo scp -r /usr/hadoop slave1:/usr和sudo scp -r /usr/hadoop slave2:/usr,期间可能输入root密码。
发送后,若有需要请在slave主机中按照本节中前向声明,对slave主机中加读写权限,具体格式请阅读本节开头声明部分,如:
![]()

格式化hadoop
执行:hdfs namenode -format,未配置环境变量请先使用cd命令进入hadoop根目录下,在该目录中有bin、sbin、etc等文件夹,并执行:./bin/hdfs namenode -format
执行前,请保证当前登录为master,请查看终端@后为master
如:

请注意@后为master方可执行!
执行结果如图:
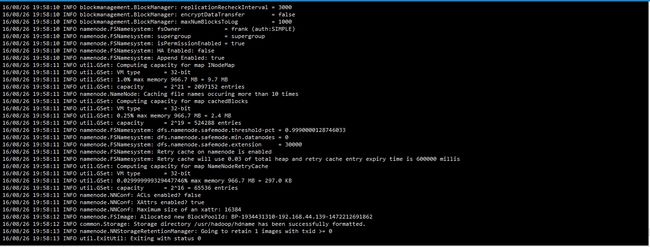
正常情况下,将会在终端中打印一系列的日志,若出现了大量的INFO为正常现象。
此时查看hadoop文件夹下,将会产生hdname文件夹:

开启服务:
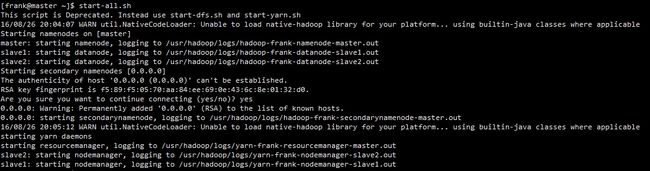
执行:start-all.sh,未设置环境变量,请cd到hadoop目录,执行./sbin/start-all.sh如图:
或:
![]()
两者区别在于,第一张图为配置了环境变量,终端提示为:
[frank@master ~]$表示当前在~目录下,可以直接执行start-all.sh,而图二则先cd,执行时终端提示[frank@master hadoop]$表示当前处于hadoop目录,并且命令加上了./sbin表示执行当前目录下的sbin目录下的shell文件
测试服务是否启动

观察图中@后面表示ssh到不同的主机,master启动了4个进程,而slave主机则启动了三个进程,与图:

不同,貌似少了两个进程,原因在于,笔者在配置slaves时,未加入master,若需要达到相同效果,可修改slaves文件后自行测试。
上述start的方式,也可以分别start-hdfs.sh和start-yarn.sh,具体命令可查看:

出现上述的结果,基本上可以认为,hadoop环境已经配置成功,并且为伪分布式的形式。
请注意:format成功后不能再次执行,否则datanode会无法正常启动。若多次format,请删除在xml文件中配置的三个文件夹,以及hadoops下的logs文件夹,重新format。
9. 关于Linux
对于Linux而言,其权限控制较高,在根目录下的文件和文件夹,基本上都需要提供root权限方可进行操作。
在虚拟机中运行Linux,同时切换界面并不方便,且不便于与Windows进行实时交互,粘贴复制也不是很方便,笔者在进行Linux操作时,采用了XShell软件进行连接,避免了直接在虚拟机中操作的不便性。并且切换主机,只需要在shell中使用ssh即可,并且可以很好的在windows下面进行复制粘贴等操作,还可以使用日志服务。
了解XShell:XShell官方介绍