Python爬虫练习(1)——调用百度翻译
注:Python版本:3.6.3;编译环境:Pycharm
1.用chrome浏览器打开百度翻译页面,空白处右键点击“检查”。
2.在翻译框中输入文本;点检查窗口中的“clear”清除当前显示。
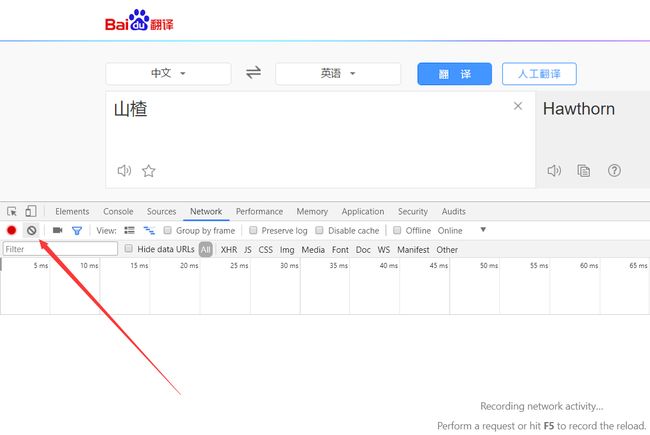
3.点击“翻译”下方出现请求列表。
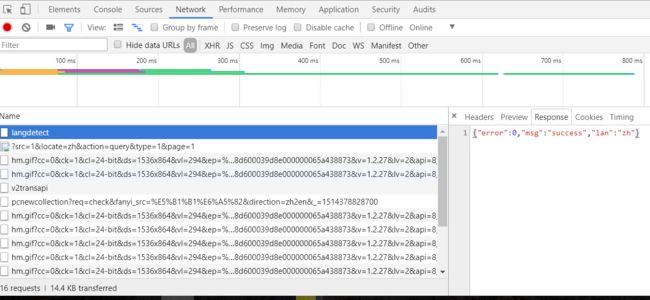
4.左边栏的“langdetect”是语言检测的请求,“v2transapi”是执行翻译的请求;右边栏的“Headers”是该请求的请求头部,“Response”是响应。代码中会用到两个请求中的:
“Headers”->“General”->“Request URL”,
“Headers”->“Request Headers”->“User-Agent” (两个一样)
“Headers”-> ”Form Data“
“Response”
5.用Python中的第三方模块"requests"实现如下:
import requests
import json
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"}
#2个请求的URL地址
langdetect_url = "http://fanyi.baidu.com/langdetect"
transapi_url = "http://fanyi.baidu.com/v2transapi"
while True:
input_word = input("Translate input: ")
langdetect_data = {"query":input_word}
langdetect_resp = requests.post(langdetect_url, headers=headers, data=langdetect_data)
langdetect_dict = json.loads(langdetect_resp.content.decode())
# print(langdetect_dict)
langdetect = langdetect_dict["lan"]
if langdetect == "en": #检测到输入为英文,翻译成中文
langtransto = "zh"
else:
langtransto = "en" #输入为中文则翻译成英文
transapi_data = {"from":langdetect,
"to":langtransto,
"query":input_word,
"transtype":"translang",
"simple_means_flag":3,
"sign":484403.231170,
"token":"9b9736e837ab4fd40c9b0ee85b7fa213"}
#sign和token不同的用户可能不一样
transapi_reap = requests.post(transapi_url, headers=headers, data=transapi_data)
transapi_dict = json.loads(transapi_reap.content.decode())
#json.loads()函数可以将网页的响应转化为字典格式
#(如果响应的格式是像字典一样的字符串,即json字符串,的话)
trans_str = transapi_dict["trans_result"]["data"][0]["dst"]
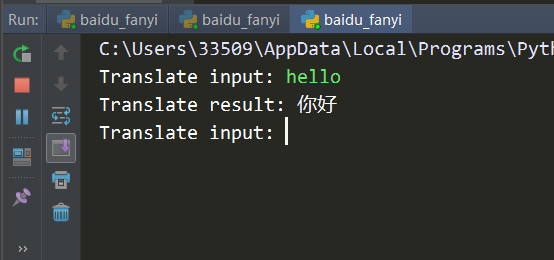
5.Pycharm中的执行结果:
知乎:@陈小白233
公众号:一本正经的搬砖日常