基于consul实现微服务的服务发现和负载均衡
一. 背景
随着2018年年初国务院办公厅联合多个部委共同发布了《国务院办公厅关于促进“互联网+医疗健康”发展的意见(国办发〔2018〕26号)》,国内医疗IT领域又迎来了一波互联网医院建设的高潮。不过互联网医院多基于实体医院建设,虽说挂了一个“互联网”的名号,但互联网医院系统也多与传统的院内系统,比如:HIS、LIS、PACS、EMR等共享院内的IT基础设施。
如果你略微了解过国内医院院内IT系统的现状,你就知道目前的多数医院的IT系统相比于互联网行业、电信等行业来说是相对“落伍”的,这种落伍不仅体现在IT基础设施的专业性和数量上,更体现在对新概念、新技术、新设计理念等应用上。虽然国内医院IT系统在技术层面呈现出“多样性”的特征,但整体上偏陈旧和保守 – - 你可以在全国范围内找到10-15年前的各种主流语言(VB、delphi、c#等实现的IT系统,并且系统架构多为两层C/S结构的。
近几年“互联网+医疗”的兴起的确在一些方面提升了医院的服务效率和水平,但这些互联网医疗系统多部署于院外,并主要集中在“做入口”。它们并不算是医院的核心系统:即没有这些互联网系统,医院的业务也是照常进行的(患者可以在传统的窗口办理所有院内业务,就是效率低罢了)。因此,虽然这些互联网医疗系统采用了先进的互联网系统设计理念和技术,但并没有真正提升院内系统的技术水平,它们也只能与院内那些“陈旧”的、难于扩展的系统做对接。
不过互联网医院与这些系统有所不同,虽然它依然“可有可无”,但它却是部署在院内IT基础设施上的系统,同时也受到了院内IT基础设施条件的限制。在我们即将上线的一个针对医院集团的互联网医院版本中,我们就遇到了“被限制”的问题。我们本想上线的Kubernetes集群因为院方提供的硬件“不足”而无法实施,只能“降级”为手工打造的基于consul的微服务服务发现和负载均衡平台,初步满足我们的系统需要。而从k8s到consul的实践过程,总是让我有一种从工业时代回到的农业时代或是“消费降级”的赶脚^_^。
本文就来说说基于当前较新版本的consul实现微服务的服务发现和负载均衡的过程。
二. 实验环境
这里有三台阿里云的ECS,即用作部署consul集群,也用来承载工作负载的节点(这点与真实生产环境还是蛮像的,医院也仅能提供类似的这点儿可怜的设备):
- consul-1: 192.168.0.129
- consul-2: 192.168.0.130
- consul-3: 192.168.0.131
操作系统:Ubuntu server 16.04.4 LTS
内核版本:4.4.0-117-generic
实验环境安装有:
- Docker 17.03.3-ce
- consul v1.1.0
- consul-template 0.19.5
- nginx 1.10.3
- registrator master版本
- Go 1.11版本
实验所用的样例程序镜像:
- httpfrontservice
- httpbackendservice
- tcpfrontservice
三. 目标及方案原理
本次实验的最基础、最朴素的两个目标:
- 所有业务应用均基于容器运行
- 某业务服务容器启动后,会被自动注册服务,同时其他服务可以自动发现该服务并调用,并且到达这个服务的请求会负载均衡到服务的多个实例。
这里选择了与编程语言技术栈无关的、可搭建微服务的服务发现和负载均衡的Hashicorp的consul。关于consul是什么以及其基本原理和应用,可以参见我多年前写的这篇有关consul的文章。
但是光有consul还不够,我们还需要结合consul-template、gliderlab的registrator以及nginx共同来实现上述目标,原理示意图如下:
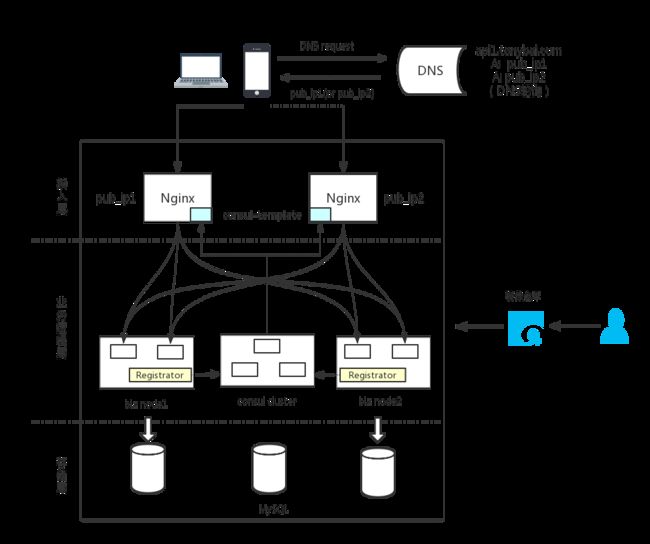
原理说明:
- 对于每个biz node上启动的容器,位于每个node上的Registrator实例会监听到该节点上容器的创建和停止的event,并将容器的信息以consul service的形式写入consul或从consul删除。
- 位于每个nginx node上的consul-template实例会watch consul集群,监听到consul service的相关event,并将需要expose到external的service信息获取,按照事先定义好的nginx conf template重新生成nginx.conf并reload本节点的nginx,使得nginx的新配置生效。
- 对于内部服务来说(不通过nginx暴露到外部),在被registrator写入consul的同时,也完成了在consul DNS的注册,其他服务可以通过特定域名的方式获取该内部服务的IP列表(A地址)和其他信息,比如端口(SRV),并进而实现与这些内部服务的通信。
参考该原理,落地到我们实验环境的部署示意图如下:

四. 步骤
下面说说详细的实验步骤。
1. 安装consul集群
首先我们先来安装consul集群。consul既支持二进制程序直接部署,也支持Docker容器化部署。如果consul集群单独部署在几个专用节点上,那么consul可以使用二种方式的任何一种。但是如果consul所在节点还承载工作负载,考虑consul作为整个分布式平台的核心,降低它与docker engine引擎的耦合(docker engine可能会因各种情况经常restart),还是建议以二进制程序形式直接部署在物理机或vm上。这里的实验环境资源有限,我们采用的是以二进制程序形式直接部署的方式。
consul最新版本是1.2.2(截至发稿时),consul 1.2.x版本与consul 1.1.x版本最大的不同在于consul 1.2.x支持service mesh了,这对于consul来说可是革新性的变化,因此这里担心其初期的稳定性,因此我们选择consul 1.1.0版本。
我们下载consul 1.1.0安装包后,将其解压到/usr/local/bin下。
在$HOME下建立consul-install目录,并在其下面存放consul集群的运行目录consul-data。在consul-install目录下,执行命令启动节点consul-1上的consul:
consul-1 node:
# nohup consul agent -server -ui -dns-port=53 -bootstrap-expect=3 -data-dir=/root/consul-install/consul-data -node=consul-1 -client=0.0.0.0 -bind=192.168.0.129 -datacenter=dc1 > consul-1.log & 2>&1
# tail -100f consul-1.log
bootstrap_expect > 0: expecting 3 servers
==> Starting Consul agent...
==> Consul agent running!
Version: 'v1.1.0'
Node ID: 'd23b9495-4caa-9ef2-a1d5-7f20aa39fd15'
Node name: 'consul-1'
Datacenter: 'dc1' (Segment: '')
Server: true (Bootstrap: false)
Client Addr: [0.0.0.0] (HTTP: 8500, HTTPS: -1, DNS: 53)
Cluster Addr: 192.168.0.129 (LAN: 8301, WAN: 8302)
Encrypt: Gossip: false, TLS-Outgoing: false, TLS-Incoming: false
==> Log data will now stream in as it occurs:
2018/09/10 10:21:09 [INFO] raft: Initial configuration (index=0): []
2018/09/10 10:21:09 [INFO] raft: Node at 192.168.0.129:8300 [Follower] entering Follower state (Leader: "")
2018/09/10 10:21:09 [INFO] serf: EventMemberJoin: consul-1.dc1 192.168.0.129
2018/09/10 10:21:09 [INFO] serf: EventMemberJoin: consul-1 192.168.0.129
2018/09/10 10:21:09 [INFO] consul: Adding LAN server consul-1 (Addr: tcp/192.168.0.129:8300) (DC: dc1)
2018/09/10 10:21:09 [INFO] consul: Handled member-join event for server "consul-1.dc1" in area "wan"
2018/09/10 10:21:09 [INFO] agent: Started DNS server 0.0.0.0:53 (tcp)
2018/09/10 10:21:09 [INFO] agent: Started DNS server 0.0.0.0:53 (udp)
2018/09/10 10:21:09 [INFO] agent: Started HTTP server on [::]:8500 (tcp)
2018/09/10 10:21:09 [INFO] agent: started state syncer
==> Newer Consul version available: 1.2.2 (currently running: 1.1.0)
2018/09/10 10:21:15 [WARN] raft: no known peers, aborting election
2018/09/10 10:21:17 [ERR] agent: failed to sync remote state: No cluster leader
我们的三个节点的consul都以server角色启动(consul agent -server),consul集群初始有三个node( -bootstrap-expect=3),均位于dc1 datacenter(-datacenter=dc1),服务bind地址为192.168.0.129(-bind=192.168.0.129 ),允许任意client连接( -client=0.0.0.0)。我们启动了consul ui(-ui),便于以图形化的方式查看consul集群的状态。我们设置了consul DNS服务的端口号为53(-dns-port=53),这个后续会起到重要作用,这里先埋下小伏笔。
这里我们使用nohup+&符号的方式将consul运行于后台。生产环境建议使用systemd这样的init系统对consul的启停和配置更新进行管理。
从consul-1的输出日志来看,单节点并没有选出leader。我们需要继续在consul-2和consul-3两个节点上也重复consul-1上的操作,启动consul:
consul-2 node:
#nohup consul agent -server -ui -dns-port=53 -bootstrap-expect=3 -data-dir=/root/consul-install/consul-data -node=consul-2 -client=0.0.0.0 -bind=192.168.0.130 -datacenter=dc1 -join 192.168.0.129 > consul-2.log & 2>&1
consul-3 node:
# nohup consul agent -server -ui -dns-port=53 -bootstrap-expect=3 -data-dir=/root/consul-install/consul-data -node=consul-3 -client=0.0.0.0 -bind=192.168.0.131 -datacenter=dc1 -join 192.168.0.129 > consul-3.log & 2>&1
启动后,我们查看到consul-3.log中的日志:
2018/09/10 10:24:01 [INFO] consul: New leader elected: consul-3
2018/09/10 10:24:01 [WARN] raft: AppendEntries to {Voter a215865f-dba7-5caa-cfb3-6850316199a3 192.168.0.130:8300} rejected, sending older logs (next: 1)
2018/09/10 10:24:01 [INFO] raft: pipelining replication to peer {Voter a215865f-dba7-5caa-cfb3-6850316199a3 192.168.0.130:8300}
2018/09/10 10:24:01 [WARN] raft: AppendEntries to {Voter d23b9495-4caa-9ef2-a1d5-7f20aa39fd15 192.168.0.129:8300} rejected, sending older logs (next: 1)
2018/09/10 10:24:01 [INFO] raft: pipelining replication to peer {Voter d23b9495-4caa-9ef2-a1d5-7f20aa39fd15 192.168.0.129:8300}
2018/09/10 10:24:01 [INFO] consul: member 'consul-1' joined, marking health alive
2018/09/10 10:24:01 [INFO] consul: member 'consul-2' joined, marking health alive
2018/09/10 10:24:01 [INFO] consul: member 'consul-3' joined, marking health alive
2018/09/10 10:24:01 [INFO] agent: Synced node info
==> Newer Consul version available: 1.2.2 (currently running: 1.1.0)
consul-3 node上的consul被选为初始leader了。我们可以通过consul提供的子命令查看集群状态:
# consul operator raft list-peers
Node ID Address State Voter RaftProtocol
consul-3 0020b7aa-486a-5b44-b5fd-be000a380a89 192.168.0.131:8300 leader true 3
consul-1 d23b9495-4caa-9ef2-a1d5-7f20aa39fd15 192.168.0.129:8300 follower true 3
consul-2 a215865f-dba7-5caa-cfb3-6850316199a3 192.168.0.130:8300 follower true 3
我们还可以通过consul ui以图形化方式查看集群状态和集群内存储的各种配置信息:

至此,consul集群就搭建ok了。
2. 安装Nginx、consul-template和Registrator
根据前面的“部署示意图”,我们在consul-1和consul-2上安装nginx、consul-template和Registrator,在consul-3上安装Registrator。
a) Nginx的安装
我们使用ubuntu 16.04.4默认源中的nginx版本:1.10.3,通过apt-get install nginx安装nginx,这个无须赘述了。
b) consul-template的安装
consul-template是一个将consul集群中存储的信息转换为文件形式的工具。常用的场景是监听consul集群中数据的变化,并结合模板将数据持久化到某个文件中,再执行某一关联的action。比如我们这里通过consul-template监听consul集群中service信息的变化,并将service信息数据与nginx的配置模板结合,生成nginx可用的nginx.conf配置文件,并驱动nginx重新reload配置文件,使得nginx的配置更新生效。因此一般来说,哪里部署有nginx,我们就应该有一个配对的consul-template部署。
在我们的实验环境中consul-1和consul-2两个节点部署了nginx,因此我们需要在consul-1和consul-2两个节点上部署consul-template。我们直接安装comsul-template的二进制程序(我们使用0.19.5版本),下载安装包并解压后,将consul-template放入/usr/local/bin目录下:
# wget -c https://releases.hashicorp.com/consul-template/0.19.5/consul-template_0.19.5_linux_amd64.zip
# unzip consul-template_0.19.5_linux_amd64.zip
# mv consul-tempate /usr/local/bin
# consul-template -v
consul-template v0.19.5 (57b6c71)
这里先不启动consul-template,后续在注册不同服务的场景中,我们再启动consul-template。
c) Registrator的安装
Registrator是另外一种工具,它监听Docker引擎上发生的容器创建和停止事件,并将启动的容器信息以consul service的形式存储在consul集群中。因此,Registrator和node上的docker engine对应,有docker engine部署的节点上都应该安装有对应的Registator。因此我们要在实验环境的三个节点上都部署Registrator。
Registrator官方推荐的就是以Docker容器方式运行,但这里我并不使用lastest版本,而是用master版本,因为只有最新的master版本才支持service meta数据的写入,而当前的latest版本是v7版本,年头较长,并不支持service meta数据写入。
在所有实验环境节点上执行:
# docker run --restart=always -d \
--name=registrator \
--net=host \
--volume=/var/run/docker.sock:/tmp/docker.sock \
gliderlabs/registrator:master\
consul://localhost:8500
我们看到registrator将node节点上的/var/run/docker.sock映射到容器内部的/tmp/docker.sock上,通过这种方式registrator可以监听到node上docker引擎上的事件变化。registrator的另外一个参数:consul://localhost:8500则是Registrator要写入信息的consul地址(当然Registrator不仅仅支持consul,还支持etcd、zookeeper等),这里传入的是本node上consul server的地址和服务端口。
Registrator的启动日志如下:
# docker logs -f registrator
2018/09/10 05:56:39 Starting registrator v7 ...
2018/09/10 05:56:39 Using consul adapter: consul://localhost:8500
2018/09/10 05:56:39 Connecting to backend (0/0)
2018/09/10 05:56:39 consul: current leader 192.168.0.130:8300
2018/09/10 05:56:39 Listening for Docker events ...
2018/09/10 05:56:39 Syncing services on 1 containers
2018/09/10 05:56:39 ignored: 6ef6ae966ee5 no published ports
在所有节点都启动完Registrator后,我们来先查看一下当前consul集群中service的catelog以及每个catelog下的service的详细信息:
// consul-1:
# curl http://localhost:8500/v1/catalog/services
{"consul":[]}
目前只有consul自己内置的consul service catelog,我们查看一下consul这个catelog service的详细信息:
// consul-1:
# curl localhost:8500/v1/catalog/service/consul|jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1189 100 1189 0 0 180k 0 --:--:-- --:--:-- --:--:-- 193k
[
{
"ID": "d23b9495-4caa-9ef2-a1d5-7f20aa39fd15",
"Node": "consul-1",
"Address": "192.168.0.129",
"Datacenter": "dc1",
"TaggedAddresses": {
"lan": "192.168.0.129",
"wan": "192.168.0.129"
},
"NodeMeta": {
"consul-network-segment": ""
},
"ServiceID": "consul",
"ServiceName": "consul",
"ServiceTags": [],
"ServiceAddress": "",
"ServiceMeta": {},
"ServicePort": 8300,
"ServiceEnableTagOverride": false,
"CreateIndex": 5,
"ModifyIndex": 5
},
{
"ID": "a215865f-dba7-5caa-cfb3-6850316199a3",
"Node": "consul-2",
"Address": "192.168.0.130",
"Datacenter": "dc1",
"TaggedAddresses": {
"lan": "192.168.0.130",
"wan": "192.168.0.130"
},
"NodeMeta": {
"consul-network-segment": ""
},
"ServiceID": "consul",
"ServiceName": "consul",
"ServiceTags": [],
"ServiceAddress": "",
"ServiceMeta": {},
"ServicePort": 8300,
"ServiceEnableTagOverride": false,
"CreateIndex": 6,
"ModifyIndex": 6
},
{
"ID": "0020b7aa-486a-5b44-b5fd-be000a380a89",
"Node": "consul-3",
"Address": "192.168.0.131",
"Datacenter": "dc1",
"TaggedAddresses": {
"lan": "192.168.0.131",
"wan": "192.168.0.131"
},
"NodeMeta": {
"consul-network-segment": ""
},
"ServiceID": "consul",
"ServiceName": "consul",
"ServiceTags": [],
"ServiceAddress": "",
"ServiceMeta": {},
"ServicePort": 8300,
"ServiceEnableTagOverride": false,
"CreateIndex": 7,
"ModifyIndex": 7
}
]
3. 内部http服务的注册和发现
对于微服务而言,有暴露到外面的,也有仅运行在内部,被内部服务调用的。我们先来看看内部服务,这里以一个http服务为例。
对于暴露到外部的微服务而言,可以通过域名、路径、端口等来发现。但是对于内部服务,我们怎么发现呢?k8s中我们可以通过k8s集群的DNS插件进行自动域名解析实现,每个pod中container的DNS server指向的就是k8s dns server。这样service之间可以通过使用固定规则的域名(比如:your_svc.default.svc.cluster.local)来访问到另外一个service(仅需配置一个service name),再通过service实现该服务请求负载均衡到service关联的后端endpoint(pod container)上。consul集群也可以做到这点,并使用consul提供的DNS服务来实现内部服务的发现。
我们需要对三个节点的DNS配置进行update,将consul DNS server加入到主机DNS resolver(这也是之前在启动consul时将consul DNS的默认监听端口从8600改为53的原因),步骤如下:
- 编辑/etc/resolvconf/resolv.conf.d/base,加入一行:
nameserver 127.0.0.1
- 重启resolveconf服务
/etc/init.d/resolvconf restart
再查看/etc/resolve.conf文件:
# cat /etc/resolv.conf
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
nameserver 100.100.2.136
nameserver 100.100.2.138
nameserver 127.0.0.1
options timeout:2 attempts:3 rotate single-request-reopen
我们发现127.0.0.1这个DNS server地址已经被加入到/etc/resolv.conf中了(切记:不要直接手工修改/etc/resolve.conf)。
好了!有了consul DNS,我们就可以发现consul中的服务了。consul给其集群内部的service一个默认的域名:your_svc.service.{data-center}.consul. 之前我们查看了cluster中只有一个consul catelog service,我们就来访问一下该consul service:
# ping -c 3 consul.service.dc1.consul
PING consul.service.dc1.consul (192.168.0.129) 56(84) bytes of data.
64 bytes from iZbp15tvx7it019hvy750tZ (192.168.0.129): icmp_seq=1 ttl=64 time=0.029 ms
64 bytes from iZbp15tvx7it019hvy750tZ (192.168.0.129): icmp_seq=2 ttl=64 time=0.025 ms
64 bytes from iZbp15tvx7it019hvy750tZ (192.168.0.129): icmp_seq=3 ttl=64 time=0.031 ms
# ping -c 3 consul.service.dc1.consul
PING consul.service.dc1.consul (192.168.0.130) 56(84) bytes of data.
64 bytes from 192.168.0.130: icmp_seq=1 ttl=64 time=0.186 ms
64 bytes from 192.168.0.130: icmp_seq=2 ttl=64 time=0.136 ms
64 bytes from 192.168.0.130: icmp_seq=3 ttl=64 time=0.195 ms
# ping -c 3 consul.service.dc1.consul
PING consul.service.dc1.consul (192.168.0.131) 56(84) bytes of data.
64 bytes from 192.168.0.131: icmp_seq=1 ttl=64 time=0.149 ms
64 bytes from 192.168.0.131: icmp_seq=2 ttl=64 time=0.184 ms
64 bytes from 192.168.0.131: icmp_seq=3 ttl=64 time=0.179 ms
我们看到consul服务有三个实例,因此DNS轮询在不同ping命令执行时返回了不同的地址。
现在在主机层面上,我们可以发现consul中的service了。如果我们的服务调用者跑在docker container中,我们还能找到consul服务么?
# docker run busybox ping consul.service.dc1.consul
ping: bad address 'consul.service.dc1.consul'
事实告诉我们:不行!
那么我们如何让运行于docker container中的服务调用者也能发现consul中的service呢?我们需要给docker引擎指定DNS:
在/etc/docker/daemon.json中添加下面配置:
{
"dns": ["node_ip", "8.8.8.8"] //node_ip: consul_1为192.168.0.129、consul_2为192.168.0.130、consul_3为192.168.0.131
}
重启docker引擎后,再尝试在容器内发现consul服务:
# docker run busybox ping consul.service.dc1.consul
PING consul.service.dc1.consul (192.168.0.131): 56 data bytes
64 bytes from 192.168.0.131: seq=0 ttl=63 time=0.268 ms
64 bytes from 192.168.0.131: seq=1 ttl=63 time=0.245 ms
64 bytes from 192.168.0.131: seq=2 ttl=63 time=0.235 ms
这次就ok了!
接下来我们在三个节点上以容器方式启动我们的一个内部http服务demo httpbackend:
# docker run --restart=always -d -l "SERVICE_NAME=httpbackend" -p 8081:8081 bigwhite/httpbackendservice:v1.0.0
我们查看一下consul集群内的httpbackend service信息:
# curl localhost:8500/v1/catalog/service/httpbackend|jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1374 100 1374 0 0 519k 0 --:--:-- --:--:-- --:--:-- 670k
[
{
"ID": "d23b9495-4caa-9ef2-a1d5-7f20aa39fd15",
"Node": "consul-1",
"Address": "192.168.0.129",
...
},
{
"ID": "a215865f-dba7-5caa-cfb3-6850316199a3",
"Node": "consul-2",
"Address": "192.168.0.130",
...
},
{
"ID": "0020b7aa-486a-5b44-b5fd-be000a380a89",
"Node": "consul-3",
"Address": "192.168.0.131",
...
}
]
再访问一下该服务:
# curl httpbackend.service.dc1.consul:8081
this is httpbackendservice, version: v1.0.0
内部服务发现成功!
4. 暴露外部http服务
说完了内部服务,我们再来说说那些要暴露到外部的服务,这个环节就轮到consul-template登场了!在我们的实验中,consul-template读取consul中service信息,并结合模板生成nginx配置文件。我们基于默认安装的/etc/nginx/nginx.conf文件内容来编写我们的模板。我们先实验暴露http服务到外面。下面是模板样例:
//nginx.conf.template
.... ...
http {
... ...
##
# Virtual Host Configs
##
include /etc/nginx/conf.d/*.conf;
include /etc/nginx/sites-enabled/*;
#
# http server config
#
{{range services -}}
{{$name := .Name}}
{{$service := service .Name}}
{{- if in .Tags "http" -}}
upstream {{$name}} {
zone upstream-{{$name}} 64k;
{{range $service}}
server {{.Address}}:{{.Port}} max_fails=3 fail_timeout=60 weight=1;
{{end}}
}{{end}}
{{end}}
{{- range services -}} {{$name := .Name}}
{{- if in .Tags "http" -}}
server {
listen 80;
server_name {{$name}}.tonybai.com;
location / {
proxy_pass http://{{$name}};
}
}
{{end}}
{{end}}
}
consul-template使用的模板采用的是go template的语法。我们看到在http block中,我们要为consul中的每个要expose到外部的catelog service定义一个server block(对应的域名为your_svc.tonybai.com)和一个upstream block。
对上面的模板做简单的解析,弄明白三点,模板基本就全明白了:
- {{- range services -}}: 标准的{{ range pipeline }}模板语法,services这个pipeline的调用相当于: curl localhost:8500/v1/catalog/services,即获取catelog services列表。这个列表中的每项仅有Name和Tags两个字段可用。
- {{- if in .Tags “http” -}}:判断语句,即如果Tags字段中有http这个tag,那么则暴露该catelog service。
- {{range $service}}: 也是标准的{{ range pipeline }}模板语法,$service这个pipeline调用相当于curl localhost:8500/v1/catalog/service/xxxx,即获取某个service xxx的详细信息,包括Address、Port、Tag、Meta等。
接下来,我们在consul-1和consul-2上启动consul-template:
consul-1:
# nohup consul-template -template "/root/consul-install/templates/nginx.conf.template:/etc/nginx/nginx.conf:nginx -s reload" > consul-template.log & 2>&1
consul-2:
# nohup consul-template -template "/root/consul-install/templates/nginx.conf.template:/etc/nginx/nginx.conf:nginx -s reload" > consul-template.log & 2>&1
查看/etc/nginx/nginx.conf,你会发现http server config下面并没有生成任何配置,因为consul集群中还没有满足Tag条件的service(包含tag “http”)。现在我们就来在三个node上创建httpfront services。
# docker run --restart=always -d -l "SERVICE_NAME=httpfront" -l "SERVICE_TAGS=http" -P bigwhite/httpfrontservice:v1.0.0
查看生成的nginx.conf:
upstream httpfront {
zone upstream-httpfront 64k;
server 192.168.0.129:32769 max_fails=3 fail_timeout=60 weight=1;
server 192.168.0.130:32768 max_fails=3 fail_timeout=60 weight=1;
server 192.168.0.131:32768 max_fails=3 fail_timeout=60 weight=1;
}
server {
listen 80;
server_name httpfront.tonybai.com;
location / {
proxy_pass http://httpfront;
}
}
测试一下httpfront.tonybai.com(可通过修改/etc/hosts),httpfront service会调用内部服务httpbackend(通过httpbackend.service.dc1.consul:8081访问):
# curl httpfront.tonybai.com
this is httpfrontservice, version: v1.0.0, calling backendservice ok, its resp: [this is httpbackendservice, version: v1.0.0
]
可以在各个节点上查看httpfront的日志:(通过docker logs),你会发现到httpfront.tonybai.com的请求被均衡到了各个节点上的httpfront service上了:
{GET / HTTP/1.0 1 0 map[Connection:[close] User-Agent:[curl/7.47.0] Accept:[*/*]] {} 0 [] true httpfront map[] map[] map[] 192.168.0.129:35184 / 0xc0000524c0}
calling backendservice...
{200 OK 200 HTTP/1.1 1 1 map[Date:[Mon, 10 Sep 2018 08:23:33 GMT] Content-Length:[44] Content-Type:[text/plain; charset=utf-8]] 0xc0000808c0 44 [] false false map[] 0xc000132600 }
this is httpbackendservice, version: v1.0.0
5. 暴露外部tcp服务
我们的微服务可不仅仅有http服务的,还有直接暴露tcp socket服务的。nginx对tcp的支持是通过stream block支持的。在stream block中,我们来为每个要暴露在外面的tcp service生成server block和upstream block,这部分模板内容如下:
stream {
{{- range services -}}
{{$name := .Name}}
{{$service := service .Name}}
{{- if in .Tags "tcp" -}}
upstream {{$name}} {
least_conn;
{{- range $service}}
server {{.Address}}:{{.Port}} max_fails=3 fail_timeout=30s weight=5;
{{ end }}
}
{{end}}
{{end}}
{{- range services -}}
{{$name := .Name}}
{{$nameAndPort := $name | split "-"}}
{{- if in .Tags "tcp" -}}
server {
listen {{ index $nameAndPort 1 }};
proxy_pass {{$name}};
}
{{end}}
{{end}}
}
和之前的http服务模板相比,这里的Tag过滤词换为了“tcp”,并且由于端口具有排他性,这里用”名字-端口”串来作为service的name以及upstream block的标识。用一个例子来演示会更加清晰。由于修改了nginx模板,在演示demo前,需要重启一下各个consul-template。
然后我们在各个节点上启动tcpfront service(注意服务名为tcpfront-9999,9999是tcpfrontservice expose到外部的端口):
# docker run -d --restart=always -l "SERVICE_TAGS=tcp" -l "SERVICE_NAME=tcpfront-9999" -P bigwhite/tcpfrontservice:v1.0.0
启动后,我们查看一下生成的nginx.conf:
stream {
upstream tcpfront-9999 {
least_conn;
server 192.168.0.129:32770 max_fails=3 fail_timeout=30s weight=5;
server 192.168.0.130:32769 max_fails=3 fail_timeout=30s weight=5;
server 192.168.0.131:32769 max_fails=3 fail_timeout=30s weight=5;
}
server {
listen 9999;
proxy_pass tcpfront-9999;
}
}
nginx对外的9999端口对应到集群内的tcpfront服务!这个tcpfront是一个echo服务,我们来测试一下:
# telnet localhost 9999
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
hello
[v1.0.0]2018-09-10 08:56:15.791728641 +0000 UTC m=+531.620462772 [hello
]
tonybai
[v1.0.0]2018-09-10 08:56:17.658482957 +0000 UTC m=+533.487217127 [tonybai
]
基于暴露tcp服务,我们还可以实现将全透传的https服务暴露到外部。所谓全透传的https服务,即ssl证书配置在服务自身,而不是nginx上面。其实现方式与暴露tcp服务相似,这里就不举例了。
五. 小结
以上基于consul+consul-template+registrator+nginx实现了一个基本的微服务服务发现和负载均衡框架,但要应用到生产环境还需一些进一步的考量。
关于服务治理的一些功能,consul 1.2.x版本已经加入了service mesh的support,后续在成熟后可以考虑upgrade consul cluster。
consul-template在v0.19.5中还不支持servicemeta的,但在master版本中已经支持,后续利用新版本的consul-template可以实现功能更为丰富的模板,比如实现灰度发布等。