Halcon运算速度优化方法简述
本文翻译并总结自Halcon 官方说明文档,详情请查看Halcon帮助文档,如下图所示:
get_operator_info.hdev例程展示了如何查看哪些算子支持GPU加速与并行加速等信息
-
GPU加速
详情可查看compute_devices.hdev例程
-
并行运算加速
1、数据并行化
数据并行化的具体方式是实现了算子自动并行化,即AOP,Halcon算子之所以拥有极高的执行效率就是因为默认开启了AOP。数据并行化具体分为以下四种:
(1)tuple level (2)channel level (3)domain level (4)internal data level
下图展示了AOP应用在中值滤波上的具体过程:
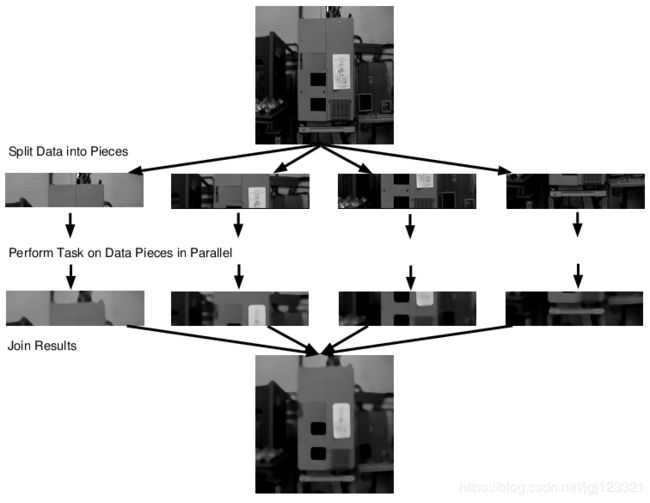
(1)将输入数据分割成几个大小大致相同的数据块;
(2)由不同的线程分别处理每个数据块;
(3)在最后一个线程完成后,将所有线程的结果合并到一起;
simulate_aop.hdev例程展示了如何手动实现数据并行化,并与AOP对比。对比结果显示,其效果不如AOP,但是比顺序处理快得多。
#设置是否启用AOP,默认为true
set_system ('parallelize_operators', 'true')
#设置启用AOP时所用的线程数量
set_system ('thread_num', Threads)2、任务并行化
Halcon通过线程安全和可重入来支持并行编程。不同的线程可以同时调用Halcon算子,而不必等待。然而,并非所有算子都是完全可重入的,可分为以下6个可重入级别:
reentrant:如果一个运算符可以由多个线程同时调用,而不依赖于它所调用的数据,则它是完全可重入的
local:标记为本地的运算符只能从实例化相应对象的线程调用
single write multiple read:只有当不同的调用线程在不同的数据上工作时,才应该同时调用某组运算符
mutually exclusive:有些算子不能被多个线程同时调用,但可以与其他算子并行执行
exclusive:Halcon独占执行一组算子,在执行此类算子时,所有其他线程都不能调用另一个Halcon算子。
independent:一组算子独立于其他算子(甚至是独占算子)执行
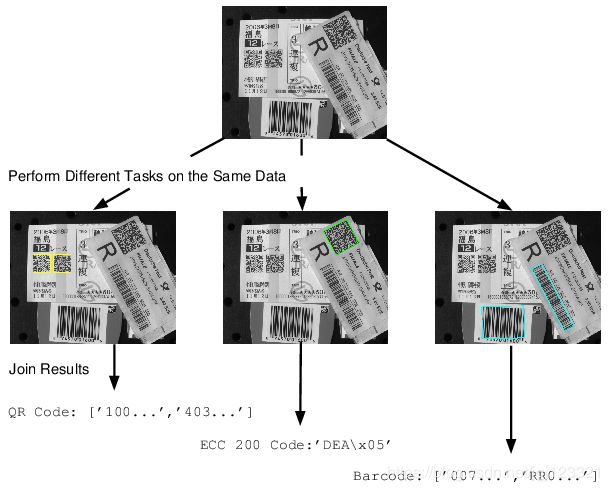
par_start.hdev例程展示了如何并行的识别同一张图片上不同类型的条码,如下图所示:
-
并行编程的重要概念
Thread:线程是独立于主程序并与其并行运行的过程。它与其他线程共享全局变量和资源,并独占本地变量和资源
Thread Safe:当一个线程访问或操作共享数据和资源的方式能够保证在任意多线程环境中产生可预测和可复制的结果时,它被认 为是线程安全的。
Reentrant:如果一个运算符可以由多个线程同时调用,而不依赖于它所调用的数据,则它是完全可重入的
Exclusive:如果保证数据、资源或代码只能由一个线程同时访问或执行,则以独占方式访问或执行。
Message Queue:消息队列是线程安全的FIFO(“先进先出”)列表,用于在线程之间传递数据
Producer Consumer Model:在生产者-消费者模型中,一些线程(即生产者)向其他线程(即消费者)提供数据。
Data Parallelization:数据并行化描述了一种并行化概念,它将数据分离为独立的数据组,并同时处理这些数据组。
Task Parallelization:任务并行化描述了一个并行化概念,它将问题划分为几个独立的子任务,并同时执行这些子任务。
AOP (automatic operator parallelization):AOP是一种数据并行化的类型,默认情况下用于内部的选择/区分算子。