字符串系列——KMP、AC自动机、回文自动机
文章目录
- KMP
- code
- 例题
- 题解
- code
- AC自动机
- code
- 例题
- 题解
- code
- 回文自动机
- 例题
- 题解
- code
- 参考资料
个人感觉字符串系列是比较蛋疼的算法(相对于我来说)。。。
KMP
给出匹配串和模式串,求模式串在匹配串中出现的位置。
设匹配串长度为n,模式串长度为m。
显然暴力的时间复杂度是 O ( n m ) O(nm) O(nm)
但是想想可以发现,每次匹配时一旦失配所有的相同信息全部丢掉。
其中绿色部分是已匹配部分,红色则是失配部分
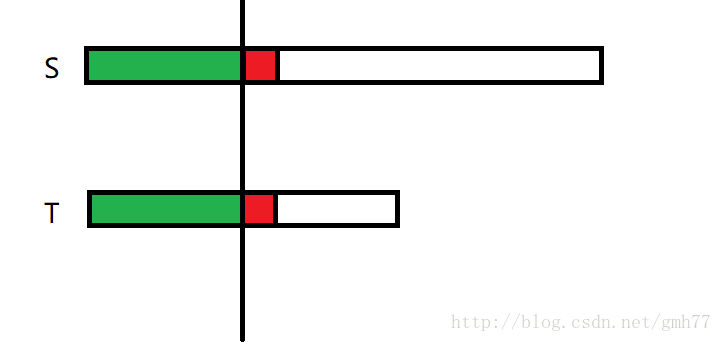
我们假设四块蓝色部分都相同
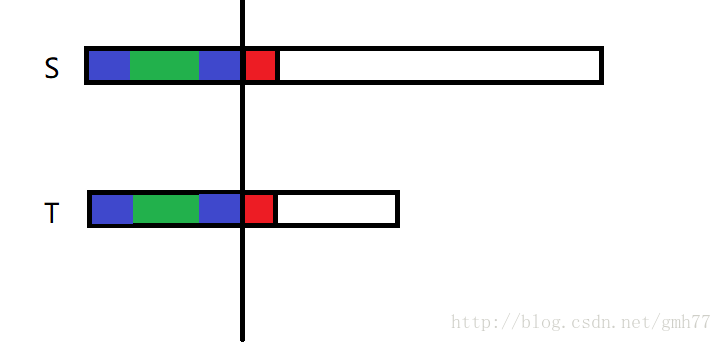
那么可以直接这样匹配

实际上就是从这里开始
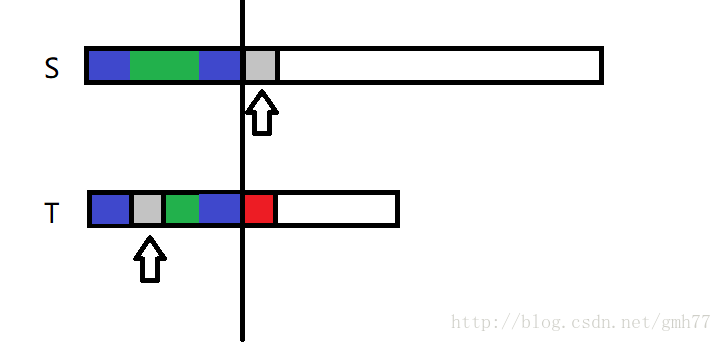
至于预处理前后段相同部分,其实类似上面,只不过是自己匹配自己
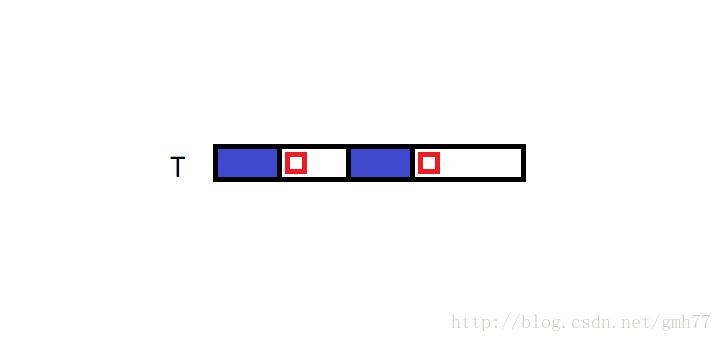
如果失配就不断迭代,具体不细述因为太水
时间复杂度 O ( n + m ) O(n+m) O(n+m)
code
# include 例题
JZOJ5096. 【GDOI2017 day1】房屋购置
Description
涛涛最近准备要结婚了,但这在这之前他需要买套房子。买房子的确是人生大事哟,所以涛涛要好好斟酌。
于是他去房屋中介网上爬到了各种房子的数据,并得到了这些房子的特征,但是现在有一个问题感到很困惑, 但他知道你编程贼 6,所以希望你能帮帮他。
现在有 N 幢房子,每幢房子用一个字符串 si 来描述。但同样的房子不同的开发商会用不同的词汇来描述。
某些字符串存在缩写,例如 swimmingpool 可以简写为 pool 。
现在有 M 条特征的简写规则,每条规则包含两个字符串 ai , bi , 表示将所有子串中的 ai 替换成 bi。
一个字符串可能会被同一条规则匹配多次,优先替换最左边的,且新生成的字符串会不会被重新用于该规则 的匹配。不同的规则之间按照严格的顺序关系执行 (详见样例)。
现在你需要对已有的 N 条字符串通过 M 条有顺序的替换规则进行缩写。
Input
第一行有两个正整数 N,M,代表 N 幢房子,和 M 条替换规则。
接下来 N 行,每行一个字符串 si
接下来 M 行,每行两个字符串 ai , bi,中间用空格隔开。
保证所有输入的字符串只会出现小写字母。
Output
输出 N 行每行一个字符串,代表特征替换后的字符串。
Sample Input
Sample Input1:
1 1
aaaaaaa
aaa ba
Sample Input2:
1 1
ababababc
aba a
Sample Input3:
3 3
swimmingswimmingpool
catallow
dogallow
cat pet
dog pet
swimmingpool pool
Sample Input4:
2 3
aaaabbb
bbbbaaa
aaaa cc
cbbb a
bbbb a
Sample Output
Sample Output1:
babaa
Sample Output2:
ababc
Sample Output3:
swimmingpool
petallow
petallow
Sample Output4:
ca
aaaa
Data Constraint
20% 的数据:1 ≤ |si |, |ai |, |bi | ≤ 100 (|s| 表示字符串 s 的长度)
50% 的数据:1 ≤ |si |, |ai |, |bi | ≤ 30000
100% 的数据:1 ≤ |si |, |ai |, |bi | ≤ 100000, 1 ≤ N, M ≤ 20, |ai | ≥ |bi |。
题解
直接搞就行了。。。
code
由于是N久前Pascal写的,所以可(wu)能(bi)不优美
var
a:array[1..20,0..200000] of longint;
b:array[1..20,0..200000] of longint;
s1,s2:array[0..200000] of longint;
next:array[0..200000] of longint;
n,m,i,j,k,l,len,ii,last:longint;
bz,bz2:boolean;
ch:char;
begin
assign(Input,'house.in'); reset(Input);
assign(Output,'house.out'); rewrite(Output);
readln(n,m);
for i:=1 to n do
begin
read(ch);
while ch in['a'..'z'] do
begin
inc(a[i,0]);
a[i,a[i,0]]:=ord(ch);
read(ch);
end;
readln;
end;
for i:=1 to m do
begin
s1[0]:=0;
s2[0]:=0;
read(ch);
while ch<>' ' do
begin
inc(s1[0]);
s1[s1[0]]:=ord(ch);
read(ch);
end;
read(ch);
while ch in['a'..'z'] do
begin
inc(s2[0]);
s2[s2[0]]:=ord(ch);
read(ch);
end;
readln;
k:=0;
for j:=2 to s1[0] do
begin
while (k>0) and (s1[k+1]<>s1[j]) do
k:=next[k];
if s1[k+1]=s1[j] then
inc(k);
next[j]:=k;
end;
for k:=1 to n do
begin
l:=0;
len:=a[k,0];
a[k,0]:=0;
while l<=len do
begin
bz:=false;
bz2:=false;
last:=l;
j:=0;
while (j<s1[0]) and (l<=len) do
begin
inc(l);
while (j>0) and (a[k,l]<>s1[j+1]) do
j:=next[j];
if a[k,l]=s1[j+1] then
inc(j);
end;
if j<s1[0] then
break;
j:=next[j];
for ii:=last+1 to l-s1[0] do
begin
inc(a[k,0]);
a[k,a[k,0]]:=a[k,ii];
end;
for ii:=1 to s2[0] do
begin
inc(a[k,0]);
a[k,a[k,0]]:=s2[ii];
end;
end;
if last<len then
for l:=last+1 to len do
begin
inc(a[k,0]);
a[k,a[k,0]]:=a[k,l];
end;
end;
end;
for i:=1 to n do
begin
for j:=1 to a[i,0] do
write(chr(a[i,j]));
writeln;
end;
close(Input); close(Output);
end.
AC自动机
全称是Aho-Corasick
可以支持多模式串匹配(相比之下,KMP只能支持单模式串匹配)
思想类似在trie上建KMP
(不懂trie可以自己去找资料或脑补)
AC自动机中最重要的思想就是fail指针。
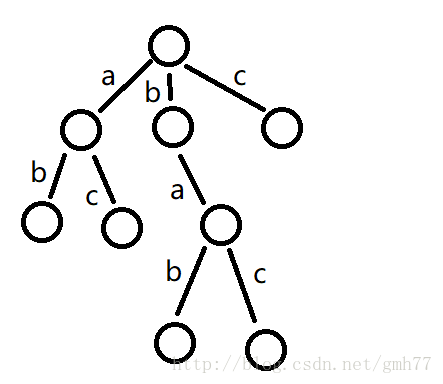
定义fail[x]=y,则满足y节点是x节点的最长后缀
比如"bac"是"aba bac"的后缀。
特殊的,如果x节点是根节点的儿子,则将fail[x]设为根节点。
那么上图的fail指针如下图所示
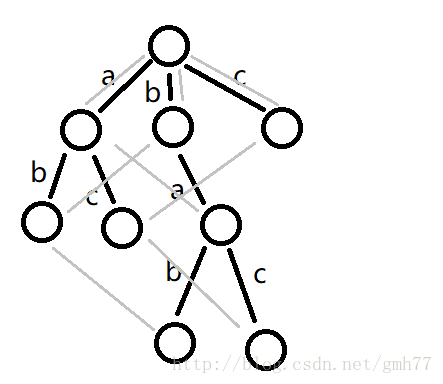
fail指针类似KMP的next数组,从父节点不断往上跳,如果跳到某个节点有和当前结点一样的儿子,就把fail设为那个儿子。
所以AC自动机=trie+KMP
摘自http://blog.csdn.net/a_crazy_czy/article/details/48029883
设匹配串长度为n,模式串共m个,第i个记为si。
可以证明AC自动机时间复杂度为O(n+∑length(si))
code
# include 例题
JZOJ3472. 【NOIP2013模拟联考8】匹配(match)
Description
给定k个字符串以及长度为n的母串可选字母的集合,问母串要完整出现给定的k个字符串的方案数,答案模1000000007,字符仅包含小写字母。
Input
第一行两个整数n、k,表示字符串的长度和给定字符串的个数。
接下来k行每行一个字符串。
接下来一行1个整数m表示可选字母集合内元素个数。
接下来一行给出一个长为m的字符串,表示字母的集合(可能有重复)。
Output
一个整数ans,表示方案数。
Sample Input
3 2
cr
rh
4
acrh
Sample Output
1
【样例解释】
只有crh符合。
Data Constraint
30%的数据n<=10,m<=3。
60%的数据n<=40。
另有10%的数据k=0。
另有10%的数据m=1。
100%的数据n<=100,m<=10,k<=8,给定字符串长度<=30。
题解
状压Dp+AC自动机
设f[i][j][k]表示当前枚举到字符串第i位,在AC自动机上位置为j,匹配成功的字符串状态为k(状压)
然后建好AC自动机后搞一遍就行了。
code
# include 回文自动机
用来处理回文子串的问题。
1、求回文子串的种类。
2、求每种回文子串出现次数。
3、求匹配串的前缀中的回文子串。
4、求以下标i为结尾的回文子串个数。
思想跟AC自动机类似,每个节点都代表一个回文串
则每个节点都可以向两边同时加一个字符来变成新的回文串。
定义fail[x]=y表示x的最长后缀位置是y
因为回文串分奇偶性,所以定义两个根
偶数根长度为0,奇数根长度为**-1**(没错就是-1,因为可以通过扩展得到长度为1的串)
然后偶数根的fail设为奇数根。
每次从当前节点(初始设为偶数根)扩展时,沿着fail指针一直跳,直到发现某个串可以扩展就扩展。
如果扩展了节点,那么新节点的cnt(计数)设为1,否则+1
每次扩展长度+2
如果扩展了一个新节点,怎样求它的fail指针?
比如说现在找到了一个可以扩展的节点
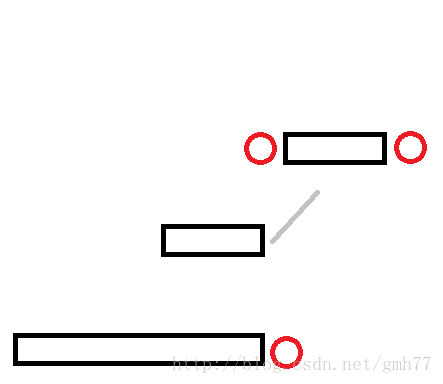
那么它的后缀一定是这样的
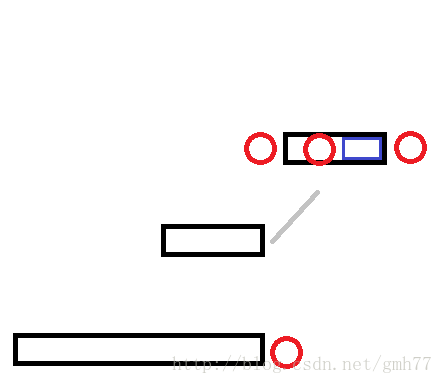
根据回文的性质,蓝色部分一定是一个回文串
所以只需要沿着fail指针继续向上跳来找一个能扩展的点
能扩展的点不仅是要有相应的儿子,还要能在当前情况下扩展
(就是上面这点坑了我一个小时)
找到后把fail指针设为其儿子。
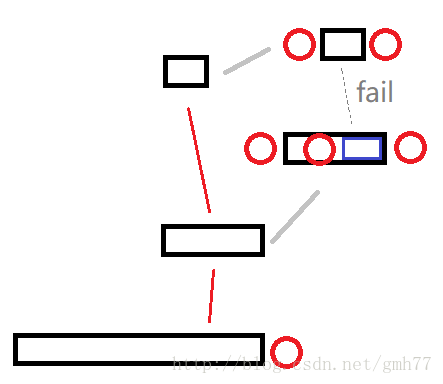
(如果没有找到就把fail设为偶数根)
还有一点,因为每个长串包含了短串,所以最后要从后往前沿着fail来累加cnt。
其实理解了AC自动机后学这个并不难
时间复杂度 O ( ∣ S ∣ ) O(|S|) O(∣S∣)即 O ( n ) O(n) O(n)
然而我并不会证
例题
JZOJ3654. 【APIO2014】回文串
也就是本算法的出处
(补充一下,回文树是由战斗民族的大佬于2014年发明的)
Description
考虑一个只包含小写拉丁字母的符串 s。我们定义 s的一个子串 t的“出现值”为 t在 s中的出现次数乘以t的长度。 请你求出s的所有 回文子串中的最大出现值。
Input
输入只有一行,为一个只包含小写字母 (a−z) 的非空字符串 s。
Output
输出 一个整数,为 所有 回文子串 的最大 出现 值。
Sample Input
输入1:
abacaba
输入2:
www
Sample Output
输出1:
7
输出2:
4
题解
裸题瞎搞。
code
# include 参考资料
Palindromic Tree——回文树【处理一类回文串问题的强力工具】
论如何优雅的处理回文串 - 回文自动机详解.
回文树介绍(Palindromic Tree)