牛客网刷题-计算机网络
大部分解答为牛客网各位同学的精彩回答,本文只是选择一些互联网常考题目记录备忘。
1.IP地址分类:

2.常见HTTP状态码:

3.HTTP协议的描述:无状态、基于请求与相应

4.同步通信与异步通信哪个传送效率高:同步传送效率高

5.DNS劫持与DDos:
DNS劫持,指用户访问一个被标记的地址时,DNS服务器故意将此地址指向一个错误的IP地址的行为。范例就是收到各种推送广告等网站。
DNS污染,指的是用户访问一个地址,国内的服务器(非DNS)监控到用户访问的已经被标记地址时,服务器伪装成DNS服务器向用户发回错误的地址的行为。比如不能访问Google、YouTube等。

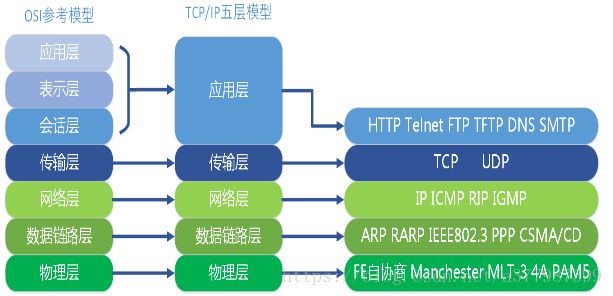
6.OSI七层协议与TCP\IP五层协议:
图片来源:https://blog.csdn.net/lg2lh/article/details/51236912 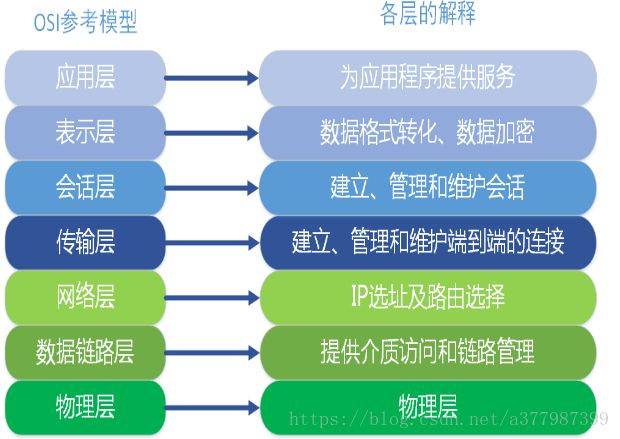
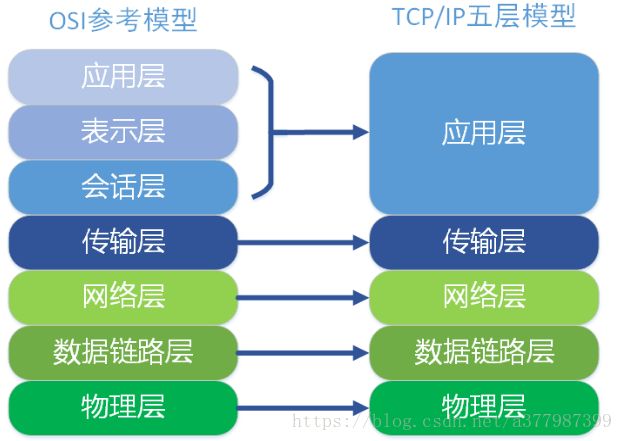
 表示层与会话层没有协议
表示层与会话层没有协议
应用层:
SMTP(Simple Mail Transfe Protocol):即简单邮件传输协议FTP(File Transfer Protocol):文件传输协议
传输层:
IP(Internet Protocol):网络之间互连协议
ICMP(ping命令使用的就是这个协议): Internet control Message Protocol (Internet控制报文协议)用于控制数据报传送中的差错情况。可用于测试主机是否可达(PING命令);
数据链路层:
ARP:(Address Resolution Protocol)(地址解析协议) 根据IP地址查找MAC地址
RARP:(Reverse Address Resolution Protocol)(反向地址解析协议)根据MAC地址查找IP地址
7.网络延迟:指从报文开始进入网络到它开始离开网络之间的时间
往返时延:从发送端发送数据开始,到发送端收到来自接收端的确认(接收端收到数据后便立即发送确认),总共经历的时延。
8.
插几个数据结构的问题
海量数据处理常见的方法有:Hash法,Bit-map法,Bloom filter法,数据库优化法,倒排索引法,外排序法,Trie树,堆,MapReduce法。
Hash法:
常用的哈希函数的构建:
(1)直接寻址法:取关键字或关键字的某个线性函数值为散列地址,h(key)=key或h(key)=a*key+b
时间O(1),空间O(n),不会产生冲突,但因没压缩使关键字集合很大
(2)取模法:h(key)=key mod p。p选择较大的素数效果比较好,一般选取为哈希表的长度
(3)平方取中法:将key进行平方运算,从结果的中间取出若干位(位数与散列地址的位数相同)作为散列地址。
(4)数字分析法、折叠法、随机数法
常用的解决冲突的方法:
(1)开放地址法:发生冲突时,在哈希表中再按照某种方法继续探测其他的存储地址,直到找到空闲的位置为止
Hi(key)=(H(key)+di) mod m (i=1,2,....,k,(k<=m-1))
根据增量di的不同,可分为3种:
1. di=1,2,3,...,m-1,称为线性探测再散列
2. di=12,-12,22,-22,...,-k2(k<=m/2)称为二次探测再散列
3. di=伪随机序列,称为伪随机再散列
(2)链地址法:将地址空间设置成由m个指针组成的一维数组,所有hash为i的数据元素插入到头指针为i的链表中,冲突 时也就是往对应的链表中添加节点。比较适合冲突严重时
(3)再散列法:发生冲突时再使用第二个、第三个哈希函数计算地址,直到无冲突。缺点是计算时间大幅度增肌
(4)建立一个公共溢出区:字面意思,用以存储发生冲突的记录。hash主要用来快速存取
Bit-map法:
基本原理是使用位数组来表示某些元素是否存在。
位图排序的时间复杂度是O(n),比一般的排序都快,但它是以空间换时间
判断集合中是否存在重复时,先扫描一遍得到最大的大小,设置数组全标记为0,再重新扫描没有的改为1,已经出现过1的说明有重复。最坏的情况为O(2N)
Bloom filter法(布隆过滤器):
时间和空间效率高,但牺牲了一点正确率
基本原理是位数组与hash函数联合使用。首先bloom filter包含了m位的位数组,每一位初始化为0,然后定义k个hash函数,每个函数都将集合中的元素映射到位数组的某一位。当向集合中插入一个元素时,根据k个hash函数可以得到位数组的k个位并全置为1。查询时根据该被查询元素的k个hash值对应的位数组是否全为1来判断。
当它判断某个元素不属于这个集合时,该元素一定不属于该集合。当它判断某个元素属于这个集合时,该元素不一定属于这个集合。(因为在插入其他元素时可能会将该元素需要的位置为1)
数据库优化法:
使用好的数据库管理工具、数据分区、索引、缓存、加大虚存、分批处理、使用临时表和中间表、优化查询语句、使用视图、使用存储过程、用排序来取代非顺序存取、使用采样数据进行数据挖掘
倒排索引法:
按照关键字建立的索引
外排序法:
待排序数量多,内存中不能一次处理,必须把它们以文件的形式存放于外存,然后交换分批进行处理。一般采样归并排序。
会消耗大量的IO,效率低
Trie树:
又称为字典树或键树或单词查找树。其原理是利用字符串公共前缀来降低时空开销,即以空间换时间,从而提高效率。
优点是最大限度地减少无谓的字符串比较,查询效率比哈希表高
Trie树一般具有以下3个基本特性:
(1)根节点不包含字符,除根节点外每一节点都只包含一个字符
(2)从根节点到某一结点,路径上经过的字符连接起来,为该节点对应的字符串
(3)每个节点的所有子节点包含的字符串都不相同
堆:没啥说的
TopK问题
(1)直接快速排序:内存够,直接暴力计算,快速排序选出K个
(2)局部淘汰:设K大小的容器,然后用剩余的数字与容器内的最小的数字进行比较,修改后每次都更新最小的数字。
时间O(n+m2),m为容器大小
(3)分治法:比如1亿个数找最大的10000个。将数据分为100份,每份100万个数据。在每份数据中找到最大的10000个数。对每份数据,快排分为2堆,大堆个数大于10000则继续对大堆快排。大堆个数小于10000则对小堆快排找10000-大堆个数个数字。递归以上过程。
(4)Hash法:如果1亿个数字中很多重复,先通过hash能去掉很多数字,再用其他计算方法。
(5)最小/大堆:类似于局部淘汰,使用的数据结构是堆。建堆O(mlogm),m为k的大小。算法时间复杂的O(nlogm)