机器学习算法(12)之集成学习之模型融合
前言:集成学习(Ensemble Learning),广泛用于分类和回归任务。它最初的思想很简单:使用一些(不同的)方法改变原始训练样本的分布,从而构建多个不同的分类器,并将这些分类器线性组合得到一个更强大的分类器,来做最后的决策。也就是常说的“三个臭皮匠顶个诸葛亮”的想法。
集成学习的理论基础来自于Kearns和Valiant提出的基于PAC(probably approximately correct)的可学习性理论 ,PAC 定义了学习算法的强弱:
- 弱学习算法:识别错误率小于1/2(即准确率仅比随机猜测略高的算法)
- 强学习算法:识别准确率很高并能在多项式时间内完成的算法
根据这两个概念,后来产生了一个重要的结论:
强可学习与弱可学习是等价的,即:一个概念是强可学习的充要条件是这个概念是弱可学习的。
据此,为了得到一个优秀的强学习模型,我们可以将多个简单的弱学习模型“提升”。
1. 集成学习概述
使用一系列学习器进行学习,并使用某种规则(模型融合方法)把各个学习结果进行整合,从而获得比单个学习器更好的学习效果的一种机器学习方法。如果把单个分类器比作一个决策者的话,集成学习的方法就相当于多个决策者共同进行一项决策。

也就是说,集成学习有两个主要的问题需要解决,第一是如何得到若干个个体学习器,第二是如何选择一种结合策略,将这些个体学习器集合成一个强学习器。
2、集成学习之个体学习器
上一节我们讲到,集成学习的第一个问题就是如何得到若干个个体学习器。这里我们有两种选择。
- 第一种就是所有的个体学习器都是一个种类的,或者说是同质的。比如都是决策树个体学习器,或者都是神经网络个体学习器。
- 第二种是所有的个体学习器不全是一个种类的,或者说是异质的。比如我们有一个分类问题,对训练集采用支持向量机个体学习器,逻辑回归个体学习器和朴素贝叶斯个体学习器来学习,再通过某种结合策略来确定最终的分类强学习器。
目前来说,同质个体学习器的应用是最广泛的,一般我们常说的集成学习的方法都是指的同质个体学习器。而同质个体学习器使用最多的模型是CART决策树和神经网络。同质个体学习器按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,一系列个体学习器基本都需要串行生成,代表算法是boosting系列算法,第二个是个体学习器之间不存在强依赖关系,一系列个体学习器可以并行生成,代表算法是bagging和随机森林(Random Forest)系列算法。下面就分别对这两类算法做一个概括总结。
3、三种常用的集成方法
最常见的一种就是依据集成思想的架构分为 Bagging ,Boosting, Stacking三种。国内,南京大学的周志华教授对集成学习有深入的研究,其在09年发表的一篇概述性论文《Ensemple Learning》对这三种架构做出了明确的定义。
3.1、bagging
首先介绍经典的样本估计方法:Bootstrapping (自助法)
自助法是一种有放回的抽样方法。它是非参数统计中一种重要的通过估计统计量方差进而进行区间估计的统计方法,遵从“在不知道数据总体分布时,对总体分布的最好的猜测便是由数据提供的分布”原则。自助法的要点是:
- 假定观察值就是数据总体
- 由这一假定的总体抽取样本,即再抽样
具体步骤如下:
1.采用重抽样方式从原始样本中抽取一定数量(容量m)的数据,重复抽样m次,得到一个自助样本(注意这种方法抽到的样本有可能会有很多重复的,当然也有没抽到的样本,这里叫袋外样本,其实对应于袋外错误率(oob error,out-of-bag error))。
2.根据得到的自助样本计算特定的统计量。
3.重复上述N次,得到N个自助统计量。
4.根据上述N个自助统计量估计出真实值。
Bagging:基于数据随机重抽样的分类器构建方法。从训练集从进行子抽样组成每个基模型所需要的子训练集,对所有基模型预测的结果进行综合产生最终的预测结果。
它的弱学习器之间没有依赖关系,可以并行生成,我们可以用一张图做一个概括如下:
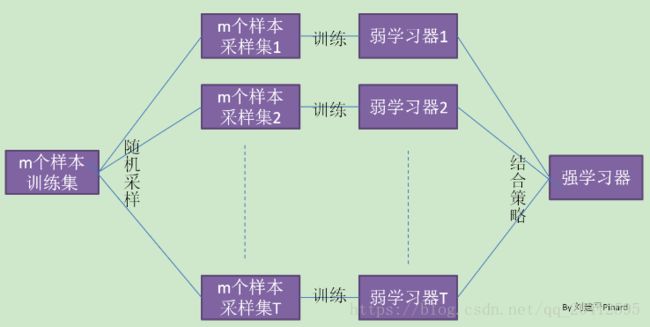
- 通过重复K次的有放回抽样,训练K个子模型(每次随机抽样训练1个模型)
- 对K个模型结果进行Voting/Averaging融合
Bagging融合示例:
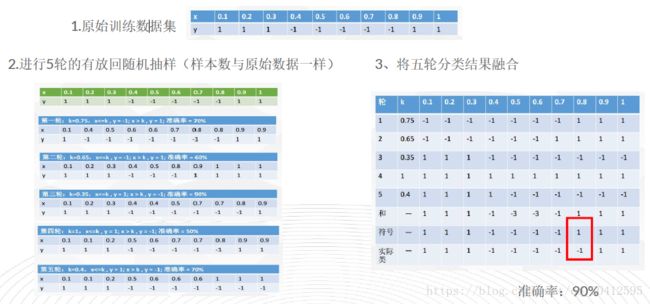
这里的随机采样一般采用的是自助采样法(Bootstap sampling),即对于m个样本的原始训练集,我们每次先随机采集一个样本放入采样集,接着把该样本放回,也就是说下次采样时该样本仍有可能被采集到,这样采集m次,最终可以得到m个样本的采样集,由于是随机采样,这样每次的采样集是和原始训练集不同的,和其他采样集也是不同的,这样得到多个不同的弱学习器。
随机森林是bagging的一个特化进阶版,所谓的特化是因为随机森林的弱学习器都是决策树。所谓的进阶是随机森林在bagging的样本随机采样基础上,又加上了特征的随机选择,其基本思想没有脱离bagging的范畴。bagging和随机森林算法的原理在后面的文章中会专门来讲。
3.2、Boosting
Boosting每一次训练的时候都更加关心上一次分类错误的样例,给这些分类错误的样例更大的权重,下一次训练的目标就是能够更容易辨别出上一次分类错误的样例,最终将多次迭代训练得到的弱分类器进行加权相加得到最终的强分类器


从图中可以看出,Boosting算法的工作机制是首先从训练集用初始权重训练出一个弱学习器1,根据弱学习的学习误差率表现来更新训练样本的权重,使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的弱学习器2中得到更多的重视。然后基于调整权重后的训练集来训练弱学习器2.,如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。
Boosting系列算法里最著名算法主要有AdaBoost算法和提升树(boosting tree)系列算法。提升树系列算法里面应用最广泛的是梯度提升树(Gradient Boosting Tree),当然还有我们比赛的大杀器--XGboost。
3.3、stacking
stacking的讲解
用多种预测值作为特征训练,sklearn中没有现成的库可以调用,这里也不做过多的叙述
4、学习之结合策略
在上面几节里面我们主要关注于学习器,提到了学习器的结合策略但没有细讲,这里就对集成学习的结合策略做一个总结。我们假定得到的T个弱学习器是{![]() }.
}.
4.1、平均法
Averaging:平均法,针对回归问题
对于数值类的回归预测问题,通常使用的结合策略是平均法,也就是说,对于若干个弱学习器的输出进行平均得到最终的预测输出。
1)最简单的平均是算术平均,也就是说最终预测是
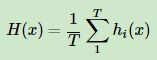
2)另一种是加权平均,每个个体学习器有一个权重ww,则最终预测是
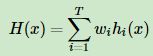

4.2、投票法
Voting:投票法,针对分类问题
对于分类问题的预测,我们通常使用的是投票法。
1)硬投票(hard):
基于分类标签投票,也就是我们常说的少数服从多数。如果不止一个类别获得最高票,则随机选择一个做最终类别。

2)软投票(soft):基于分类标签概率投票
4.3、学习法
上两节的方法都是对弱学习器的结果做平均或者投票,相对比较简单,但是可能学习误差较大。对于学习法,代表方法是stacking,当使用stacking的结合策略时, 我们不是对弱学习器的结果做简单的逻辑处理,而是再加上一层学习器,也就是说,我们将训练集弱学习器的学习结果作为输入,将训练集的输出作为输出,重新训练一个学习器来得到最终结果。

对于不是stacking的方法:
训练集输入->若干弱学习器-->若干弱学习器输出-->平均法投票法得到预测输出。
对于stacking方法:
训练集输入->若干弱学习器1-->若干学习器1输出(所有的输出作为学习器2的输入特征)-->次级学习器2-->学习器2输出即为预测输出。
对于stacking,次级学习器的输入不能理解为原样本的类别输出,而仅仅只是初级学习器的预测输出,这个输出对于次级学习器来说仅仅只是一个特征而已,至于是不是类别什么的并不重要。
从原理上讲,可以理解为初级学习器对原样本的特征进行了梳理,得到了更清晰的特征,方便次级学习器更容易的去学习清晰特征和类别输出的关系。
参考资料:
https://blog.csdn.net/nini_coded/article/details/79341485
https://www.cnblogs.com/pinard/p/6131423.html