论文笔记:神经网络架构搜索NAS和ENAS
1.介绍
1.1.介绍
在论文《NEURAL ARCHITECTURE SEARCH WITH REINFORCEMENT LEARNING》中首次提出了NAS(神经网络架构搜索NEURAL ARCHITECTURE SEARCH),本文首先翻译总结了下此篇内容。接着根据《Efficient Neural Architecture Search via Parameter Sharing》写了ENAS。
近几年,深度神经网络取得非常多的成功,从特征设计到架构设计,从SIFT、HOG到AlexNet、VGGNet、GoogleNet、ResNet。设计架构需要相当多的专业知识与很多的时间。
一个神经网络的结构和连接可以定义为一个可变长度的字符串,所以它是有可能采用recurrent network 作为controller来生成的。
总的来说,NAS采用RNN作为控制器(controller),利用强化学习,可以生成卷积网络、循环神经网络等,而且生成的网络架构的深度可以不固定。NAS生成的神经网络架构的测试数据集上表现也不比人工设计的网络架构差,甚至优化人工设计的。对于自动化学习,开启了一个新的研究方向。
NAS训练成本非常高,比如450个cpu训练3-4天,所以提出了ENAS。CPU-HOURS 减少了1000倍。
2.NAS 方法
首先描述一个简单的方法,使用recurrent network 来生成卷积架构。采用策略梯度方法训练 recurrent network,以最大化采样架构的预期正确率。
2.1.生成模型
在NAS中,采用一个控制器来生成神经网络的架构超参数。为了灵活,这个控制器采用RNN(recurrent neural network)。我们假定我们想要预测一个仅有卷积层的前馈网络,那么我们就可以使用控制器来生成他们的超参数,超参数可以看作一个token序列。
如下图所示,演示了控制器如何采样一个简单的卷积网络。控制器预测每层中过滤器的高、宽,stride的高、宽,以及过滤器的数量。每一个预测用一个softmax 分类器执行,然后传入到下一步,

在我们实验中,如果层的数量超过某个值,我们就结束网络架构的生成。一旦控制器RNN完成了网络架构的生成,带有这个架构的神经网络就会被建立并进行训练。收敛时,该网络在验证集上的准确率会被记录下来。
控制器RNN的参数![]()
然后被优化,以便获得最大的期望验证准确率。
下面章节描述下采用策略梯度算法更新参数![]()
,以致于控制器可以生成更好的网络架构。
2.2.强化训练
控制器预测的token序列,可以看做一系列动作![]()
,用来设计子网络的架构。
在收敛时,子网络基于验证集产生一个准确率R。我们使用该准确率R作为奖励信号,然后采用强化学习来训练控制器。更准确的说,为了找到最优的网络架构,我们让控制器来最大化其期望奖励,用![]()
表示,公式如下:
![]()
因为奖励信号R不是可微分的,所以采用策略梯度方法迭代更新。我们使用了Williams(1992)的强化学习规则,如下式:
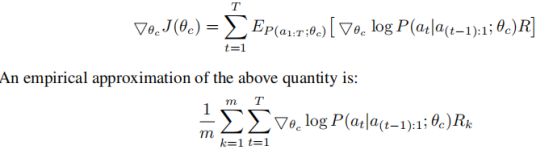
其中m是不同架构的数量(控制器在一个批次中采样的架构数量),T是控制器的超参数数量。
上面的更新对于梯度是一个无偏估计,但有非常大的方法,为了减小方程,我们引入了一个基线方程b。
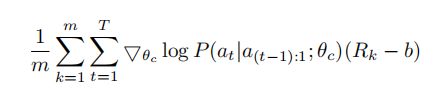
只要b不依赖于当前的action,这依旧是一个无偏梯度估计。我们采用的b是一个前面网络架构准确率的指数移动平均。
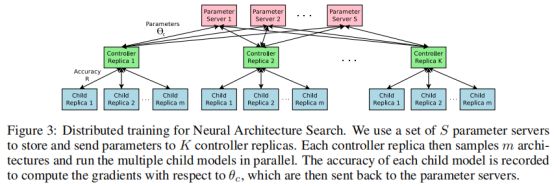
2.3.并行与异步更新
为了提升训练速度,我们采用的并行与异步更新。如下图所示,采用了S个参数服务器(parameter server),他们发送参数到K个控制器副本,每一个控制器采样m个网络架构。每个子模型的准确率被记录下来(用来计算![]()
的梯度),然后发回个参数服务器。
2.4.采用跳跃连接增加网络架构复杂度
采用set-selection attention 方法使控制器可以预测跳跃连接。可以看到如下图,添加了anchor point。
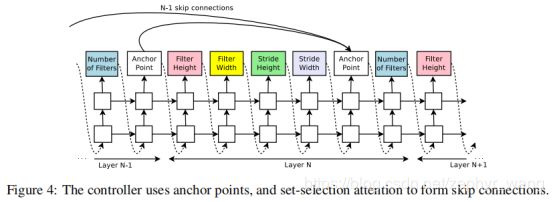
对于第N层的anchor point, 有N-1个sigmoid函数来描述前面哪一个层是需要连接到本层的。函数如下,每个sigmoid函数是基于 控制器的当前隐状态和前面N-1个anchor point的前隐状态。

2.5.生成循环单元架构
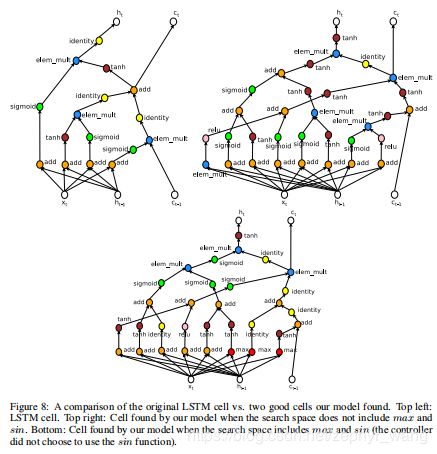
可以用控制器生成类似RNN、LSTM那样的循环神经单元。基本的RNN和LSTM单元的计算一般可以用一个树来表示,xt和ht-1是输入,ht是输出。下图展示了只有两个叶子节点的情况,本论文使用了8个叶子节点来确保循环单元是有表现力的。

计算步骤如下:

3.NAS实验结果
3.1.基于CIFAR-10的NAS卷积训练
CIFAR-10 数据集可以用来图片识别。我们使用该数据集用NAS来生成一个卷积网络架构。
控制器:采用两层的LSTM作为控制器,没层有35个隐单元。
在分布式训练中,有S=20个参数服务器,控制器数量K=100,子网络m=8,所以共有800个网络要被训练,在800个CPU上。
一旦一个控制器找到一个子网络,每个子网络将训练50 epochs。
我们让控制器在对子网络每1600次采样后,增加2层,初始为6层。
训练结果:发现控制器在训练了12800个架构后,架构可以获得很好的验证准确率。然后运行一个小的网格搜索,直到最好的模型进行收敛。然后计算该模型的测试准确率,结果如下表。
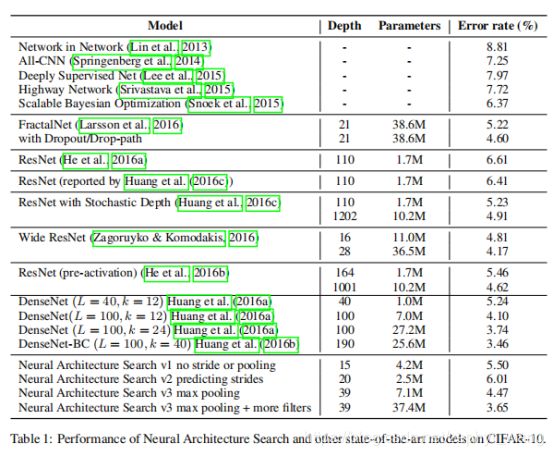
生成的神经网络架构如下图所示,可以看到有许多矩形的过滤器,而且越上层的过滤器越大:

3.2.基于Penn Treebank数据集的循环神经单元训练
Penn treebank 数据集是一个非常知名的语音模型数据集。在该数据集上LSTM模型表现非常好,已经难以超越。
控制器对于树中的每个节点,在[add、elem_mult]中选择结合方法,在[identity、tanh、sigmoid、relu]中选择激活函数。叶子节点数选用8.
在分布式训练中,有S=20个参数服务器,控制器数量K=400,子网络m=1,所以共有400个网络要被训练,在400个CPU上。
实验结果如下:
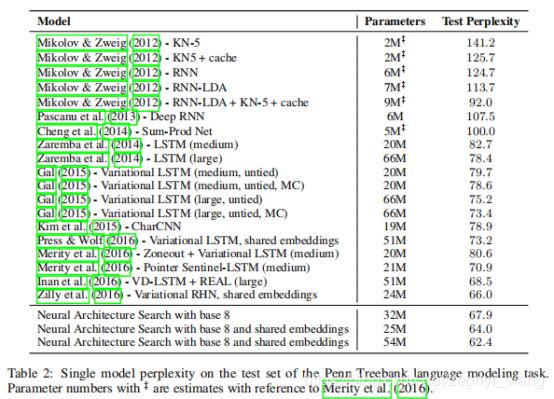
生成了循环神经单元如下,可以看到和LSTM的非常相似,左上是LSTM的,右上是我们生成的。
4.ENAS
NAS的计算成本非常高,时间也长,比如需要450个cpu运行3-4天。我们发现NAS的计算瓶颈是每个子网络训练的收敛,最终只是拿到准确率而扔掉了已经训练好的权重。
ENAS(efficient neural architecture search)改进NAS的效率,主要是强迫所有子模型共享权重,这样可以避免每个子模型从零开始训练到收敛。CPU-HOURS 减少了1000倍。
NAS结束迭代产生的所有图可以看做一个大图的子图,换句话说,我们可以将NAS的搜索空间用一个单向非循环图(DAG:directed acyclic graph)表示。下图描述了一个简单的DAG,这样一个网络结构可以看做DAG的一个子图。直观上,ENAS的DAG是在NAS搜索空间中所有可能子模型的叠加,其中节点代表着本地计算,边代表着信息流。在每个节点的本地计算拥有自己的参数,仅当特别的计算被激活才会被使用。所以ENAS容许参数在所以子节点模型中共享。

4.1.循环神经单元的设计
为了设计循环神经单元,我们采用带有N个节点的DAG,其中每个节点代表本地计算,每条边代表在N个节点间的信息流。ENAS的控制器决定(1)哪个边是被激活;(2)哪个计算在节点表现。我们的搜索空间容许ENAS来设计循环神经单元的拓扑结构与操作。
下图是4个计算节点的示例。

计算过程如下:

如上所述,有很多独立参数矩阵W,控制器决定哪个参数矩阵会被使用。所以在ENAS,在搜索空间中所有的循环神经单元共享参数。
4.2.ENAS训练
在ENAS有两组参数需要学习,一组是控制器(采用LSTM)的参数θ,一组是子模型们的共享参数w。
子模型们共享参数w的训练:固定控制器策略Π(m;θ),采用随机梯度下降SGD,基于w最小化期望损失E。采用的标准交叉熵损失。模型m从Π(m;θ)中采样。梯度计算采样monte carlo 估计。
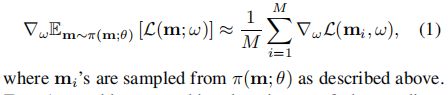
控制器参数训练:固定共享参数w,采用强化学习更新控制器参数θ,目标是最大化期望奖励![]()
获取最终网络结构:我们首先从训练策略Π(m;θ)中采样几个模型。对于每一个采样的模型,我们在一个小的批量验证集上计算他的奖励。我们然后将高奖励的模型重新从零开始训练。
4.3.设计卷积网络或卷积单元
ENAS可以设计整个卷积网络;也可以设计单个卷积单元,然后将他们连接起来构成个网络。
4.4.CIFAR-10训练结果
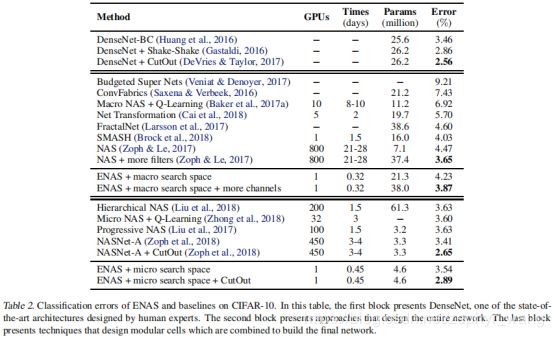
可以看到cpu只用一个,而不是几百个,时间也减少到0.45day,准确率也很好。
设计网络结构如下:
