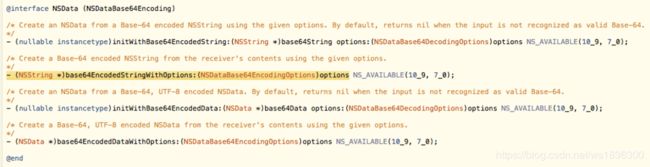
iOS 算法的前世今生:算法原理、常用算法(二)加密算法
加密算法分为三大类,对称加密、非对称加密和哈希算法。
------------1 .对称加密 DES、AES等--------
(由于 链接第一个帖子 写的比较详细,所以我只做补充说明)
对称加密的特点:
加密/解密使用相同的密钥
加密和解密的过程是可逆的
经典算法:
DES 数据加密标准
AES 高级加密标准
提示:
加密过程是先加密,再base64编码
解密过程是先base64解码,再解密
适用业务场景:
1.网络请求过程中的敏感信息,请求的时候用AES加密请求数据,服务端返回的时候客户端去解密;2.如果有数据库的时候,数据库里面的数据也可以加密好给到客户端,防止被人破解.
下面请看一段AES加密,解密代码:
+ (NSString *)obourkey{
NSString *key = [@"你的key" stringByReplacingOccurrencesOfString:@"要替换的字符串" withString:@"替换后的字符串"];
return key;
}
//加密
+ (NSString *)encrypt:(NSString *)message password:(NSString *)password {
NSData *encryptedData = [[message dataUsingEncoding:NSUTF8StringEncoding] AES256EncryptedDataUsingKey:[[password dataUsingEncoding:NSUTF8StringEncoding] SHA256Hash] error:nil];
NSString *base64EncodedString = [NSString base64StringFromData:encryptedData length:[encryptedData length]];
return base64EncodedString;
}
//解密
+ (NSString *)decrypt:(NSString *)base64EncodedString{
NSData *encryptedData = [NSData base64DataFromString:base64EncodedString];
NSData *decryptedData = [encryptedData decryptedAES256DataUsingKey:[[[AESCrypt obourkey] dataUsingEncoding:NSUTF8StringEncoding] SHA256Hash] error:nil];
return [[NSString alloc] initWithData:decryptedData encoding:NSUTF8StringEncoding];
}
-------------------2.非对称加密RSA------------------
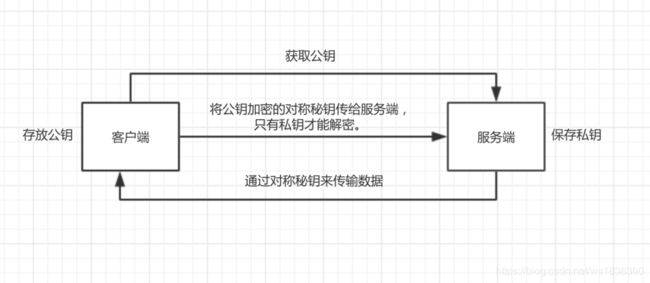
非对称加密的特点:
(其实本质是特解问题,比如12 =1*12 、12=2*6、 12=3*4,告诉你了12这个公钥,你可以用指定的一个特解(私钥)来解密;而接受服务端返回的信息,因为是只读,基本没有安全形隐患,只需要用公钥解密获取具体信息就可以了。特解越多,反向破解越难!)
客户端-->服务端:使用 公钥 加密,使用 私钥 解密
服务端-->客户端: 使用 私钥 加密,使用 公钥 解密(私钥签名,公钥验签)
公钥是公开的,私钥保密
加密处理安全,但是性能极差(特别费时间,很慢)
经典算法-->RSA
使用场景:1.比如支付宝开放平台的支付业务,支付宝会让你生成公私钥(openssl可以直接生成),私钥放在自己的服务端(切记),公钥上传到支付宝的商户平台,拿到订单信息的时候,请求服务端通过私钥签名后的订单信息,然后调用支付宝的sdk,支付宝会拿公钥来验签,验证成功之后才会进入支付选项。2.Https网络请求的SSL层
SSL层的简单过程如下:
关于RSA加密 字符/明文长度的讲解:参考链接:https://www.cnblogs.com/isyaya/p/11073149.html
或者:https://blog.csdn.net/luoluo_onion/article/details/78354799
RSA加解密中必须考虑到的密钥长度、明文长度和密文长度问题。明文长度需要小于密钥长度,而密文长度则等于密钥长度。因此当加密内容长度大于密钥长度时,有效的RSA加解密就需要对内容进行分段。
这是因为,RSA算法本身要求加密内容也就是明文长度m必须0 这样,对于1024长度的密钥。128字节(1024bits)-减去11字节正好是117字节,但对于RSA加密来讲,padding也是参与加密的,所以,依然按照1024bits去理解,但实际的明文只有117字节了。 所以如果要对任意长度的数据进行加密,就需要将数据分段后进行逐一加密,并将结果进行拼接。同样,解码也需要分段解码,并将结果进行拼接。 来自风骚度娘的知识小扩充-----参考链接:https://baike.baidu.com/item/Hash/390310?fr=aladdin 哈希算法:Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。与加密算法不同,MD5-Hash算法是一个不可逆的单向函数。) 怎么样?看不明白吧?感觉这说的是个啥呀?不是人话! 其实最后一句话已经说明了,这种算法其实做的就是 “消息摘要”。 小伙伴A就会问了:为啥任意长度的输入可以变成 固定长度的输出呢? 打个比方: 我们写一篇文章,通常就有一个题目和一个概括全文的信息摘要。 这篇文章就好比你传输的消息,无论是800字的小学作文,还是100万字的大部头书籍,都会有一个名。 你可以给你的文章定一个题目叫:“评三国”,其实只写了250个字; 而别人写了一本书定的书名就叫:“评三国”,但是有好几十万字; 说到这里,你应该就有点明白了,虽然传入的内容不一样,但是,由于题目书名定的一样,你们两人“散列成了相同的输出”。 由于书名和题目都有一些长度上的限制,所以,无论你输入“任意长度的消息”--“书的内容”,都会变成“某一固定长度的消息摘要的函数”--“书的题名”。 那么,这样屌的一种算法是如何应用到实际的环境中去的呢? 我们先来看一下它的基本概念: “若结构中存在和关键字K相等的记录,则必定在f(K)的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系f为散列函数(Hash function),按这个事先建立的表为散列表。 对不同的关键字可能得到同一散列地址,即key1≠key2,而f(key1)=f(key2),这种现象称碰撞。具有相同函数值的关键字对该散列函数来说称做同义词。综上所述,根据散列函数H(key)和处理冲突的方法将一组关键字映射到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“象” 作为记录在表中的存储位置,这种表便称为散列表,这一映象过程称为散列造表或散列,所得的存储位置称散列地址。 若对于关键字集合中的任一个关键字,经散列函数映象到地址集合中任何一个地址的概率是相等的,则称此类散列函数为均匀散列函数(Uniform Hash function),这就是使关键字经过散列函数得到一个“随机的地址”,从而减少冲突。 ” 本着很多同学看不懂或者根本不愿意看的原则,我又要给你们讲解一下: 上边这堆字里其实就讲了这么几件事, * 1. 哈希算法的输出结果和输入结果间有这对应的关系-哈希表(散列表) *2. 哈希算法很牛叉!可以用来做数据存储,数据查询和数据加密!(当然还有更多的作用:错误校正、语音识别、信息安全:文件校验、数字签名、签权协议等等) 1.啥是哈希表? 结合我们上边所说的《品三国》书籍你就应该明白---哈希表/散列表,不就是书的目录吗! 每一章的信息都可以通过目录来查找,比如第一章第一节讲:“曹操霸占良家妇女”,我们可能记不得它说的是什么事情,但是我们一定可以通过章节表 ,或者哈希表把他找出来! 而且每一节都和这个书有关联,因为一提曹操,你肯定会想到《三国》。 2.为啥很牛叉? 数据存储-----如果我把一本书压缩成了一个书目,那你说我牛不牛?把很大的信息压缩成很小的信息,然后还可以通过一张表或一种算法找到想要的信息,在目前计算机硬盘价格这么高的背景下,哈希简直不是一种算法,而是一个金矿! 数据查询-----这个也很简单,我给你写10万字的“品三国”,让你给我找出“曹操兽性大发,强抢有夫之妇”这段文字,你估计得花一天时间;而我直接告诉你,这段字可以通过哈希表(书的目录)查询,在第2章第2节第2句,那你5秒钟就能找到!在目前时间就是金钱的社会背景下,哈希简直不是一种算法,又是一个金矿! 数据加密-----你写的250个字叫《品三国》,而我写的书也叫《品三国》,那读者在选择的时候是不是就很困惑:到底哪个才是我要找的?同理,不让别人知道你的真实信息就是加密的原理。即使你找到了真正的《品三国》,即真实的输出信息,那我也可以通过改变输入的东西来增加破解难度:比如品三国我完全可以拆成《魏书》《汉书》和《东吴志》来卖!而你就完全不知道应该用那种哈希表来破解!本来你按照第一种哈希表/目录表来破解,第一章第一节应该是“刘备三顾茅庐”,结果变成了“曹操三进三出”这就很不雅观了! 这里仅做列举,小伙伴们感兴趣的可以自己发挥! 1.直接寻址法 2. 数字分析法3. 平方取中法4. 折叠法5. 随机数法6. 除留余数法 1.开放寻址法2. 再散列法3. 链地址法(拉链法)4. 建立一个公共溢出区 (由于种种原因,一些关键码可通过散列函数转换的地址直接找到,而另一些关键码在散列函数得到的地址上产生了冲突,就需要这些方法来处理了) 常用hash算法的介绍: (1)MD4 MD4(RFC 1320)是 MIT 的Ronald L. Rivest在 1990 年设计的,MD 是 Message Digest(消息摘要) 的缩写。它适用在32位字长的处理器上用高速软件实现——它是基于 32位操作数的位操作来实现的。 (2)MD5 MD5(RFC 1321)是 Rivest 于1991年对MD4的改进版本。它对输入仍以512位分组,其输出是4个32位字的级联,与 MD4 相同。MD5比MD4来得复杂,并且速度较之要慢一点,但更安全,在抗分析和抗差分方面表现更好。 (3)SHA-1及其他 SHA1是由NIST NSA设计为同DSA一起使用的,它对长度小于2^64的输入,产生长度为160bit的散列值,因此抗穷举(brute-force)性更好。SHA-1 设计时基于和MD4相同原理,并且模仿了该算法。 ) DES:Data Encryption Standard,即数据加密算法,它是IBM公司于1975年研究成功并公开发表的。 DES(数据加密标准)原理: DES是一个分组加密算法,它以64位为分组对数据加密。64位一组的明文从算法的一端输入,64位的密文从另一段输出。它是一个对称算法:加密和解密用的是同一个算法。 DES现在用的比较少,因为它的加密强度不够,能够暴力破解!!还有一个3DES,原理和DES几乎是一样的,只是使用3个密钥,对相同的数据执行三次加密,增强加密强度,但是要维护3个密钥,大大增加了维护成本! AES:(英语:Advanced Encryption Standard,缩写:AES)高级加密标准,这个标准用来替代原先的DES,已经被多方分析且广为全世界所使用。高级加密标准已然成为对称密钥加密中最流行的算法之一 AES:高级加密原理: AES 是一个新的可以用于保护电子数据的加密算法。明确地说,AES 是一个迭代的、对称密钥分组的密码,它可以使用128、192 和 256 位密钥,并且用 128 位(16字节)分组加密和解密数据。与公共密钥密码使用密钥对不同,对称密钥密码使用相同的密钥加密和解密数据。通过分组密码返回的加密数据 的位数与输入数据相同。迭代加密使用一个循环结构,在该循环中重复置换(permutations )和替换(substitutions)输入数据。Figure 1 显示了 AES 用192位密钥对一个16位字节数据块进行加密和解密的情形。 MD5:Message-Digest Algorithm 5(信息-摘要算法5),用于确保信息传输完整一致。是计算机广泛使用的杂凑算法之一(又译摘要算法、哈希算法),主流编程语言普遍已有MD5实现。这个应该是听到最多的算法,据说是已经被破解了。但是我觉得破解这个应该也要很久吧! MD5加密原理: 对MD5算法简要的叙述可以为:MD5以512位分组来处理输入的信息,且每一分组又被划分为16个32位子分组,经过了一系列的处理后,算法的输出由四个32位分组组成,将这四个32位分组级联后将生成一个128位散列值 目前破解MD5主要依靠大型字典的方法,将常用密码进行MD5后建立数据库,然后和MD5数值进行对比,通过这样的方法来“破解”MD5,因此,通常直接将密码进行MD5处理的话, 一些弱密码很容易可以通过这种手段“破解”出 来。不过,如果在散列的过程中,加入足够长的salt(即干扰字符串),并且salt加入一些动态信息,例如username、随机码等, 这样生成的MD5还是很难被破解的,因为仅仅从数据库无法看到MD5具体的处理过程,必须同时看到处理时的源代码才可以,这就给破解MD5带来相当大的难度。 RSA 加密方式相信每一个对接过支付宝SDK的同学都听过这个RSA加密,因为支付宝SDK的加密方式采用的就是这种。 它的一个大致额历程是这样: 1、生成你的公钥给支付宝,注册支付宝SDK之后你也可以拿到支付宝公钥。 2、上传你的公钥到支付宝,用你的私钥加密你的信息,支付包用你上传的公钥解密你传给支付宝的信息。 3、用你拿到的支付宝的公钥解密支付宝回调给你的信息。 注意:不要把这新秘钥信息存放在客户端,存放在服务端也建议不要使用明文的形式存储,安全问题!有些说把秘钥制作成.a文件的形式存放的客户端,问题反编译之后直接拿到你这份.a文件是不是也可以用用呢? 加密是由 *算法是DES,AES等(上面介绍过); *而模式是EBC,CBC等; *至于填充,iOS和Android的填充是不一样的: NoPadding (NoPadding就是不填充,相当于自定义填充) PKCS7Padding NoPadding ISO10126Padding OAEPPadding, OAEPWith PKCS1Padding PKCS5Padding SSL3Padding 接下来我们引入一些背景知识: 在密码学中,分组加密(Block cipher,又称分块加密),是一种对称密钥算法。它将明文分成多个等长的模块(block),使用确定的算法和对称密钥对每组分别加密解密。分组加密是极其重要的加密协议组成,其中典型的如DES和AES作为美国政府核定的标准加密算法,应用领域从电子邮件加密到银行交易转帐,非常广泛。 最早出现的工作模式,ECB,CBC,OFB和CFB可以追溯到1981年。2001年,NIST修订了其早先发布的工作模式工作列表,加入了AES,并加入了CTR模式。最后,在2010年1月,NIST加入了XTS-AES,而其余的可信模式并没有为NIST所认证。例如CTS是一种密文窃取的模式,许多常见的密码学运行库提供了这种模式。 密码学中,块密码的工作模式允许使用同一个块密码密钥对多于一块的数据进行加密,并保证其安全性。块密码自身只能加密长度等于密码块长度的单块数据,若要加密变长数据,则数据必须先被划分为一些单独的密码块。通常而言,最后一块数据也需要使用合适 初始化向量(IV,Initialization Vector)是许多工作模式中用于随机化加密的一块数据,因此可以由相同的明文,相同的密钥产生不同的密文,而无需重新产生密钥,避免了通常相当复杂的这一过程。 初始化向量与密钥相比有不同的安全性需求,因此IV通常无须保密,然而在大多数情况中,不应当在使用同一密钥的情况下两次使用同一个IV。对于CBC和CFB,重用IV会导致泄露明文首个块的某些信息,亦包括两个不同消息中相同的前缀。对于OFB和CTR而言,重用IV会导致完全失去安全性。另外,在CBC模式中,IV在加密时必须是无法预测的;特别的,在许多实现中使用的产生IV的方法,例如SSL2.0使用的,即采用上一个消息的最后一块密文作为下一个消息的IV,是不安全的。 注意:ECB模式不需要初始化向量。 块密码只能对确定长度的数据块进行处理,而消息的长度通常是可变的。因此部分模式(即ECB和CBC)需要最后一块在加密前进行填充。有数种填充方法,其中最简单的一种是在平文的最后填充空字符以使其长度为块长度的整数倍,但必须保证可以恢复平文的原始长度;例如,若平文是C语言风格的字符串,则只有串尾会有空字符。稍微复杂一点的方法则是原始的DES使用的方法,即在数据后添加一个1位,再添加足够的0位直到满足块长度的要求;若消息长度刚好符合块长度,则添加一个填充块。最复杂的则是针对CBC的方法,例如密文窃取,残块终结等,不会产生额外的密文,但会增加一些复杂度。布鲁斯·施奈尔和尼尔斯·弗格森提出了两种简单的可能性:添加一个值为128的字节(十六进制的80),再以0字节填满最后一个块;或向最后一个块填充n个值均为n的字节。 CFB,OFB和CTR模式不需要对长度不为密码块大小整数倍的消息进行特别的处理。因为这些模式是通过对块密码的输出与平文进行异或工作的。最后一个平文块(可能是不完整的)与密钥流块的前几个字节异或后,产生了与该平文块大小相同的密文块。流密码的这个特性使得它们可以应用在需要密文和平文数据长度严格相等的场合,也可以应用在以流形式传输数据而不便于进行填充的场合。 注意:ECB模式是需要填充的。 我们通过下面的两张图解释一下这两种加密模式,因为在后面的代码解读中我们会涉及到这一点,要是不了解后面代码中有些点可能会犯迷糊: 本方法的缺点在于同样的平文块会被加密成相同的密文块;因此,它不能很好的隐藏数据模式。在某些场合,这种方法不能提供严格的数据保密性,因此并不推荐用于密码协议中。下面的例子显示了ECB在密文中显示平文的模式的程度:该图像的一个位图版本(上图)通过ECB模式可能会被加密成中图,而非ECB模式通常会将其加密成最下图。 原图(1): 使用EBC加密得到的图(2): 提供了伪随机性的非ECB模式的图(3): 原图是使用CBC,CTR或任何其它的更安全的模式加密最下图可能产生的结果——与随机噪声无异。注意最下图看起来的随机性并不能表示图像已经被安全的加密;许多不安全的加密法也可能产生这种“随机的”输出。 ECB模式也会导致使用它的协议不能提供数据完整性保护,易受到重放攻击的影响,因此每个块是以完全相同的方式解密的。例如,“梦幻之星在线:蓝色脉冲”在线电子游戏使用ECB模式的Blowfish密码。在密钥交换系统被破解而产生更简单的破解方式前,作弊者重复通过发送加密的“杀死怪物”消息包以非法的快速增加经验值。 其他模式在此就不展开了,详情请转块密码的工作模式 ,进一步了解CBC、CFB、OFB、CTR等模式。 (首先说明DES由于自身的缺陷,就不再去研究看它的代码了,我们这里研究的也不会特别深,主要是为了在项目中的使用) AES: 先说说这个类: CCCryptorStatus(CC Cryptor Status,CC密码态) 关于CCCryptorStatus,构造它可以使用 理解了它的参数在我们写AES加密代码的时候是有很大的帮助的,下面是它的头文件中Apple给的参数解释,我们解释一下: 下边给出的就是具体的AES加密方式的代码,涉及到的其他的Base64编码方式等等这些我们就不在专门去写代码,这个在Demo中都有,需要的建议去翻翻Demo: (小贴士: 针对Base64位的编码方式有的第三方比如:GTMBase64 或者是针对DES的第三方比如:SSkeychain ) 有很多小伙伴可能对base64 不了解,只是平时会碰到,而且也是使用第三方,下面来介绍一下: Base64是网络上最常见的用于传输8Bit(比特)字节代码的编码方式之一。Base64编码可用于在HTTP环境下传递较长的标识信息。例如,在Java Persistence系统Hibernate中,就采用了Base64来将一个较长的唯一 标识符(一般为128-bit的UUID)编码为一个字符串,用作HTTP表单和HTTP GET URL中的参数。在其应用程序中,也常常需要把二进制数据编码为适合放在URL(包括隐藏表单域)中的形式。此时,采用Base64编码具有不可读性,即所编码的数据不会被人用肉眼所直接看到 。 Base64编码的思想是是采用 例:将对ABC进行BASE64编码: 1、首先取ABC对应的ASCII码值。A(65)B(66)C(67); 2、再取二进制值A(01000001)B(01000010)C(01000011); 3、然后把这三个字节的二进制码接起来(010000010100001001000011); 4、 再以6位为单位分成4个数据块,并在最高位填充两个0后形成4个字节的编码后的值,(00 5、再把这四个字节数据转化成10进制数得(16)(20)(9)(3); 6、最后根据BASE64给出的64个基本字符表,查出对应的ASCII码字符(Q)(U)(J)(D),这里的值实际就是数据在字符表中的索引。 解码过程就是把4个字节再还原成3个字节再根据不同的数据形式把字节数组重新整理成数据。 Base64很直观的目的就是让二进制文件转化为64个基本的ASCII码字符。 --苹果提供的Base64的API,截图如下: 参考链接: https://www.jianshu.com/p/97966d83930e https://www.cnblogs.com/taoxu/p/8602334.html https://www.jianshu.com/p/98610bdc9bd6 -------------3.哈希算法-------------
----哈希表----

-------常用HASH函数------
-------哈希处理冲突方法-------
----------------------其他加密方法详解----------------------
--------DES加密----------
密钥通常表示为64位的数,但每个第8位都用作奇偶校验,可以忽略,所以密钥长度为56位。密钥可以是任意的56位的数,且可在任意的时候改变。
DES算法只不过是加密的两个基本技术——混乱和扩散的组合,即先代替后置换,它基于密钥作用于明文,这是一轮(round),DES在明文分组上实施16轮相同的组合技术。--------AES加密----------
-------MD5加密-------
------RSA 加密方式 ------
该算法基于一个十分简单的数论事实:将两个大素数相乘十分容易,但那时想要对其乘积进行因式分解却极其困难,因此可以将乘积公开作为加密密钥,即公钥,而两个大素数组合成私钥。公钥是可发布的供任何人使用,私钥则为自己所有,供解密之用。
------------------------加密模式详解--------------------------
--------加密模式ECB、CBC--------
算法/模式/填充组成的:mac支持:而java支持:密码学中的工作模式:填充方式将数据扩展到符合密码块大小的长度。一种工作模式描述了加密每一数据块的过程,并常常使用基于一个通常称为初始化向量的附加输入值以进行随机化,以保证安全。*初始化向量:*填充:ECB:
最简单的加密模式即为电子密码本(Electronic codebook,ECB)模式。需要加密的消息按照块密码的块大小被分为数个块,并对每个块进行独立加密。 ECB:电子密码本,就是每个块都是独立加密的。
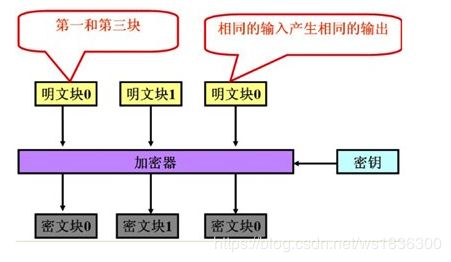



CBC:密码块链,使用一个密钥和一个初始化向量(IV)对数据执行加密转换。
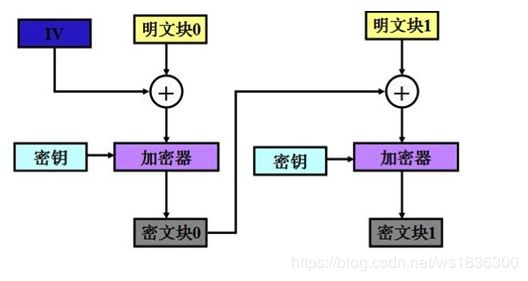
--------------代码部分 -------------
CCCrypt、 CCCryptorCreateWithMode 、CCCryptorCreate等好多类构造,在使用这些类构造时对参数是比较多,我们看着它们的头文件,解读一下参数的含义,我们就用CCCrypt为例说明一下,下面是CCCrypt的结构代码:CCCryptorStatus CCCrypt(
CCOperation op, /* kCCEncrypt, etc. */
CCAlgorithm alg, /* kCCAlgorithmAES128, etc. */
CCOptions options, /* kCCOptionPKCS7Padding, etc. */
const void *key,
size_t keyLength,
const void *iv, /* optional initialization vector */
const void *dataIn, /* optional per op and alg */
size_t dataInLength,
void *dataOut, /* data RETURNED here */
size_t dataOutAvailable,
size_t *dataOutMoved)
__OSX_AVAILABLE_STARTING(__MAC_10_4, __IPHONE_2_0);// 设置加密参数
/*!
@function CCCrypt
@abstract Stateless, one-shot encrypt or decrypt operation.
This basically performs a sequence of CCCrytorCreate(),
CCCryptorUpdate(), CCCryptorFinal(), and CCCryptorRelease().
@param alg Defines the encryption algorithm.定义加密的算法
alg:
enum {
kCCAlgorithmAES128 = 0,
kCCAlgorithmAES = 0,
kCCAlgorithmDES,
kCCAlgorithm3DES,
kCCAlgorithmCAST,
kCCAlgorithmRC4,
kCCAlgorithmRC2,
kCCAlgorithmBlowfish
};
@param op Defines the basic operation: kCCEncrypt or kCCDecrypt. 定义加密还是解密
下面是补码方式
enum {
kCCOptionPKCS7Padding = 0x0001,
kCCOptionECBMode = 0x0002};
@param options A word of flags defining options. See discussion for the CCOptions type.
// 加密的key
@param key Raw key material, length keyLength bytes.
// 加密的key的长度
@param keyLength Length of key material. Must be appropriate for the select algorithm. Some algorithms may
provide for varying key lengths.
// IV 向量
@param iv Initialization vector, optional. Used for
Cipher Block Chaining (CBC) mode. If present,
must be the same length as the selected
algorithm's block size. If CBC mode is
selected (by the absence of any mode bits in
the options flags) and no IV is present, a
NULL (all zeroes) IV will be used. This is
ignored if ECB mode is used or if a stream
cipher algorithm is selected. For sound encryption,
always initialize IV with random data.
IV向量:大概意思说,此属性可选,但只能用于CBC模式。
如果出现那么他的长度必须和算法的block size保持一致。
如果是因为默认选择的CBC模式而且向量没有定义,那么向量会被定义为NULL。
如果选择了ECB模式或是其他的流密码算法,之前所说的逻辑都不成立。
NOTE**** 如果你想使用密钥偏移量IV 那你的加密模式必须为CBC,不能使用别的模式
// 需要加密或者解密处理的data以及data的长度
@param dataIn Data to encrypt or decrypt, length dataInLength bytes.
@param dataInLength Length of data to encrypt or decrypt.
// 加密或者解密后的数据会写在这个data中 以及它的长度
@param dataOut Result is written here. Allocated by caller. Encryption and decryption can be performed "in-place",
with the same buffer used for input and output.
@param dataOutAvailable The size of the dataOut buffer in bytes.
//
@param dataOutMoved On successful return, the number of bytes written to dataOut.
If kCCBufferTooSmall is returned as a result of insufficient buffer
space being provided, the required buffer space is returned here.
//几种错误情况的说明
@result kCCBufferTooSmall indicates insufficent space in the dataOut buffer.(表明dataOut的空间不足) In this case, the *dataOutMoved
parameter will indicate the size of the buffer needed to complete the operation.
The operation can be retried with minimal runtime penalty.
kCCAlignmentError indicates that dataInLength was not properly
aligned. This can only be returned for block
ciphers, and then only when decrypting or when
encrypting with block with padding disabled.
kCCDecodeError Indicates improperly formatted ciphertext or a "wrong key" error; occurs only during decrypt operations.
我们可以通过下面的解释解读一下这个result、具体的结果可以看下面的解释
@enum CCCryptorStatus
@abstract Return values from CommonCryptor operations.
enum {
kCCSuccess Operation completed normally.
kCCParamError Illegal parameter value.
kCCBufferTooSmall Insufficent buffer provided for specified operation.
kCCMemoryFailure Memory allocation failure.
kCCAlignmentError Input size was not aligned properly.
kCCDecodeError Input data did not decode or decrypt properly.
kCCUnimplemented Function not implemented for the current algorithm.
}
*/---------AES加密代码----------
- (NSData *)aes256_encrypt:(NSString *)key //加密
{
// kCCKeySizeAES256是加密位数
/*
enum {
kCCKeySizeAES128 = 16,
kCCKeySizeAES192 = 24,
kCCKeySizeAES256 = 32,
kCCKeySizeDES = 8,
kCCKeySize3DES = 24,
kCCKeySizeMinCAST = 5,
kCCKeySizeMaxCAST = 16,
kCCKeySizeMinRC4 = 1,
kCCKeySizeMaxRC4 = 512,
kCCKeySizeMinRC2 = 1,
kCCKeySizeMaxRC2 = 128,
kCCKeySizeMinBlowfish = 8,
kCCKeySizeMaxBlowfish = 56,
};
*/
char keyPtr[kCCKeySizeAES256+1];
bzero(keyPtr, sizeof(keyPtr));
[key getCString:keyPtr maxLength:sizeof(keyPtr) encoding:NSUTF8StringEncoding];
//IV
NSUInteger dataLength = [self length];
size_t bufferSize = dataLength + kCCBlockSizeAES128;
void * buffer = malloc(bufferSize);
size_t numBytesEncrypted = 0;
CCCryptorStatus cryptStatus = CCCrypt(kCCEncrypt, kCCAlgorithmAES128,
kCCOptionPKCS7Padding | kCCOptionECBMode,
keyPtr, kCCBlockSizeAES128,
NULL,
[self bytes], dataLength,
buffer, bufferSize,
&numBytesEncrypted);
if (cryptStatus == kCCSuccess) {
return [NSData dataWithBytesNoCopy:buffer length:numBytesEncrypted];
}
free(buffer);
return nil;
}
-(NSData *)aes256_decrypt:(NSString *)key //解密
{
//key 处理
char keyPtr[kCCKeySizeAES256+1];
bzero(keyPtr, sizeof(keyPtr));
[key getCString:keyPtr maxLength:sizeof(keyPtr) encoding:NSUTF8StringEncoding];
/*IV
char ivPtr[kCCBlockSizeAES128 + 1];
bzero(ivPtr, sizeof(ivPtr));
[iv getCString:ivPtr maxLength:sizeof(ivPtr) encoding:NSUTF8StringEncoding];
*/
// 输出对象
NSUInteger dataLength = [self length];
size_t bufferSize = dataLength + kCCBlockSizeAES128;
void *buffer = malloc(bufferSize);
size_t numBytesDecrypted = 0;
//kCCDecrypt 解密
CCCryptorStatus cryptStatus = CCCrypt(kCCDecrypt, kCCAlgorithmAES128,
kCCOptionPKCS7Padding | kCCOptionECBMode,
keyPtr, kCCBlockSizeAES128,
NULL,
[self bytes], dataLength,
buffer, bufferSize,
&numBytesDecrypted);
if (cryptStatus == kCCSuccess) {
return [NSData dataWithBytesNoCopy:buffer length:numBytesDecrypted];
}
free(buffer);
return nil;
}--------------------又是一道华丽的分割线-------------------
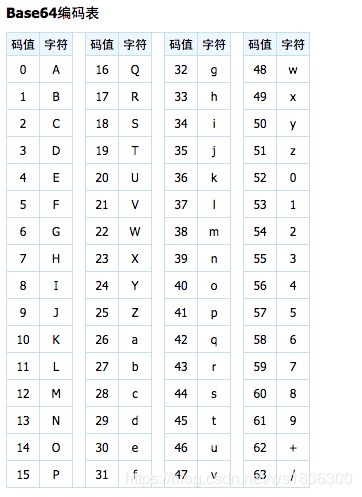
------Base64 编码-------
64个基本的ASCII码字符对数据进行重新编码。它将需要编码的数据拆分成字节数组。以3个字节为一组。按顺序排列24 位数据,再把这24位数据分成4组,即每组6位。再在每组的的最高位前补两个0凑足一个字节。这样就把一个3字节为一组的数据重新编码成了4个字节。当所要编码的数据的字节数不是3的整倍数,也就是说在分组时最后一组不够3个字节。这时在最后一组填充1到2个0字节。并在最后编码完成后在结尾添加1到2个 “=”。010000)(00010100)(00001001)(00000011),其中加色部分为真实数据;